
深度学习 | 机器学习
- Pytorch 为什么看起来更加复杂?
非结构、海量数据才能看到优势。类的频繁使用其实也是为了能够更加灵活的创建不同类型的神经网络模型。
一、回归类数据集创建方法
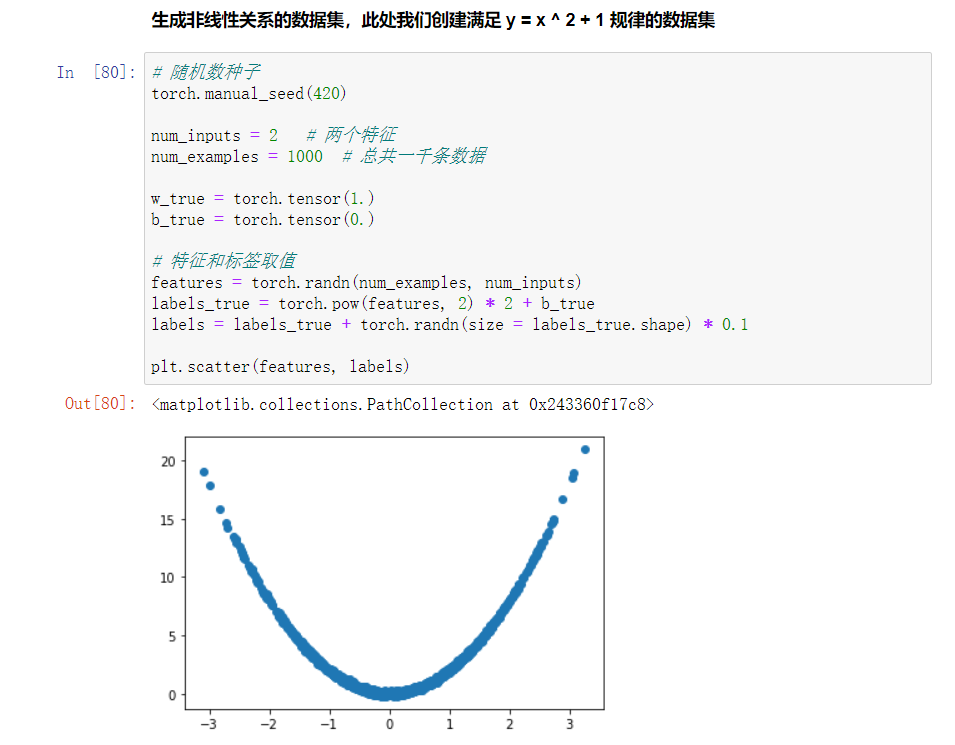
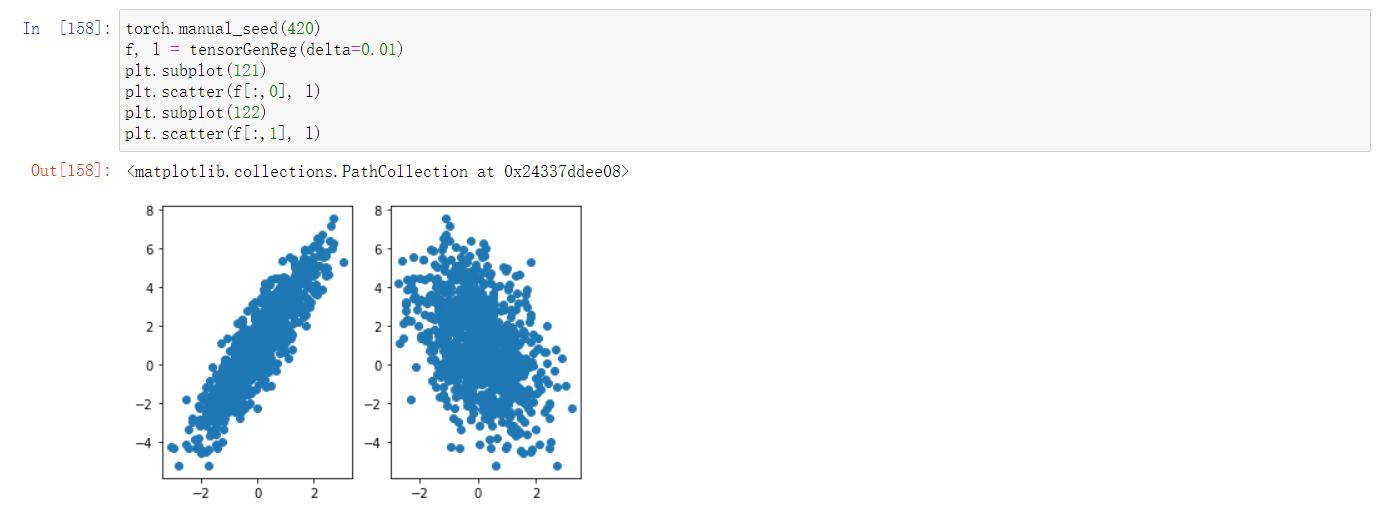
回归类模型的数据,特征和标签都是连续型数值。

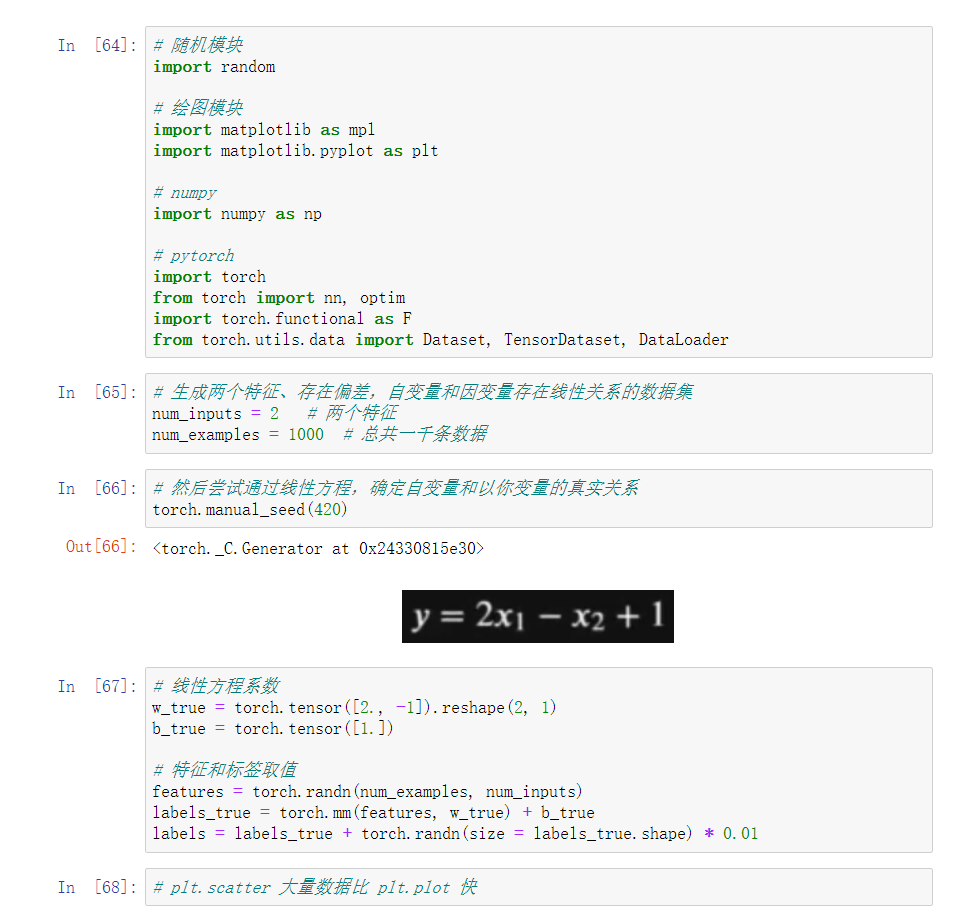
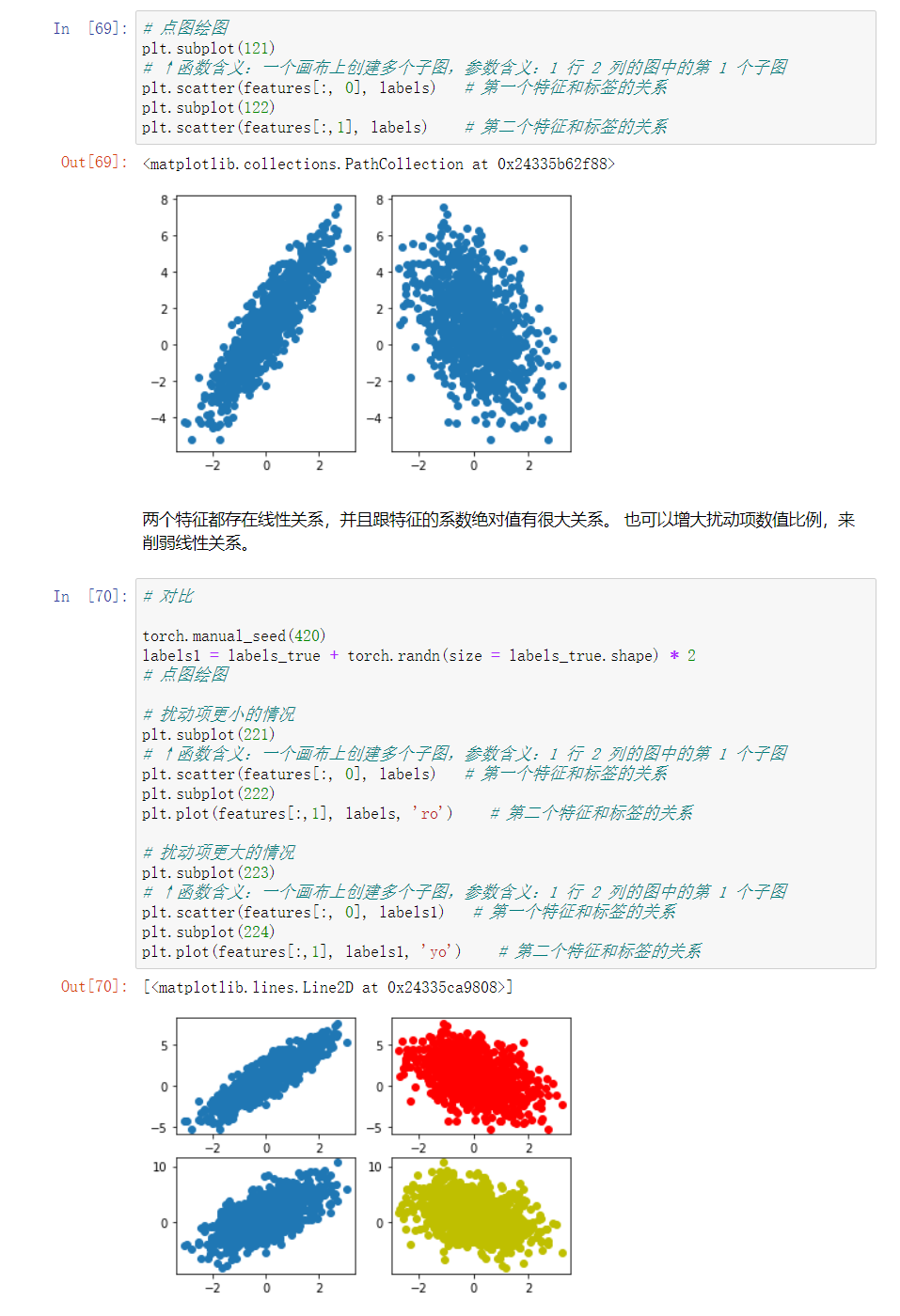
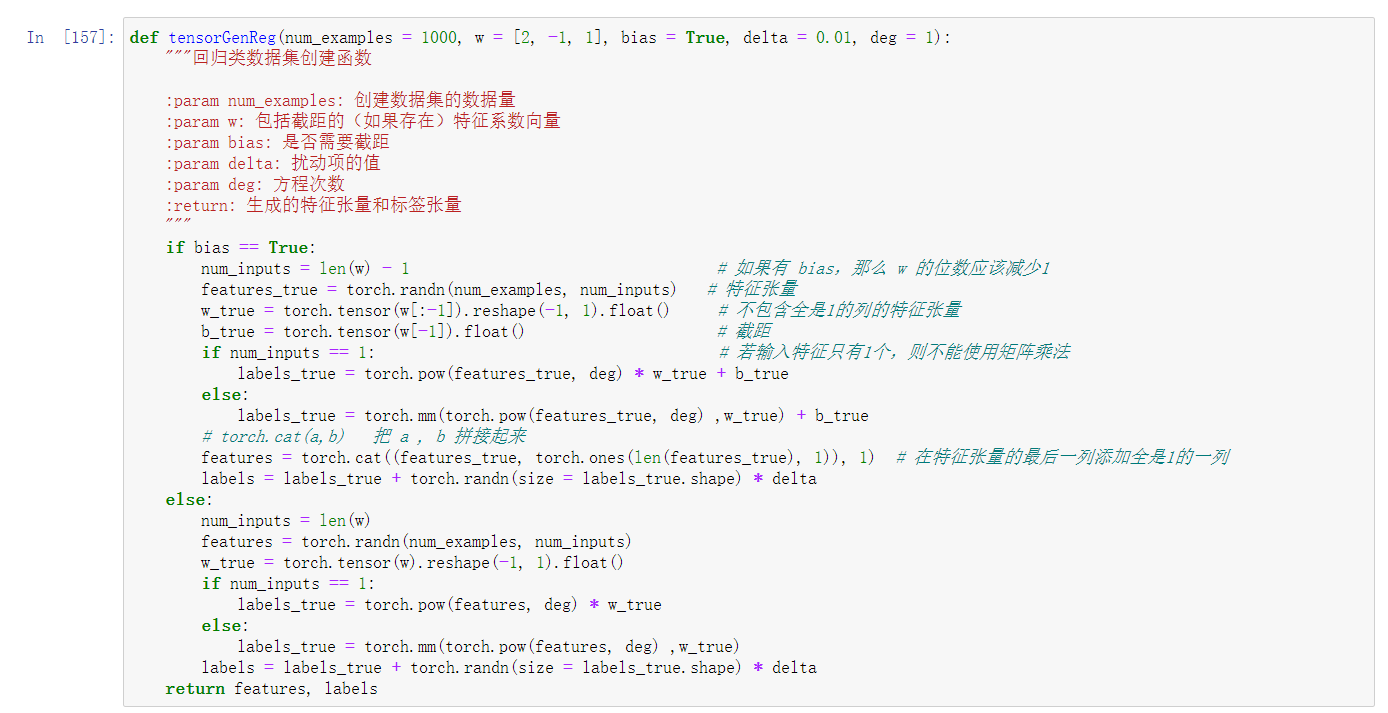
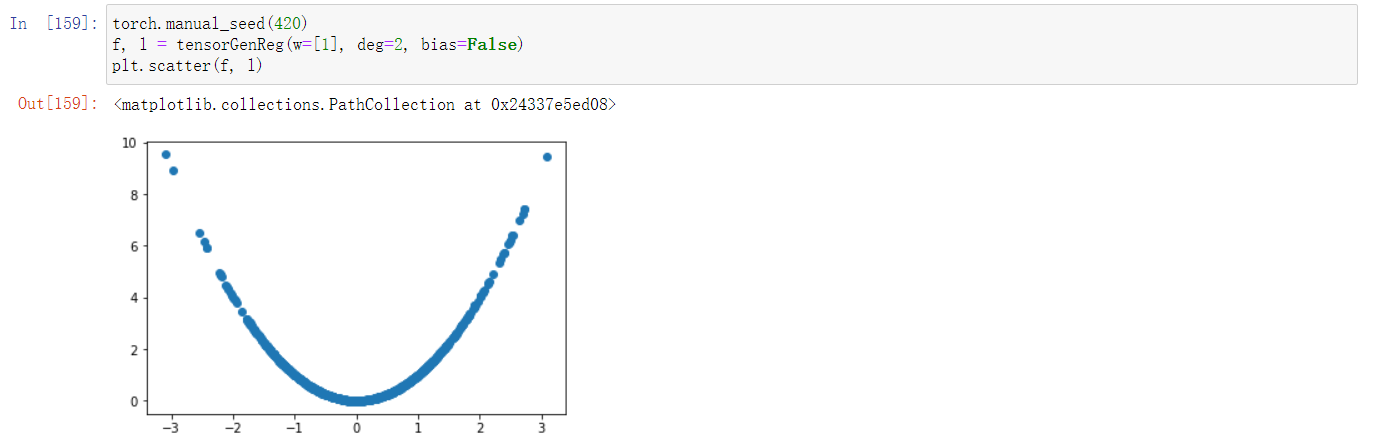
2. 创建生成回归类数据函数
1 | # 随机模块 |
二、分类数据集创建方法
和回归模型的数据不同,分类模型数据的标签是离散值
1. 手动创建分类数据集
