

Stable Diffusion概述
Stable Diffusion(以下简称SD)分为 web-ui 和 comfy-ui 两种界面形式,管理方式均可以使用 ① github 命令行方式;② 绘世启动器(b站秋叶up主开发),web-ui 和 confy-ui 本质是一样的,不影响出图质量,只是呈现方式和使用方便程度不一样。
1. 模型
安装位置位于
web-ui\models\Stable-diffusion下,文件名称为model_name.safetensors模型为大量图片库的基础
注意:只把
model_name.safetensors移入没有预览图,如果需要预览图,把对应 model_name.png 放入同文件夹下即可
2. VAE 模型
类似滤镜
因为文件后缀都一样,区分是VAE还是大模型的网站Stable Diffusion 法术解析 (novelai.dev)
3. LORA
安装位置位于
web-ui\models\Lora下,文件名称为Lora_name.safetensorsLORA 为在以模型出图过程中添加的 “佐料”,LORA体积远小于模型体积,注入LORA一定程度上影响出图风格
注意:只把
model_name.safetensors移入没有预览图,如果需要预览图,把对应 model_name.png 放入同文件夹下即可
4. 文生图 / 图生图 共同参数
① 同样提示词、不同排列顺序结果不同,并且“blue hair” 可能会给衣服“染色”,所以调整提示词顺序也是调整图片的方法之一。

② 有没有逗号也不一样

③ 手动赋权
1 | # (关键词:权重) |
快捷键:选中 ctrl+↑ / ↓

④ 参与绘图步数
1 | # [提示词::参与程度] |

拓展:分段提示词
1 | # [提示词1:提示词2:切换百分比] |

特殊情况:
① 中括号
[::x]变成小括号(::x):如果0≤x≤1在也可以出图并控制权重,如果x>1无法出图;② [::x]
x值超过上限就取step上限值;③ [::x]
x值超是负数会起反作用,是负数就行,具体负数的大小与最终出图无关,会排除类似元素(甚至可能比反向提示词都好用)

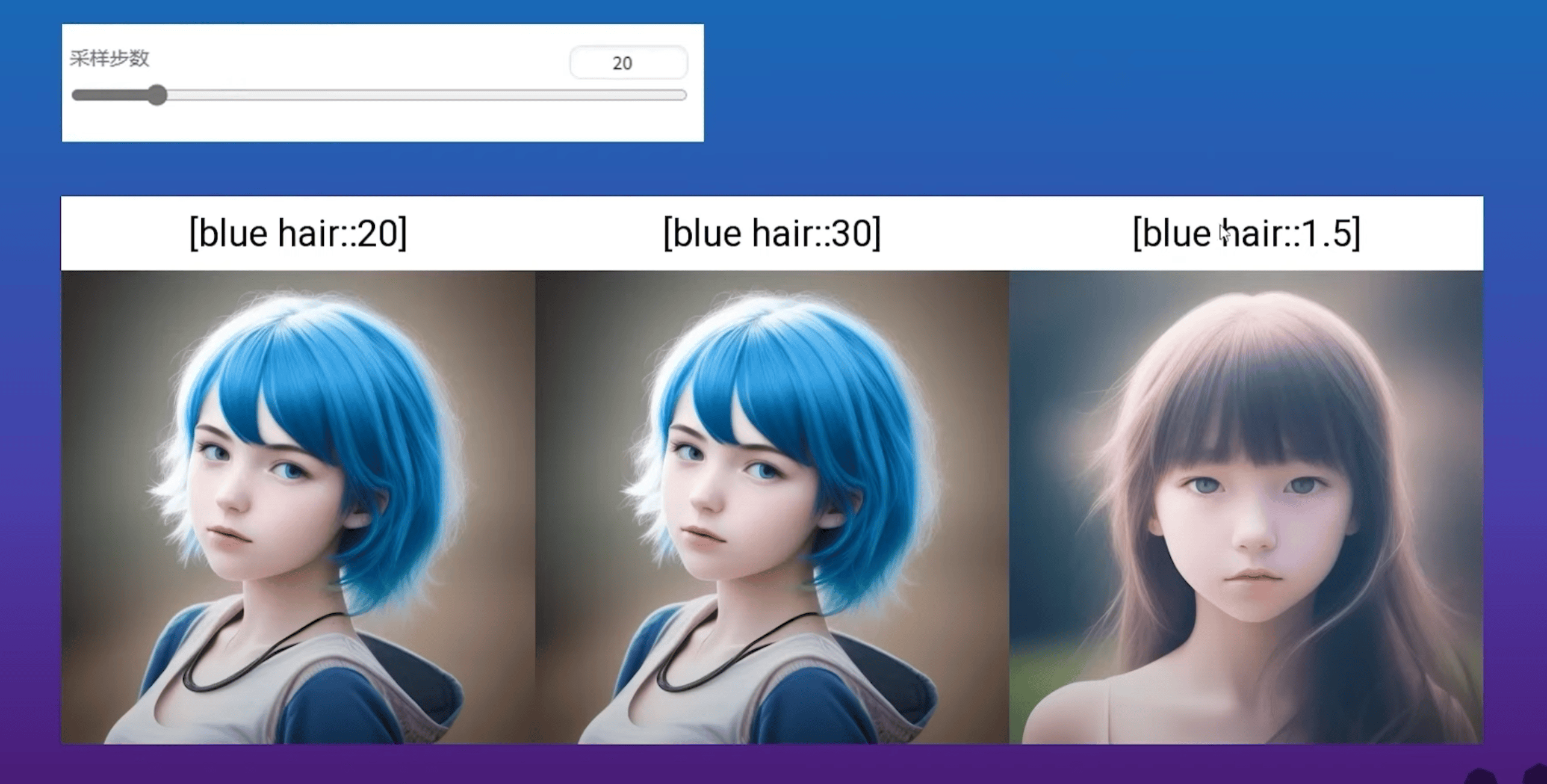

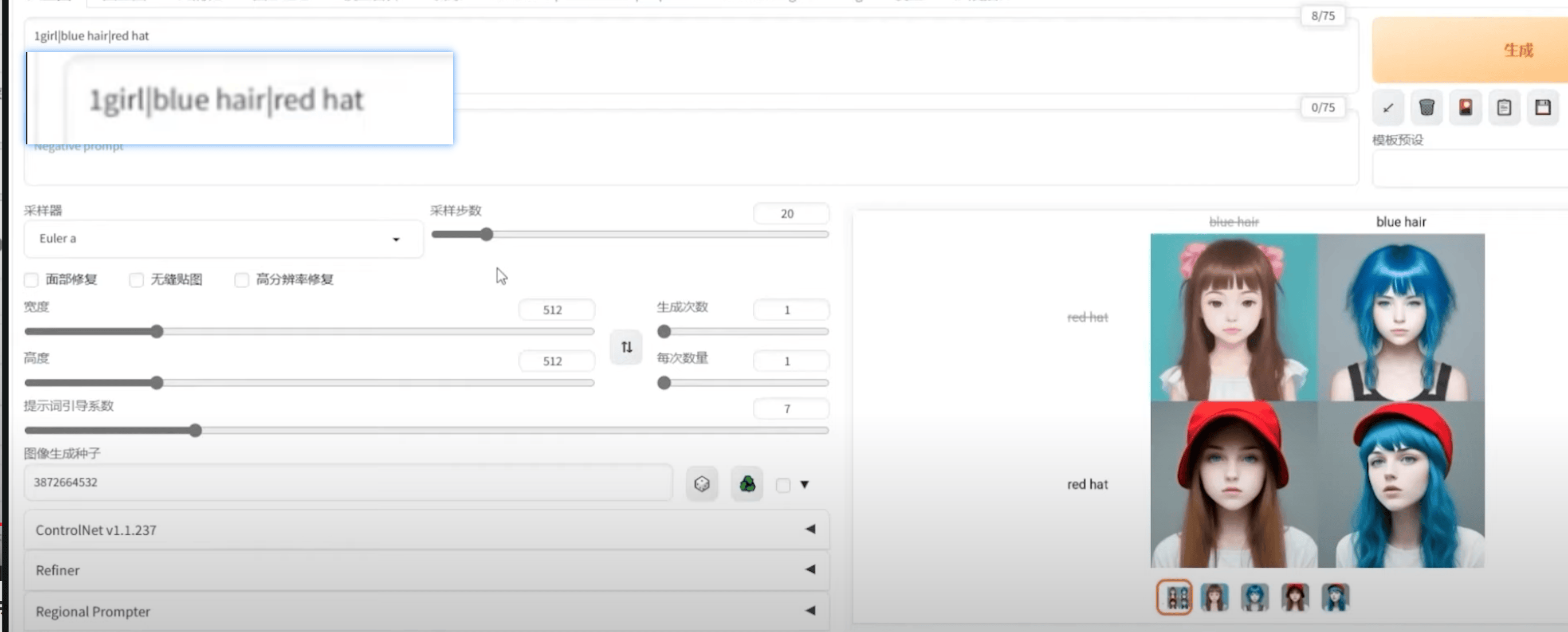
⑤ 提示词矩阵
1 | 默认词1|可选词1|可选词2|可选词3|……|可选词N |

4.1 提示词
4.1.1 正向提示词
Best quality,Photorealistic,Raw Photo
最佳品质,真实感,原始照片
4.1.2 反向提示词
示例1:
1 | (worst quality:2), (low quality:2), (normal quality:2),skin spots, acnes, age spot, Dim color,Missing limbs,Extra limbs,Loss of limbs,Redundant limbs,Limb dislocation,Loss of key human body parts,Wrong limb position,Abnormal human structure,Bad body details,Limb fusion,Limb Overlay,sketchillustrious,logo,text |
(最差质量:2), (低质量:2), (正常质量:2), 皮肤斑, 痤疮, 老年斑, 肤色暗淡, 肢体缺失, 肢体多余, 肢体缺失, 肢体多余, 肢体脱位, 丧失 人体关键部位,肢体位置错误,人体结构异常,身体细节不良,肢体融合,肢体叠加,素描,标志,文字
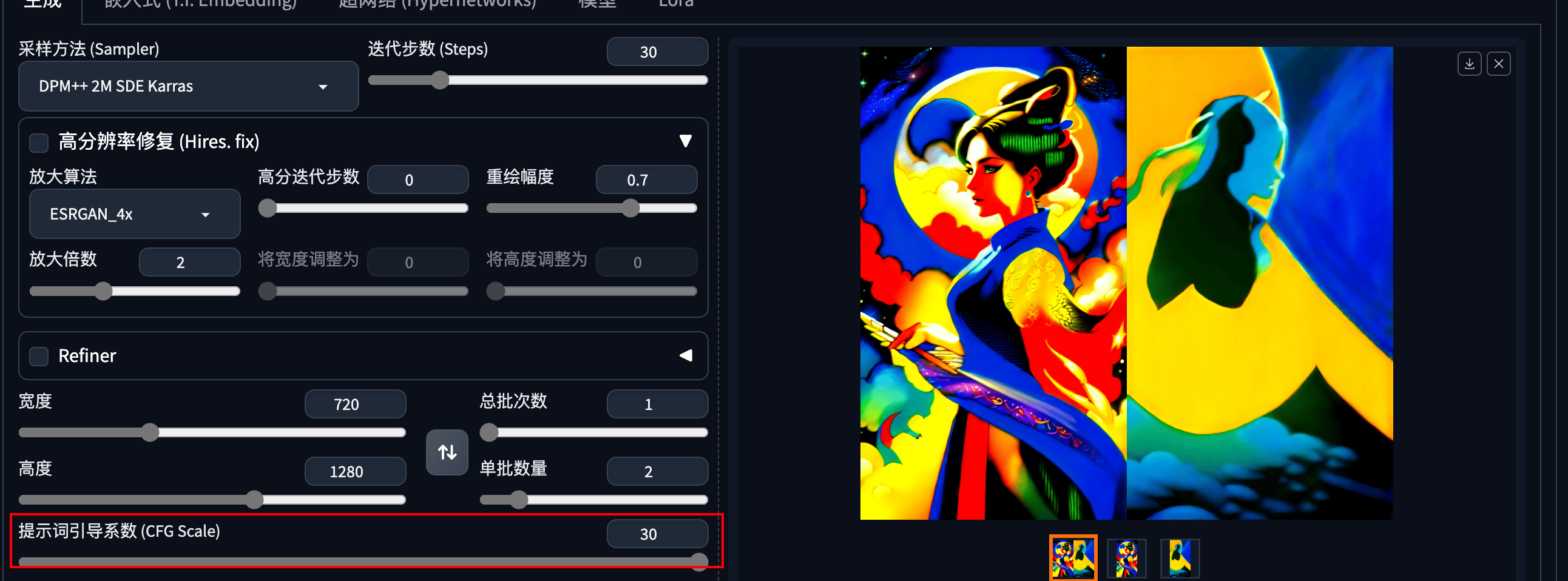
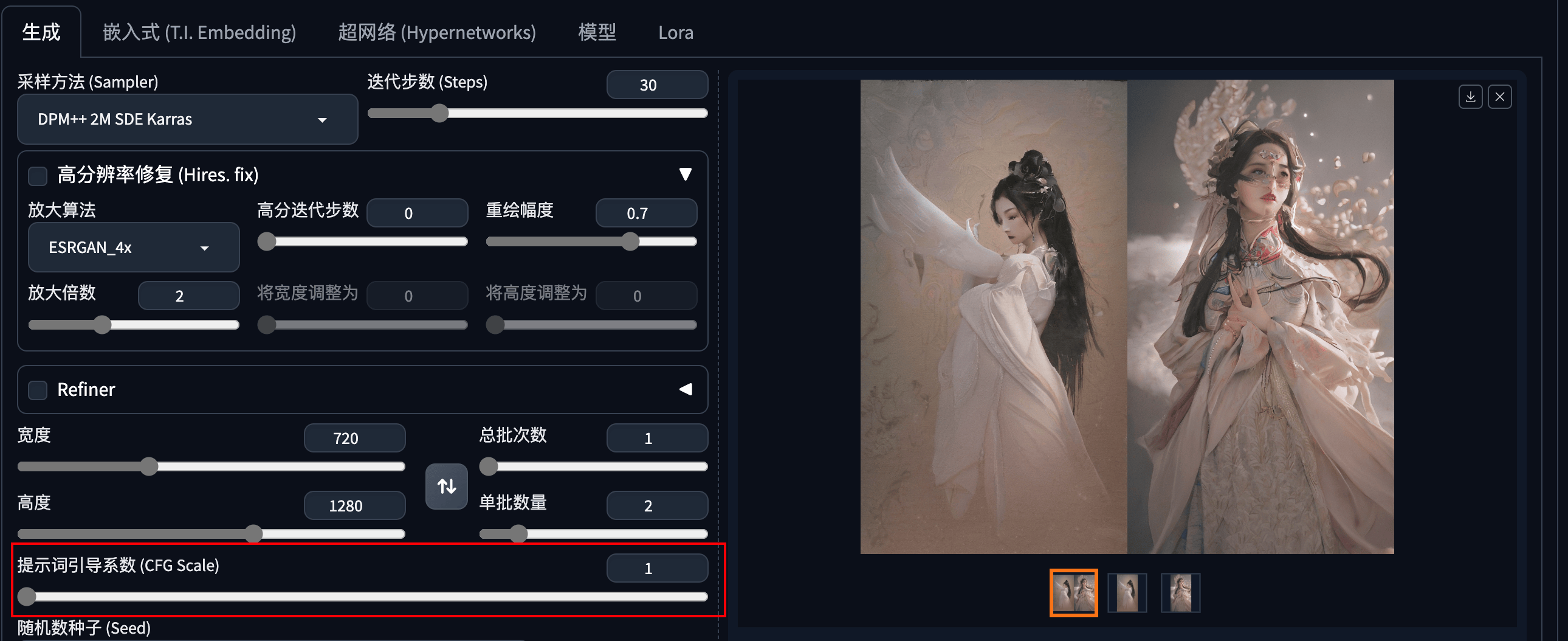
4.2 CFG
在Stable Diffusion模型中,CFG(Classifier Free Guidance)用来控制生成图像与文本提示(prompt)之间的匹配程度。
CFG值越高,生成的图像就会更严格地遵循文本提示的内容。
理论上,当CFG值增加时,图像的颜色饱和度和对比度也会增加
但是如果CFG值过高,可能会导致图像细节的丢失
CFG值设置在4到15之间可以得到较好的效果。如果CFG值设置得太低,可能会导致图像看起来模糊不清,颜色对比弱,构图质量差(我发现CFG过低面部也会崩掉)。而CFG值过高,则可能会使图像过于饱和,颜色和结构失调。
CFG=30(MAX)
CFG=1(MIN)
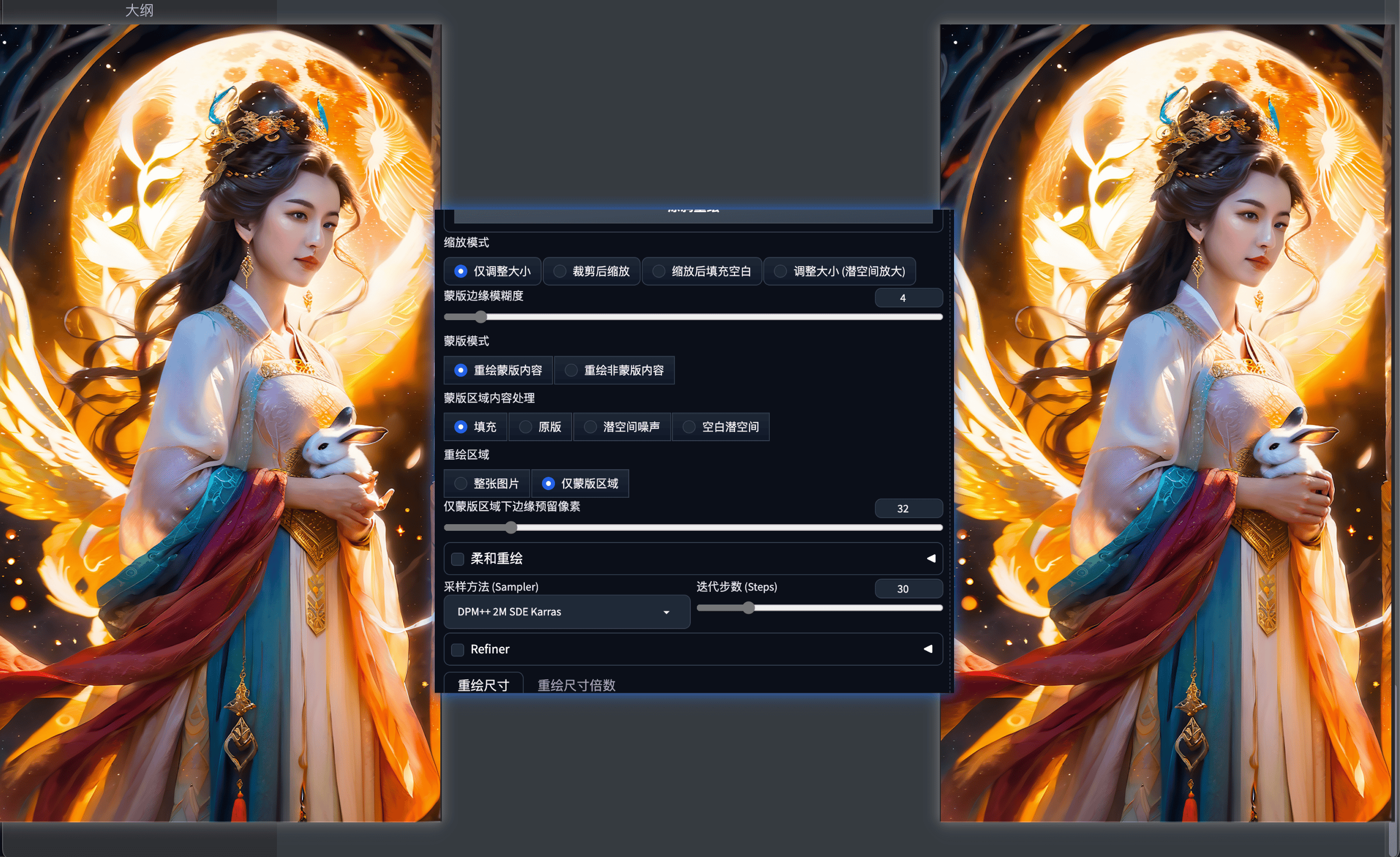
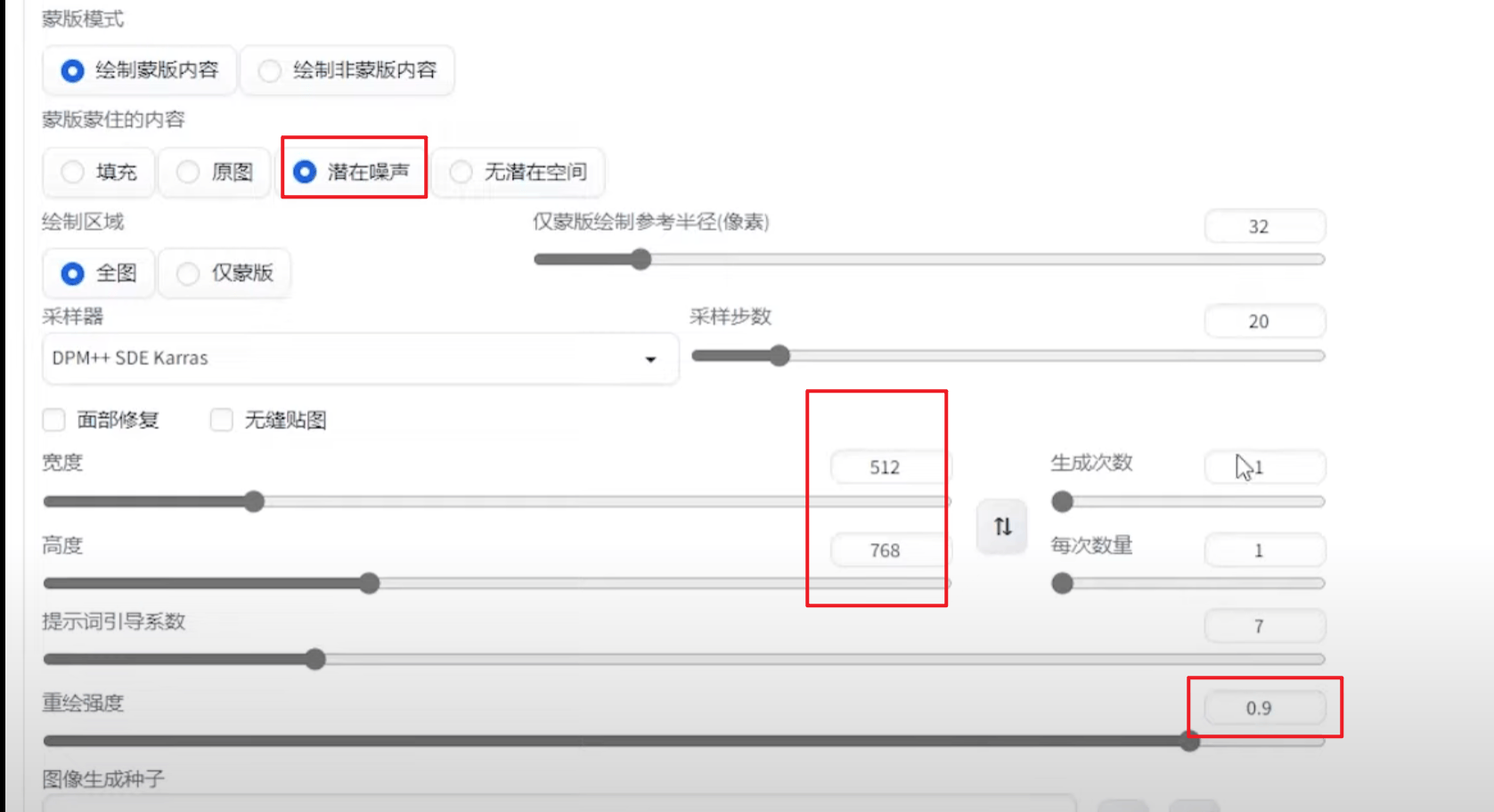
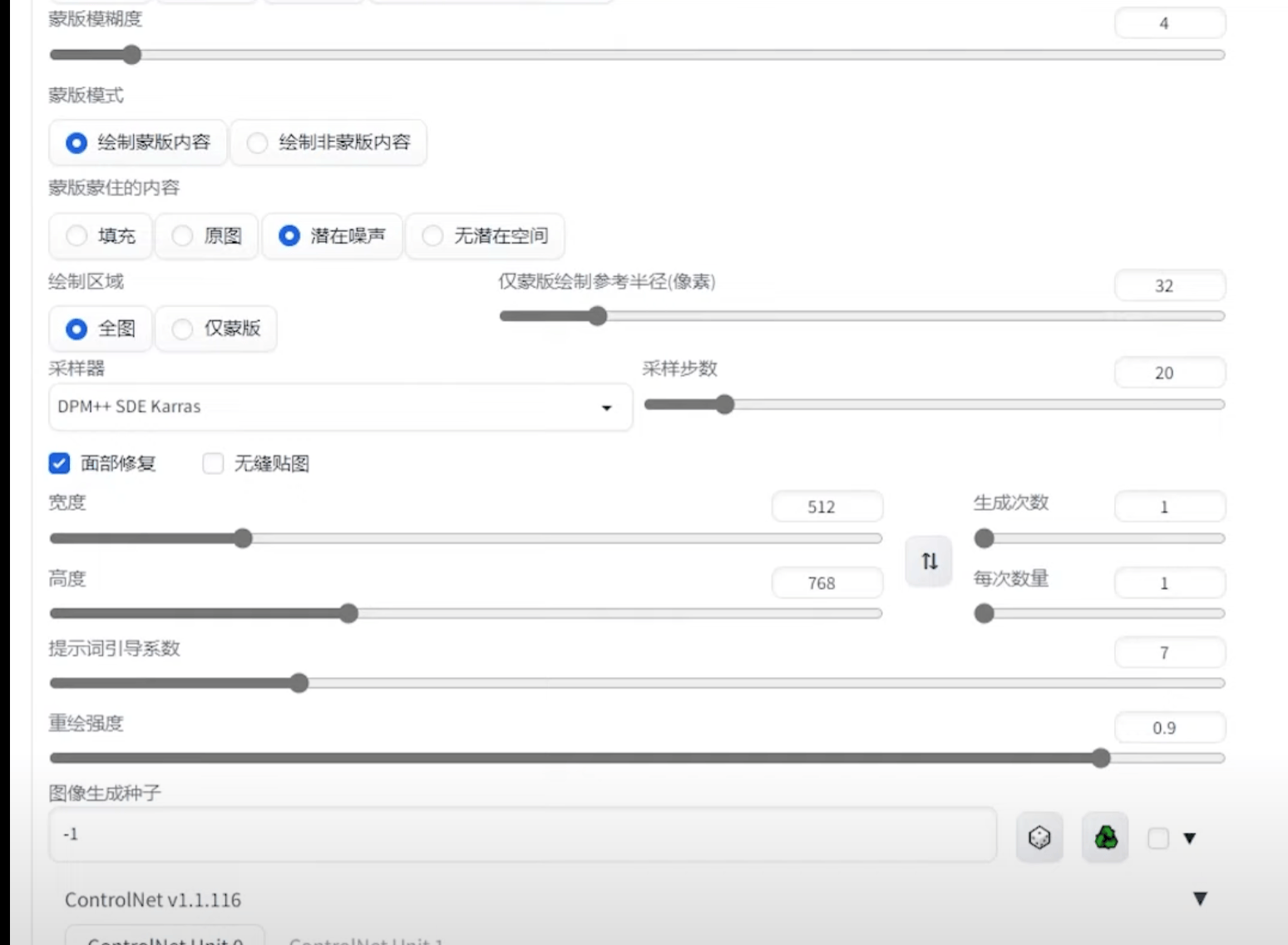
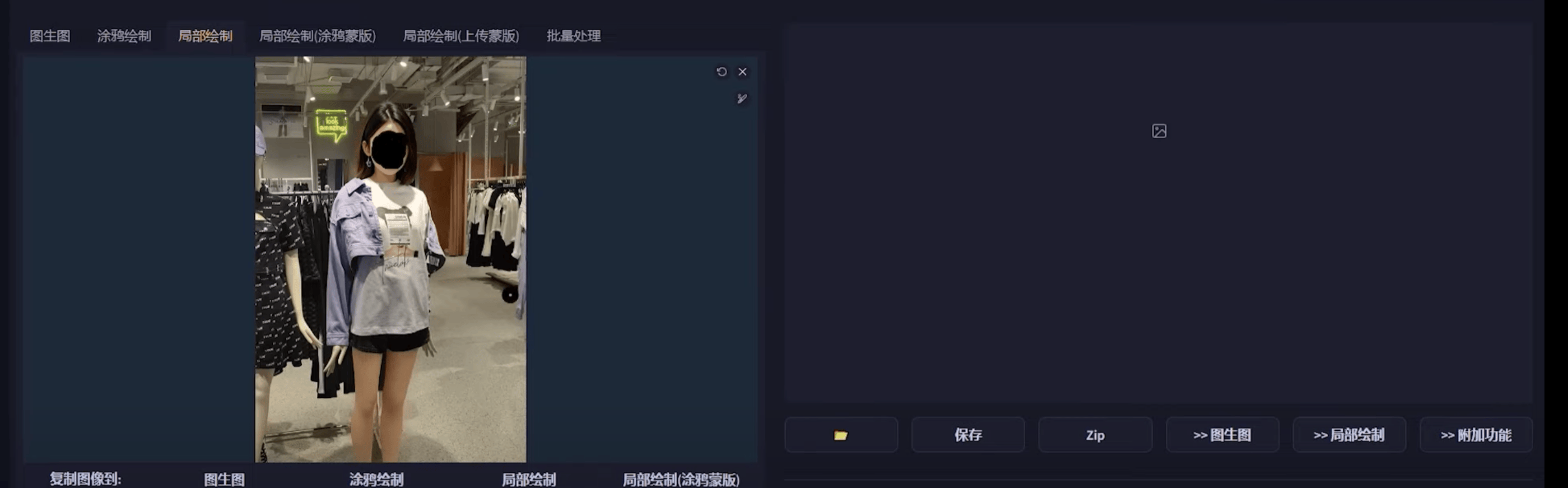
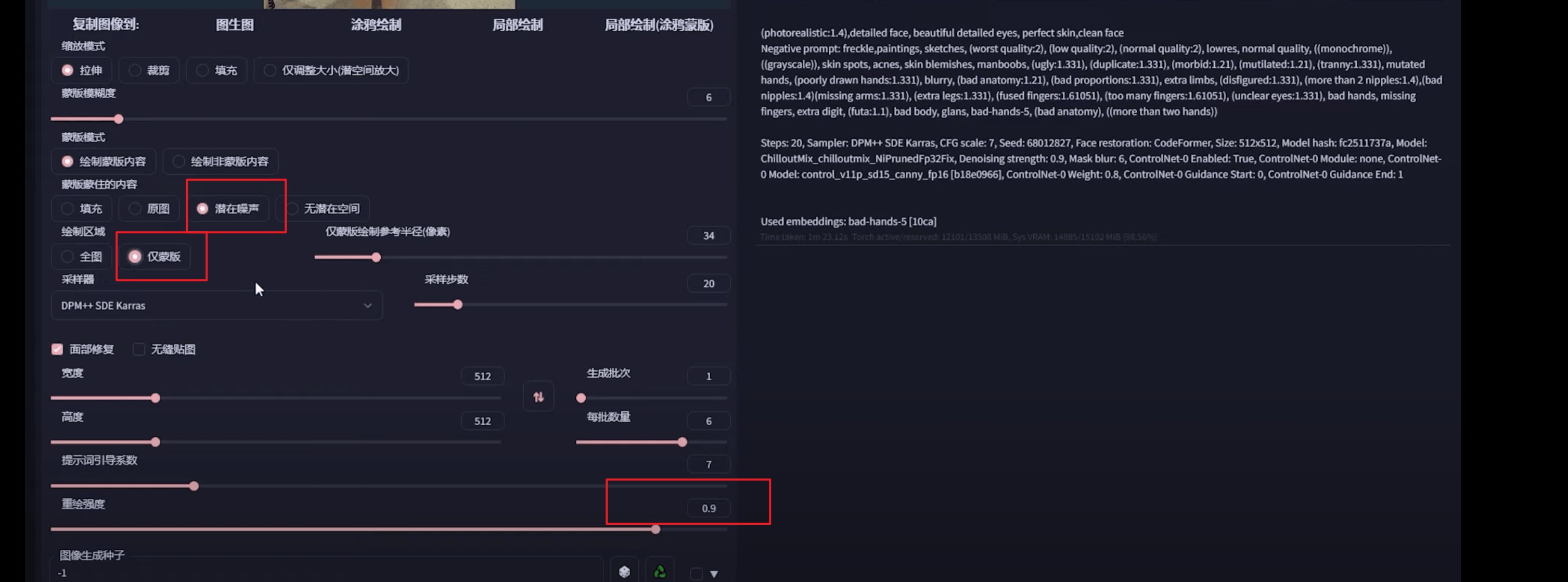
4.3 局部重绘

参数解释
蒙版边缘模糊度
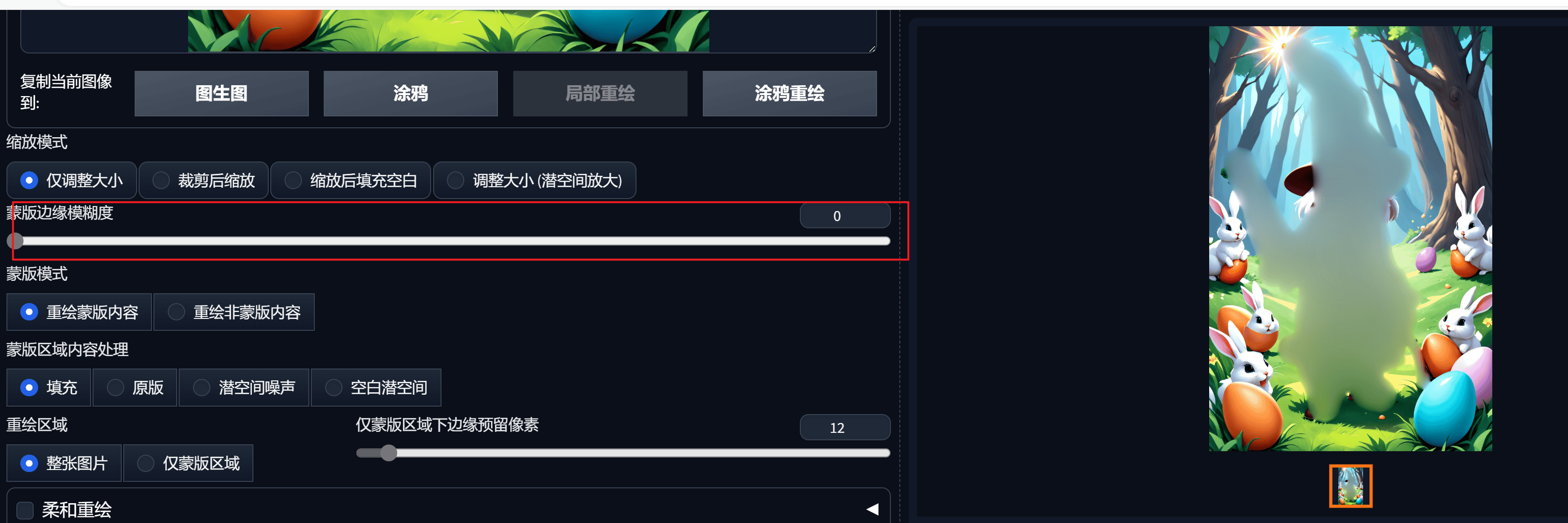
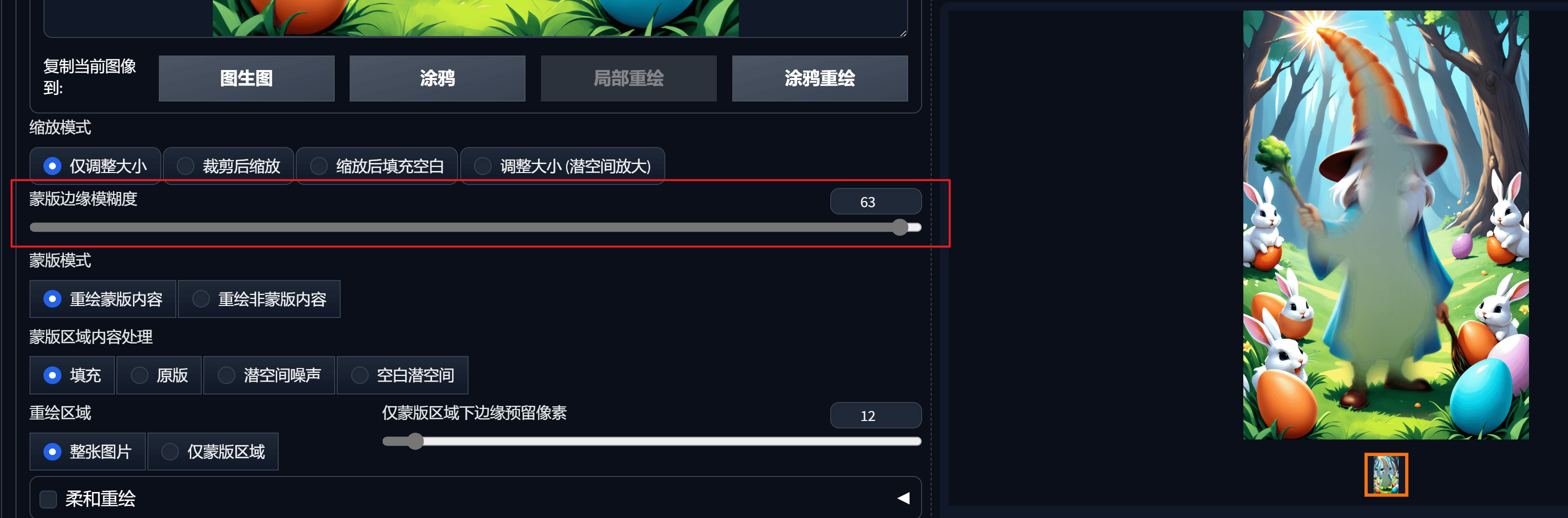
蒙版区域内容处理
填充参考周围的像素生成相关的东西原图是在原图基础上做一些微调,(会参考原图的风格色调)``潜在噪声` 适合凭空出现某个东西的情况,可能会有些割裂
无潜在空间相对独立的出现某个东西,可能会有些割裂

手指纯绘
重绘区域
