
第4章 决策树
决策树学习的目的:是为了产生一棵泛化能力强,即处理未见示例能力强的决策树。

4.2 划分选择
4.2.1 信息增益
- 意义:一般而言,信息增益越大,则意味着使用属性 a 来进行划分所获得的 ”纯度提升“ 越大。
- 选择:选择信息增益最大的为划分属性。若及中枢性均取得最大信息增益,那么任选其一即可。
4.2.2 增益率
- 产生原因:信息增益准则对取值数目较多的属性有所偏好,为了减少这种偏好带来的不利影响,产生了增益率。
- 意义:增益率准则对可取数值数目较少的属性有所偏好。
- 使用方法:并不是直接选择增益率或信息增益准则,而是使用一个启发式[Quinlan, 1993]:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
4.2.3 基尼指数
- 意义:直观来说,Gini(D) 反映了从数据集 D 中随机抽取两个样本,其类别标记不一致的概率,因此,Gini(D)越小,则数据集 D 的纯度越高。
- 选择:在候选属性集合中,选择那个使得划分后基尼指数最小的属性作为最优划分属性。
4.4 连续与缺失值
4.4.1 连续值处理
连续属性离散化:eg:二分法
具体做法:
- ① 将数值从小到大排序
- ② 基于划分点 t 将子集分为 【D小于等于】 【D大于】
- 共有 n - 1 个候选划分点 t 可取。
- 注意:对于相邻属性值来说,取中间任何一个值对结果不会有影响,因此我们这里取中位点。
- ③ 选出最大的信息增益的划分点。
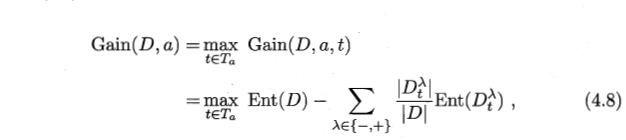
例:
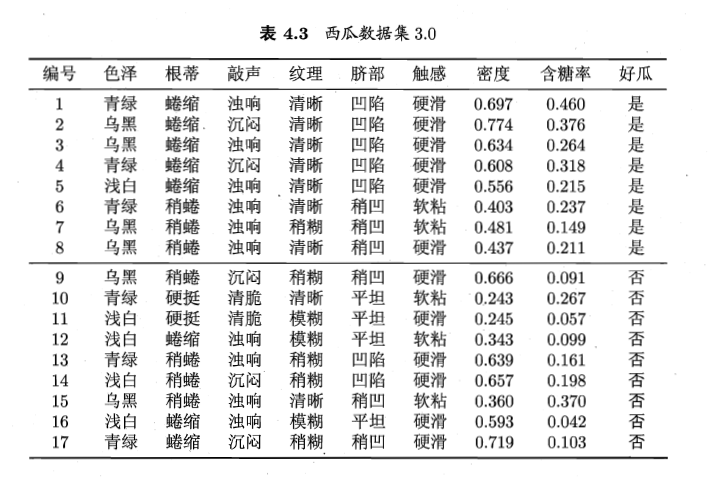
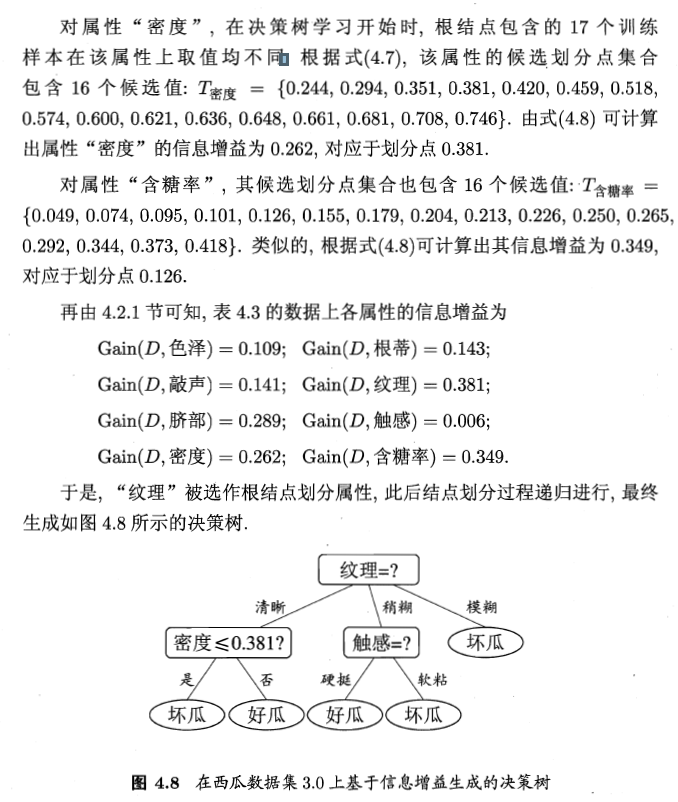
注意:若当前结点划分属性为连续属性,该属性还可作为其后代结点的划分属性。【例:在父节点上使用了 “密度 ≤ 0.381”,不会禁止在子节点上使用 “密度 ≤ 0.294”】
4.4.2 缺失值处理

- 例:




