
第2章 模型评估与选择
2.1 经验误差和过拟合
最终目的:找到最好的学习器。为达到这个目的,学习器应该从训练样本中尽可能学出适用于所有潜在样本的“普遍规律”。
- 错误率:分类错误的样本数占总样本数的比例称为错误率。
- 精度:精度 = 1 - 错误率。
- 误差:学习期的实际预测输出与样本真实输出之间的差异称为 “ 误差 ”。
- 训练误差 / 经验误差:学习器在训练集上的误差称为 “ 训练误差 ” 或 “ 经验误差 ” 。
- 泛化误差:学习器在新样本上的误差称为 “ 泛化误差 ” 。
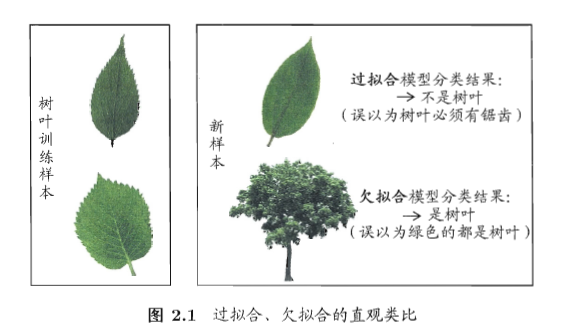
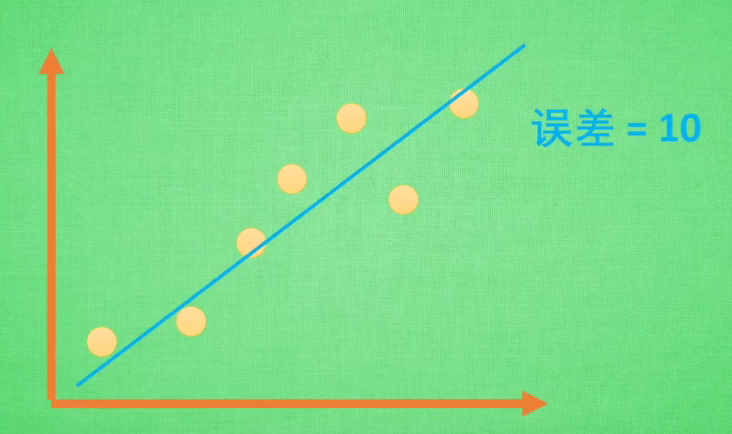
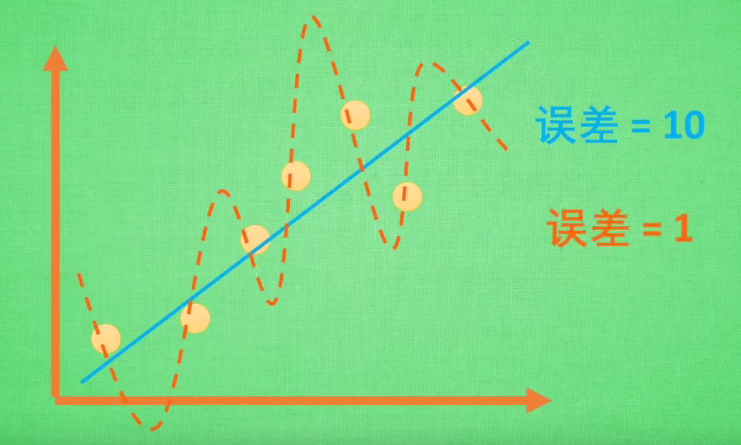
- 过拟合:当学习器把训练样本学得 “ 太好了 “ 的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本会具有的一般性质,这样就会导致泛化性能下降,这种现象在机器学习中称为过拟合。
- 欠拟合:与过拟合相对。
过拟合是机器学习面临的关键障碍。


选择哪个一模型呢?
- 选择泛化误差最小的那个? ——最理想的,但是泛化误差无法直接获得。
- 选择训练误差最小的?——存在过拟合现象,不适合作为标准。
2.2 评估方法
目的:找出泛化误差最小的那个。
- 测试集:测试学习器对新样本的判别能力。
- 模拟卷
- 测试误差 近似等于 泛化误差
- 模拟卷的成绩近似于真题成绩
- 对测试样本的要求:
- 测试集应该尽可能与训练集互斥,即测试样本尽量不在训练集中出现。
我们只有一个数据集,既要训练,又要测试怎么办?