全图模式充分参考了原图,重绘出的汽车与原图融合的更好【从整张图片出发,参考全局描述词来补充蒙版部分】仅蒙版区域只绘制蒙版的部分【描述词部分应该仅描述遮罩部分】仅蒙版区域下边缘预留像素该参数越小,绘制细节越丰富,推荐:如果蒙版区域较小,需要局部修改,就可以适当调大参考半径,如果蒙版区域足够大,需要重绘足够的细节,则需要适当调小参考半径。

4.4 涂鸦重绘
就是在局部重绘的基础上,考虑颜色的问题
注意:我操作下来,感觉只有在
蒙版区域内容处理选择原版才会按照颜色进行参考

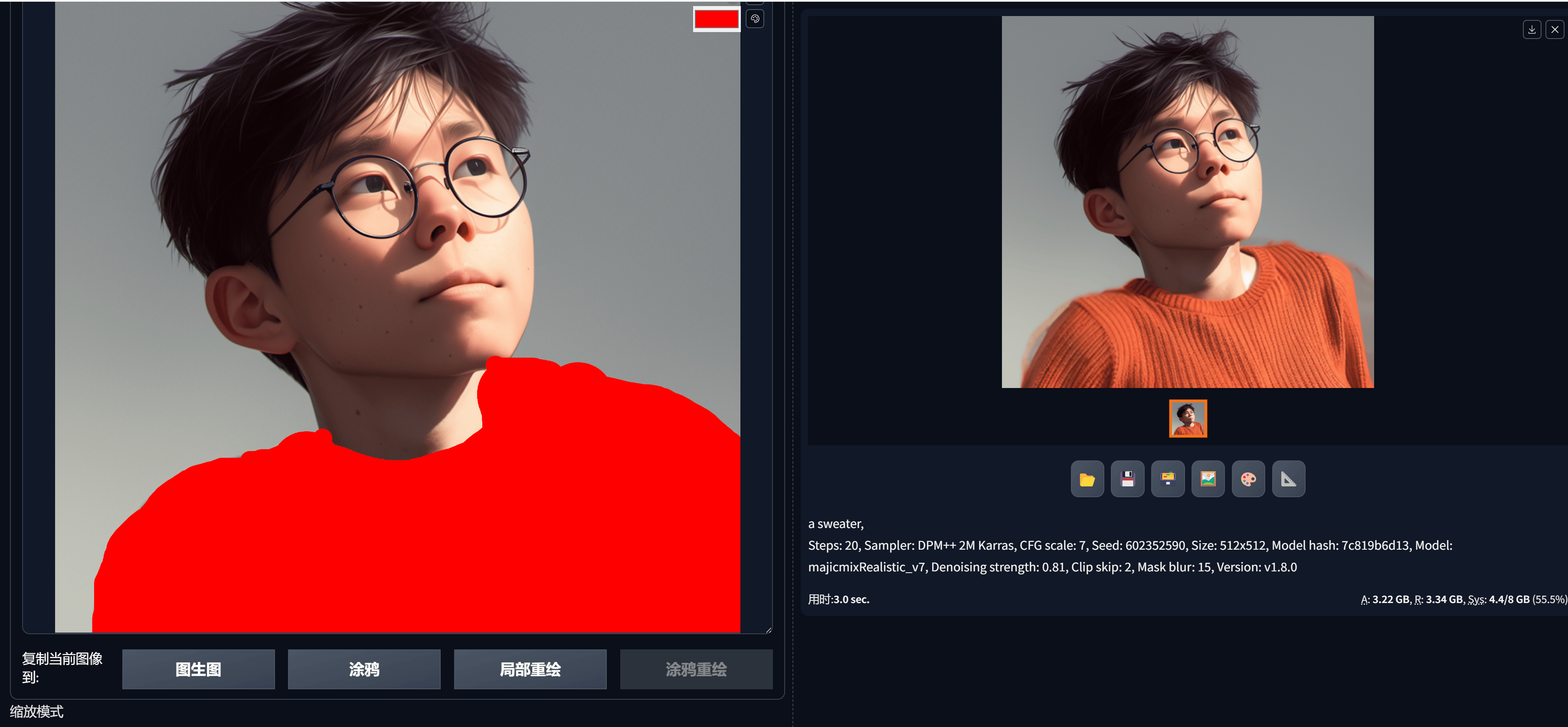
描述词:a sweater(一件毛衣)
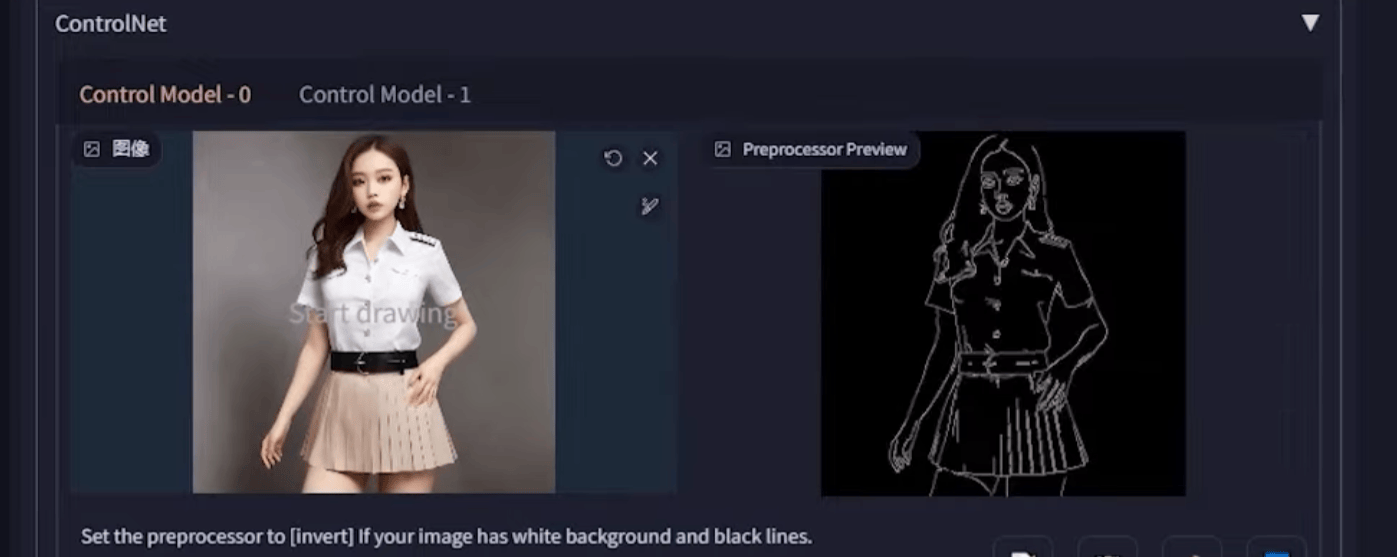
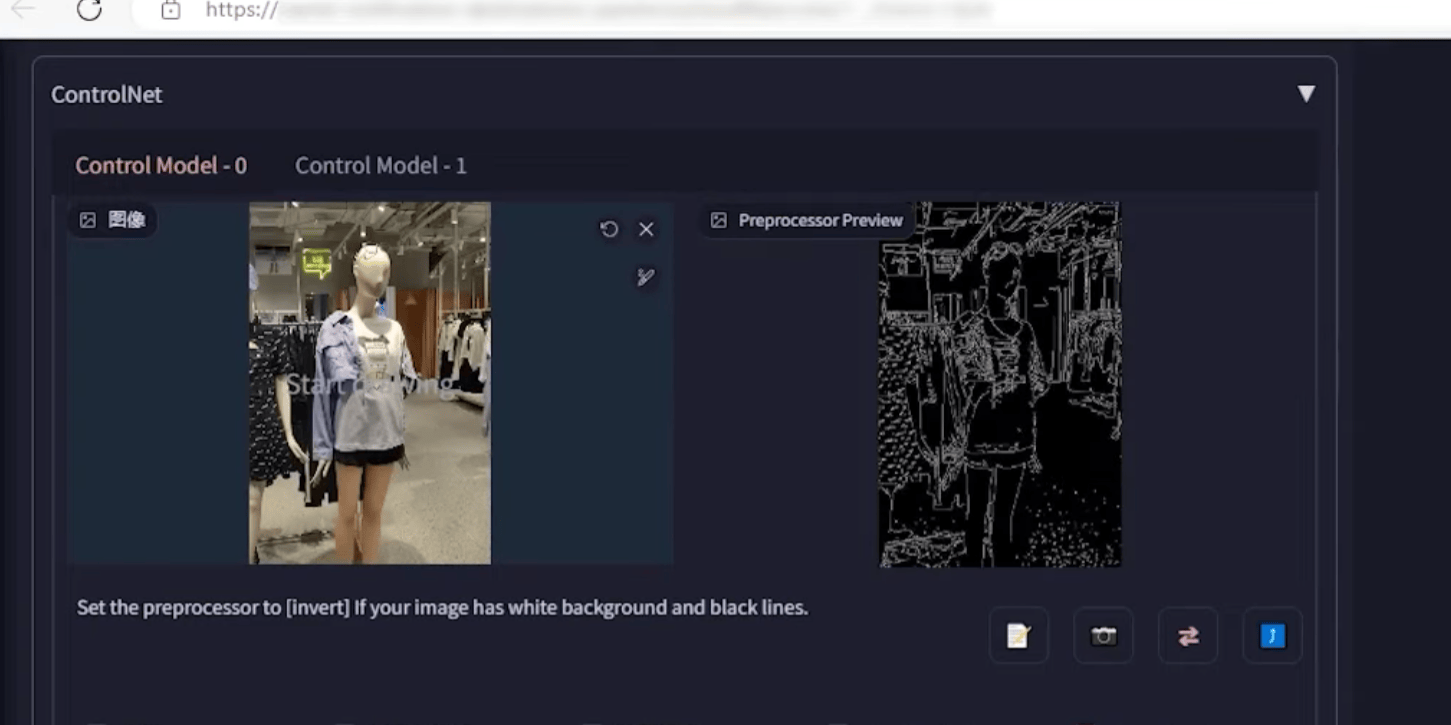
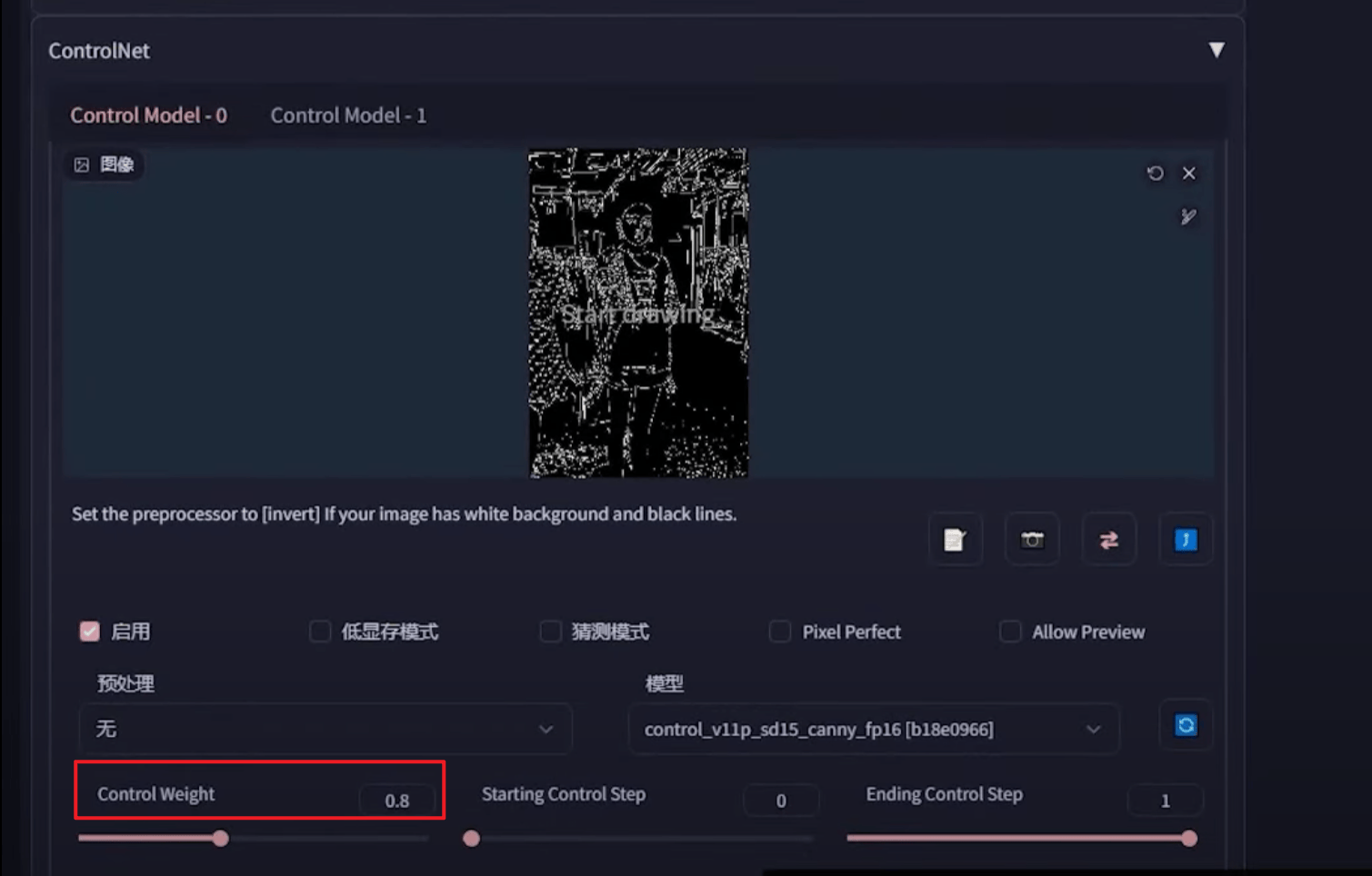