回顾
torch.narmal(4, 2, size(10,3))10行3列的 均值为4 标准差为2 的函数
影响中心点位置的因素:
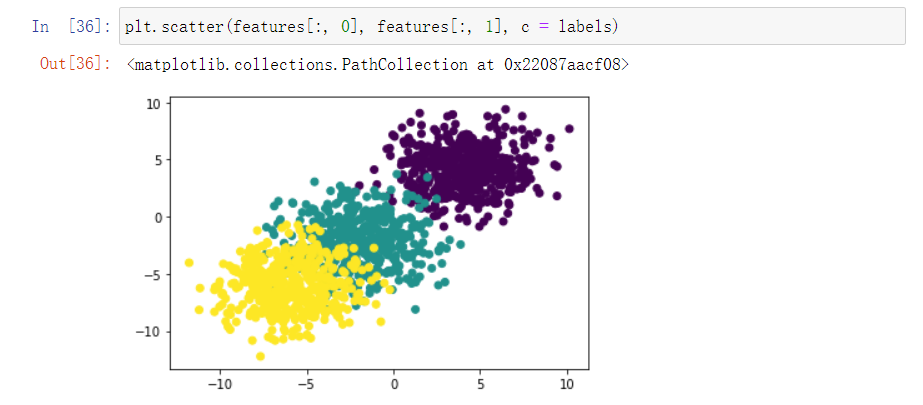
- 生成点时的均值差别越大,簇之间的距离越远
- 生成点时的标准差越大,离散程度越高