- 通过适当的处理把数据集分为 训练集S 和测试集T。
2.2.1 留出法
共4车共1000个西瓜,最终要产生一个能检验好瓜的机器学习程序。
- 把700个西瓜当做训练集S,300个当做测试集T。
要求:
- S∪T = D , S ∩ T = ∅
- 训练 / 测试集的划分要尽可能的保持数据分布的一致性。
- 多次评估取平均。
问题:
- 训练集S 和测试集T 怎么划分合理?
- S 多 T 少:结果更接近于直接训练全部数据集的结果,评估结果可能不够稳定准确。
- S 少 T 多:训练集与直接训练全部数据集的结果差别更大了,从而降低了评估结果的保真性。
- 这个问题没有完美的解决办法。因此常见的做法是将 2/3 ~ 4/5 的样本用于训练,剩余样本用于测试。
2.2.2 交叉验证法
共4车共1000个西瓜,最终要产生一个能检验好瓜的机器学习程序。
- 1000个西瓜平均分成10组,每次分别1组作为测试集,9组作训练集,一共可以进行10次,最终把10次结果取平均值即最终结果。
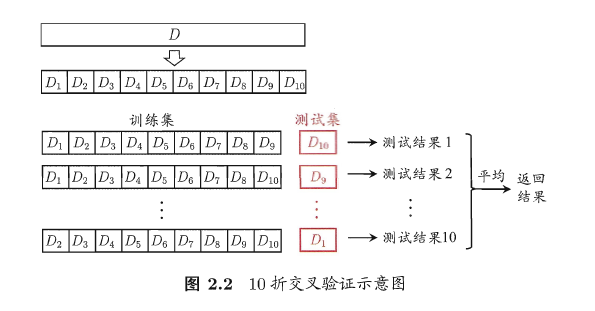
要求:
- 保证每个子集数据分布的一致性。
- 多次评估取平均。
- 特殊的:留一法
- 优点:评估结果往往被认为比较准确
- 缺点:数据集比较大时,计算开销可能是难以忍受的。
2.2.3 自助法
共4车共1000个西瓜,最终要产生一个能检验好瓜的机器学习程序。
玄幻:从1000个西瓜的黑箱中,每次随机的有放回的取出并复制一个西瓜。取1000次,得到的集合D‘ 作为训练集,原1000个西瓜中未被取过的瓜组成的数据集D作为测试集。
自助采样的定义:给定包含 m 个样本的数据集 D,我们对它进行采样产生的数据集 D’ :每次随机从 D 中挑选一个样本,将其拷贝放入 D‘ 中,然后再将该样本放回初始数据集 D 中,使得该样本在下次采样时仍有可能被采到;重复这个过程 m 次,我们就得到了包含 m 个样本的数据集 D’,这就是自助采样的结果。
- 在初始数据集D中, m 次采样中始终不被采到的概率是 36.8% ,将 D’ 作为训练集,将 D \ D‘ 用作测试集。
36.8% 的由来:

- 优点:自助法在数据集较小、难以有效划分训练/测试集时很有用
- 缺点:由于产生的数据集改变了初始数据集的分布,会引入估计偏差,因此初始数据量足够时,留出法和交叉验证发更常用一些。
2.2.4 调参与最终模型
- 调参:大多数算法都有参数需要设定,参数配置不同,学得模型的性能往往有显著茶币诶,因此在进行模型评估与选择时,除了要对适用学习算法进行选择,还要对算法参数进行设定,“参数调节”即“调参”。
- 注意:把每一个参数都测试一遍是不现实的因此车行用的做法是,对每个参数都选定一个参数范围和步长
- 例如:在[0, 0.2]范围内以0.05为步长,则实际要评估的参数值有5个,最终是从这5个值中选定值。
- 假设有3个参数,每个参数值有5个,则共有 5^3 = 125个模型需要考察,因此参数调的好不好往往对最终模型性能有关键性的影响
- 注意:把每一个参数都测试一遍是不现实的因此车行用的做法是,对每个参数都选定一个参数范围和步长
- 最终模型:分训练集测试集只是为了选定算法和参数配置,所以把 m 个样本全部训练过的学习器才是最终提交给用户的模型。
- 注意:我们实际使用中遇到的数据叫做真正的测试集,而在模型评估和选择中用于评估测试的数据集称为“验证集”。
