
决策树(Decision Tree)是一种非参数的监督式学习方法,它能从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回归问题。
- 模块 sklearn.tree:
| tree.DecisionTreeClassifier | 分类树 |
|---|---|
| tree.DecisionTreeRegressor | 回归树 |
| tree.export_graphviz | 将生成的决策树导出为DOT格式,画图专用 |
| tree.ExtraTreeClassifier | 高随机版本的分类树 |
| tree.ExtraTreeRegressor | 高随机版本的回归树 |
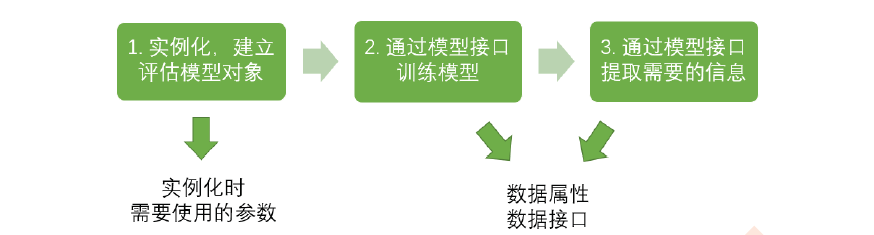
- sklearn 的基本建模流程:
一、分类树
- 在上面的基本流程下,分类树对应的代码是:
1 | from sklearn import tree # 导入需要的模块 |
1.1 参数
1.1.1 重要参数
| 参数名称 | 描述 | 使用案例 |
|---|---|---|
| criterion | 规定纯度的计算方法。有两种选择 entropy和ginientropy:信息熵——代表父节点与子节点的纯度之差gini:反应了从数据集中随机抽取两个样本,其类别标记不一致的概率选择:效果基本相同,信息熵对纯度更加敏感,因此高位数据或噪音多时 gini 更适合 |
clf = tree.DecisionTreeClassifier(criterion=”entropy”) clf = tree.DecisionTreeClassifier(criterion=”gini”) |
| random_state | 设置分枝中的随机模式的参数,默认None,高维数据随机性会更加明显,每次结果都一样,只要在该参数后加上任意整数,即可让结果稳定下来。数字并没有具体含义。 |
clf = tree.DecisionTreeClassifier(random_state = 30) |
| splitter | 用来控制决策树中的随机选项,有两种选择best和randombest:虽然会在分枝时随机,但是还是会优先选择更重要的特征进行分枝random:决策树的分枝会更加随机 |
clf = tree.DecisionTreeClassifier(splitter=”best”) clf = tree.DecisionTreeClassifier(splitter=”random”) |
1.1.2 剪枝参数
| 参数名称 | 描述 | 使用案例 |
|---|---|---|
| max_depth | 限制树的最大深度,超过设定深度的树枝全部砍掉 | clf = tree.DecisionTreeClassifier(max_depth=3) |
| min_samples_leaf | 一个节点在分之后的子节点必须包含至少min_samples_leaf个训练样本,否则分枝就不会发生。一般搭配 max_depth使用,在回归树中有神奇效果,可以让模型变得更加平滑。 |
clf = tree.DecisionTreeClassifier(min_samples_leaf=2) |
| min_samples_split | 一个节点必须包至少min_samples_split个训练样本,这个节点才允许被分枝 |
clf = tree.DecisionTreeClassifier(min_samples_split=20) |
| max_feature | 限制分支时考虑的特征个数,超过限制个数的特征都会被舍弃,来限制高维数据的过拟合,比较暴力 | clf = tree.DecisionTreeClassifier(max_feature=4) |
| min_impurity_decrease | 限制信息增益的大小 | clf = tree.DecisionTreeClassifier(mini_impurity_decrease=10) |
1.2 属性
feature_importances_
- 描述:查看各个特性对模型的重要程度

1.3 接口
| 接口名称 | 描述 | 使用案例 |
|---|---|---|
| apply | 返回每个测试样本所在的叶子节点的索引 | clf.apply(Xtest) |
| predict | 返回每个测试样本的分类/回归结果 | clf.predict(Xtest) |
二、回归树
1 | from sklearn.tree import DecisionTreeRegressor |
注意:因为拟合的需要,X 需要是二维,y 需要是一维,降维函数 np的ravel(),升维函数 np 的newaxis
三、经典案例:泰坦尼克号生存者预测
1 | # 导入所需要的库 |