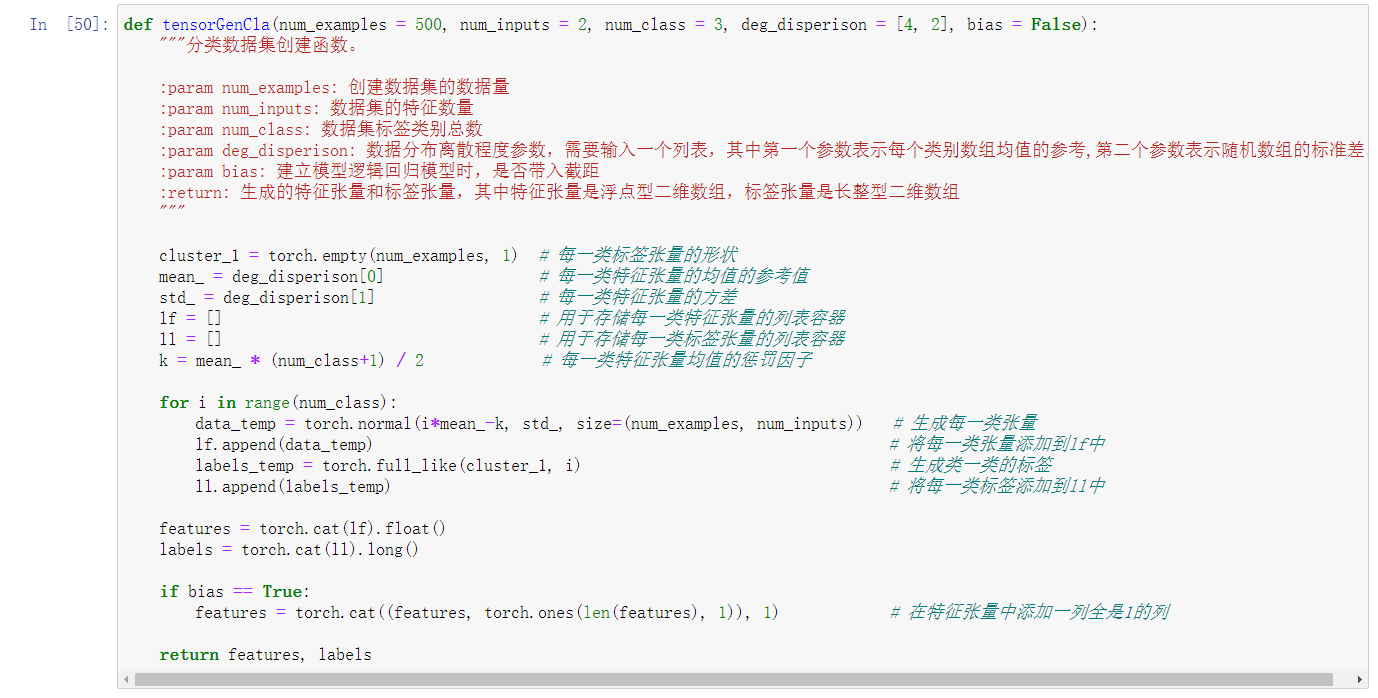
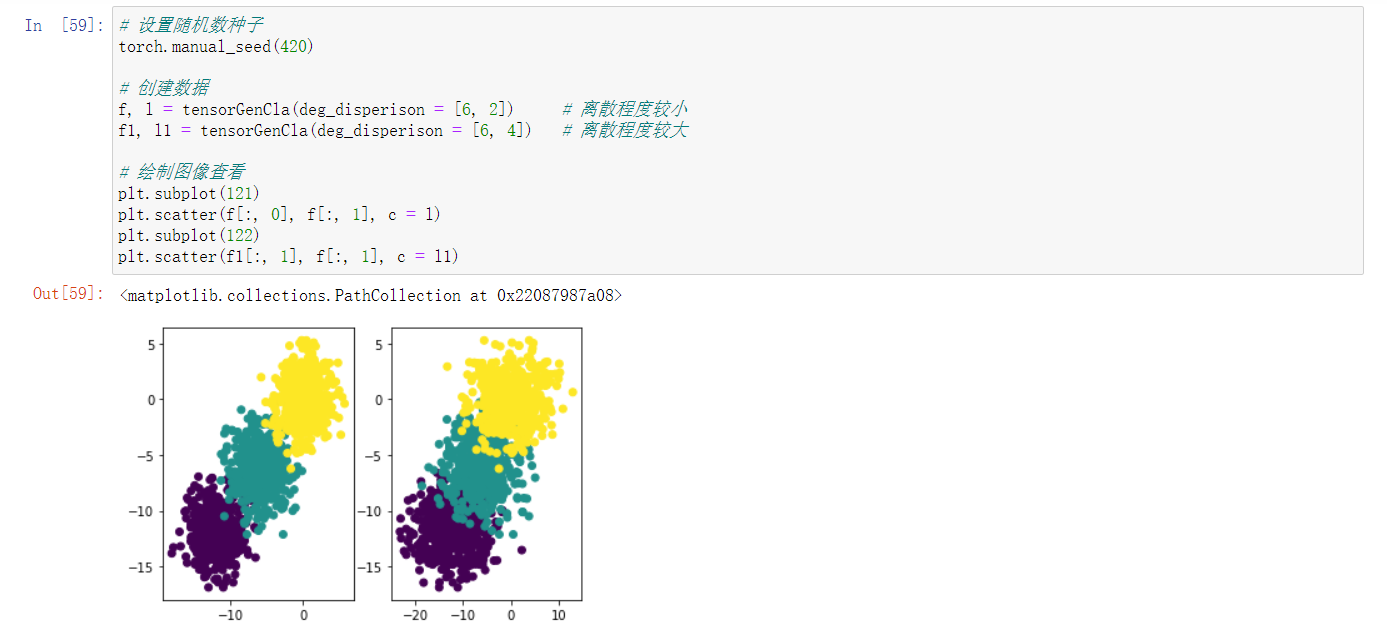
2. 创建生成分类数据函数
同样,我们将上述创建分类函数的过程封装为一个函数。这里需要注意的是,我们希望找到一个变量可以控制数据整体离散程度,也就是后续建模的难以程度。这里我们规定,如果每个分类数据集中心点较近、且每个类别的点内部方差较大,则数据集整体离散程度较高,反之离散程度较低。在实际函数创建过程中,我们也希望能够找到对应的参数能够方便进行自主调节,
1 | # 随机模块 |
三、创建小批量切分函数
1. 手动生成数据
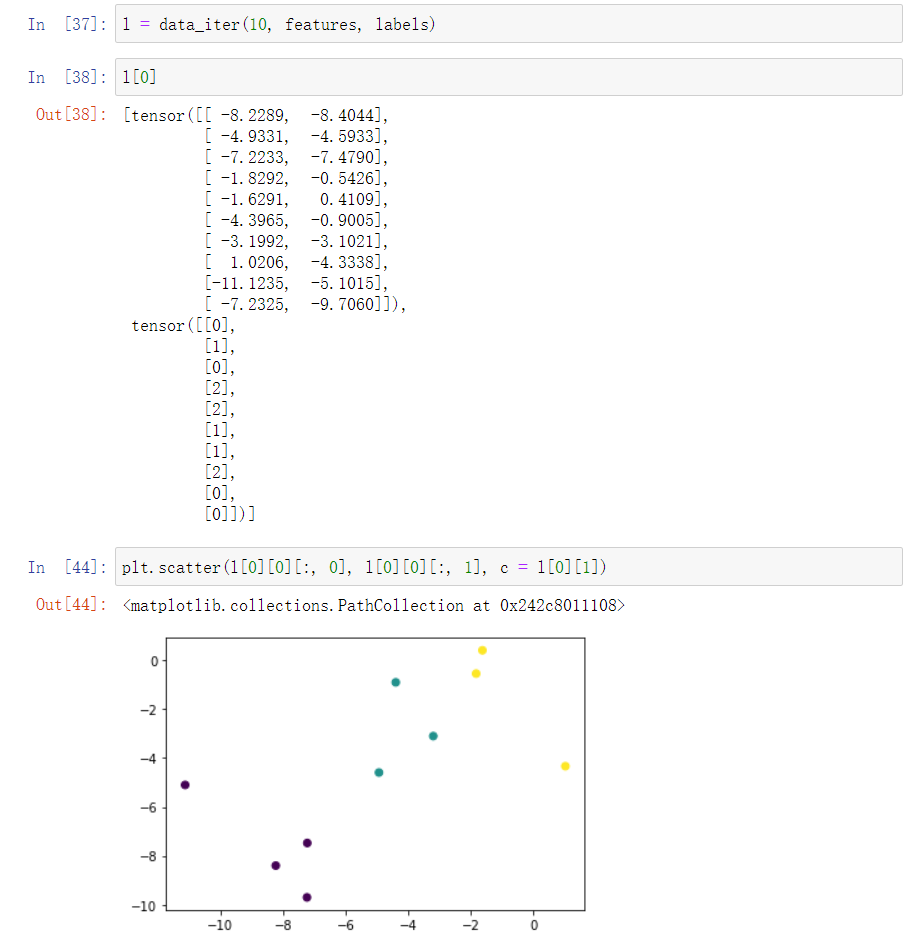
1 | def data_iter(batch_size, features, labels): |
四、Python模块编写
torchLearning.py
1 | # 随机模块 |