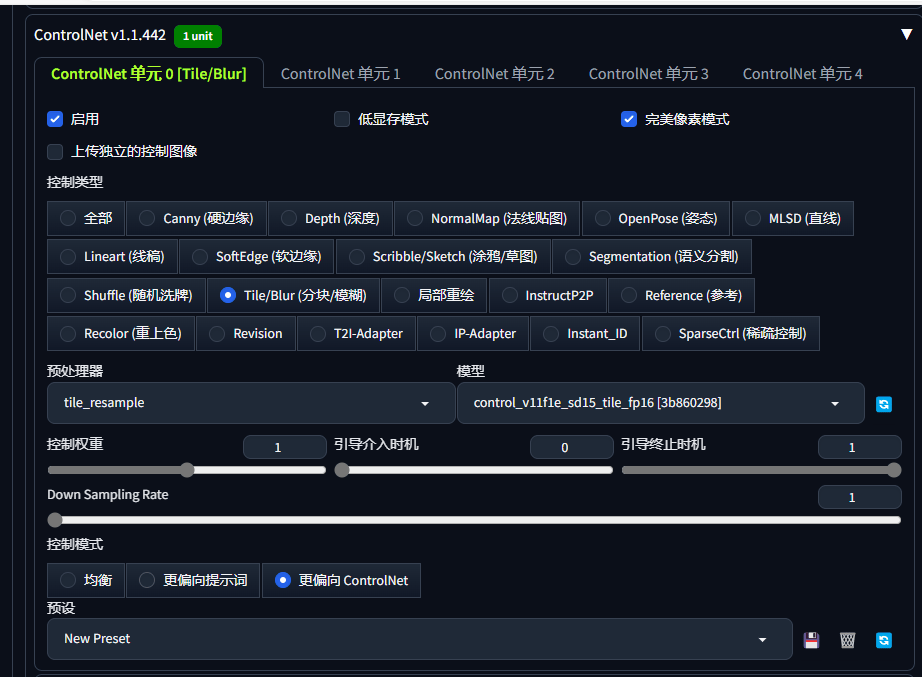
5. ControlNet
为控制图片而生,图片控制体系,提供多种方式有目标性的控制图片
扩展列表网址 使用方式:web-ui——扩展插件——可用——加载自:
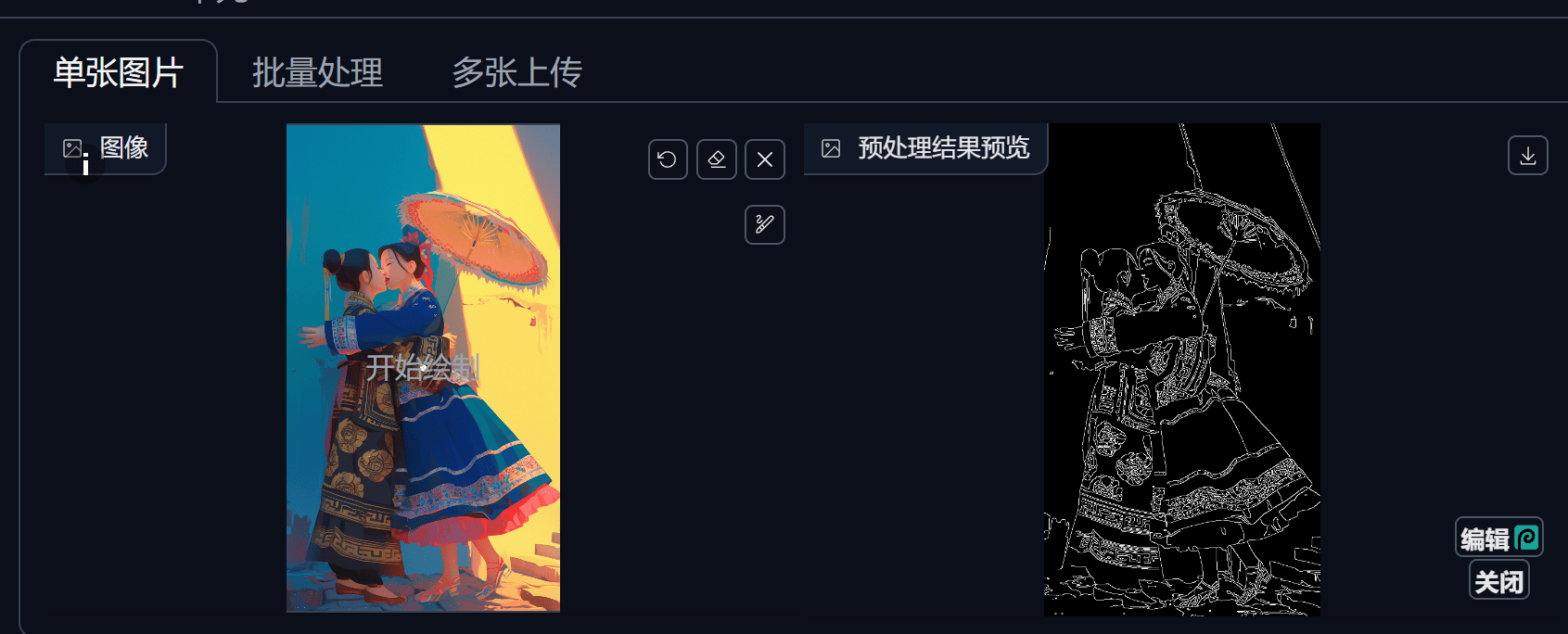
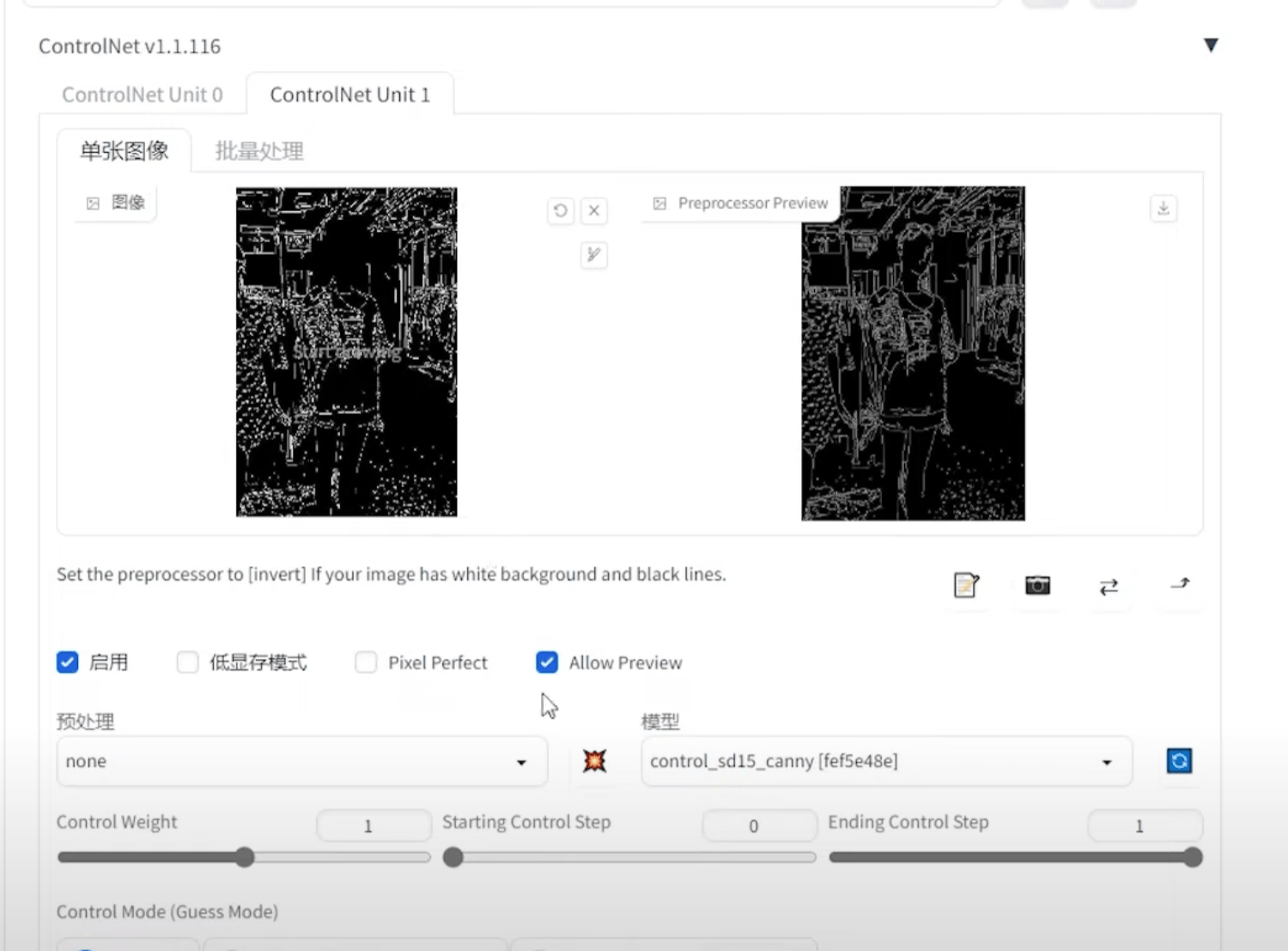
Canny(硬边缘)
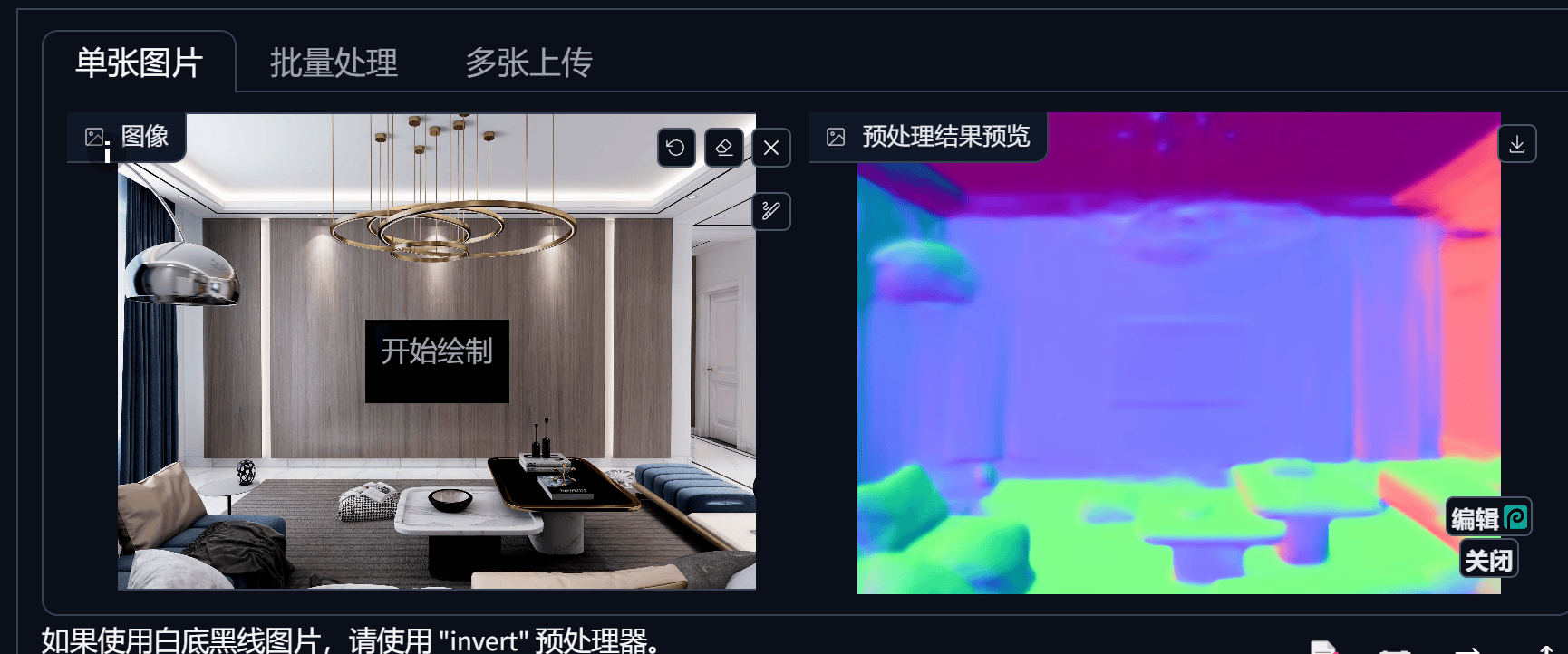
Depth(深度)
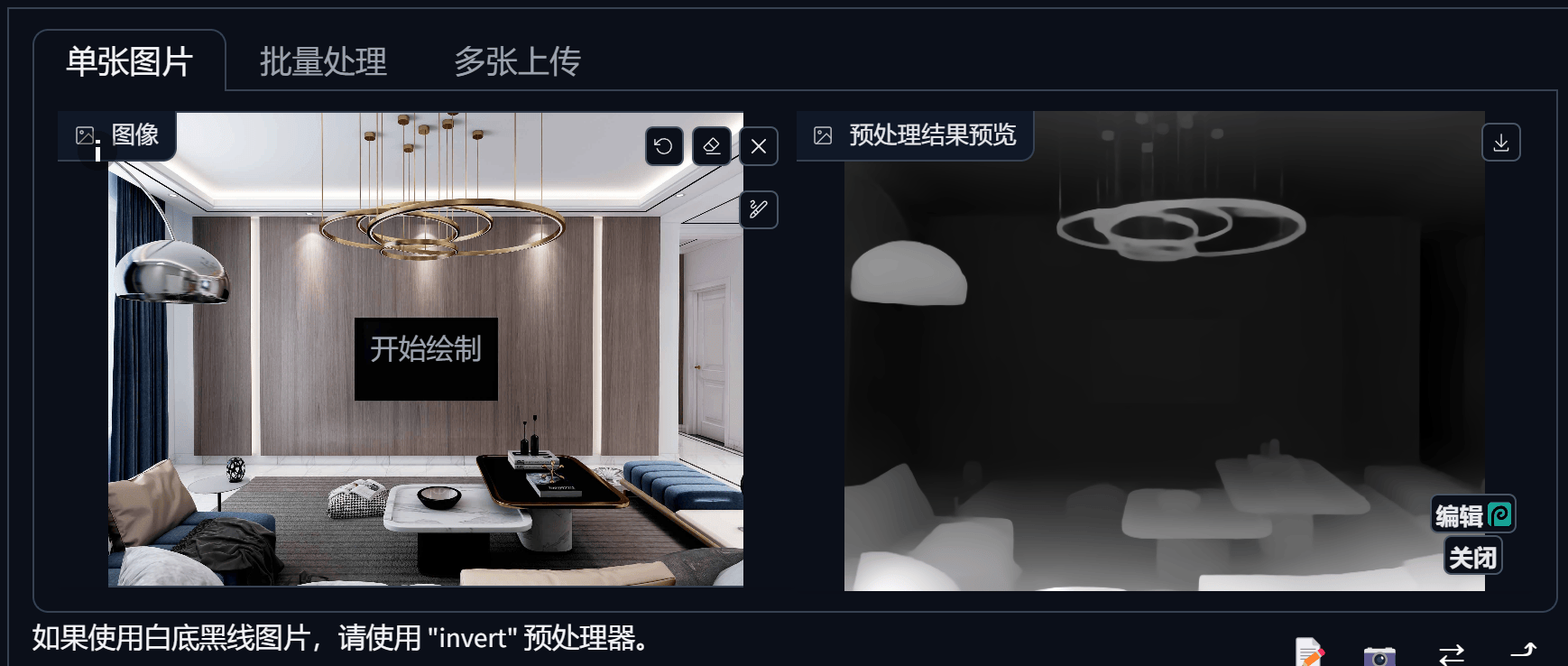
NormalMap(法线贴图)
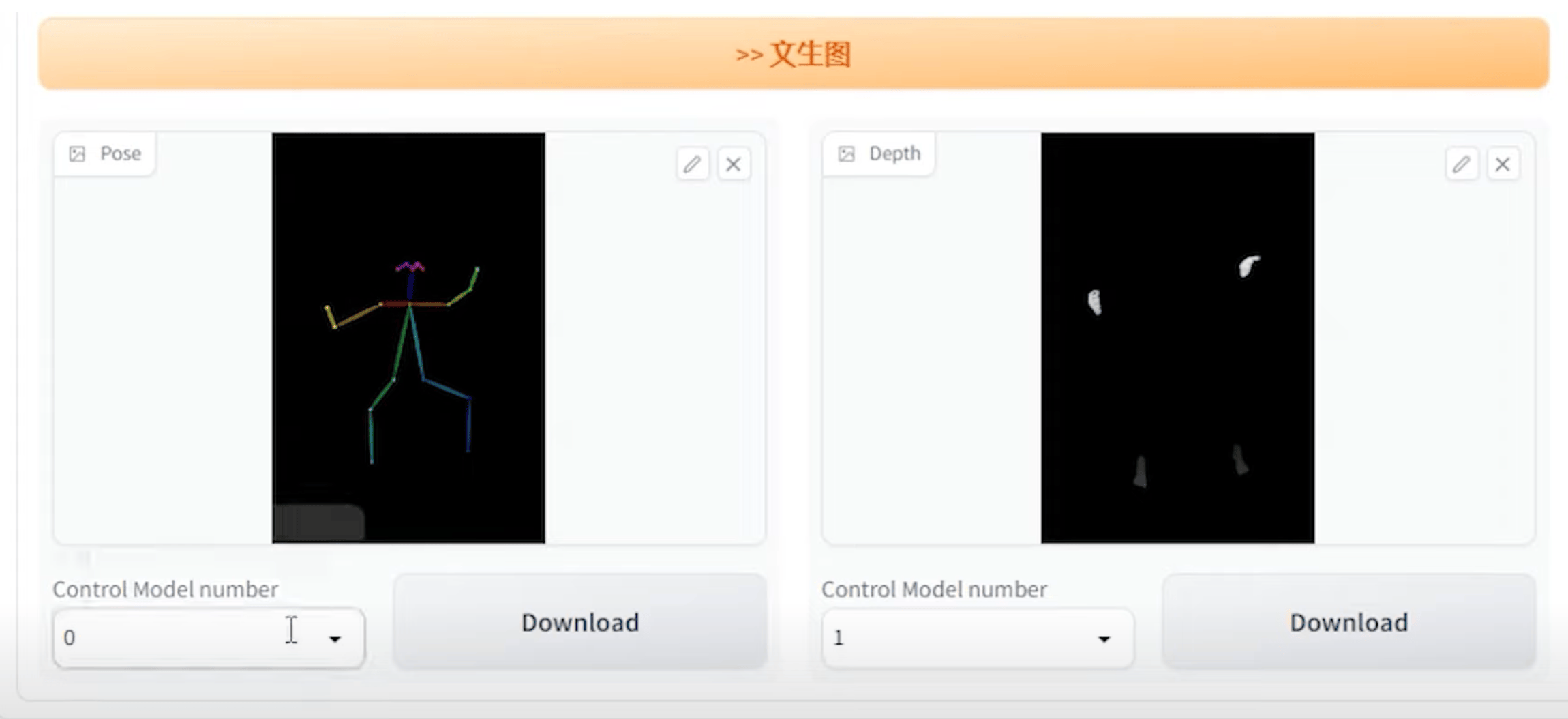
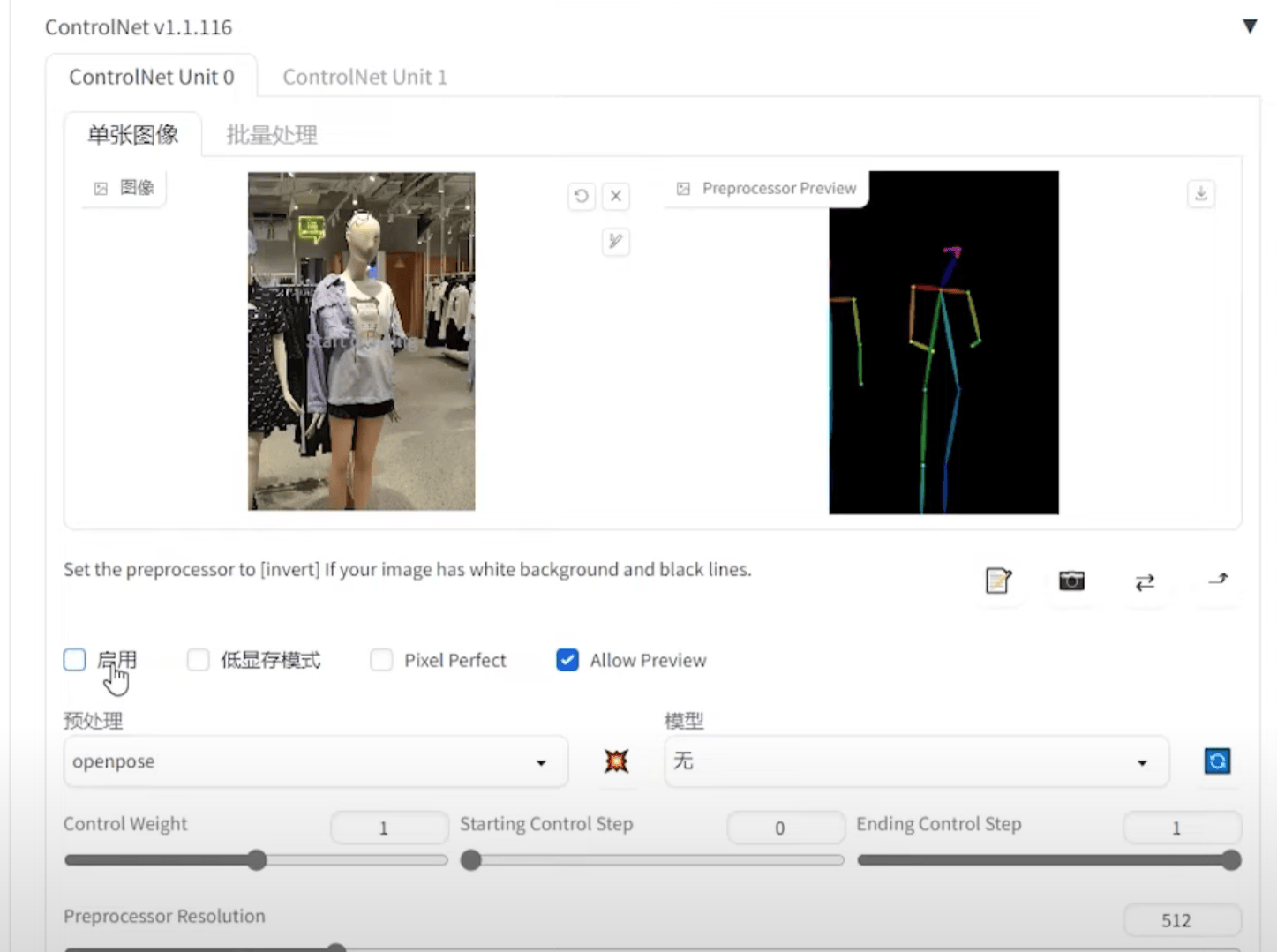
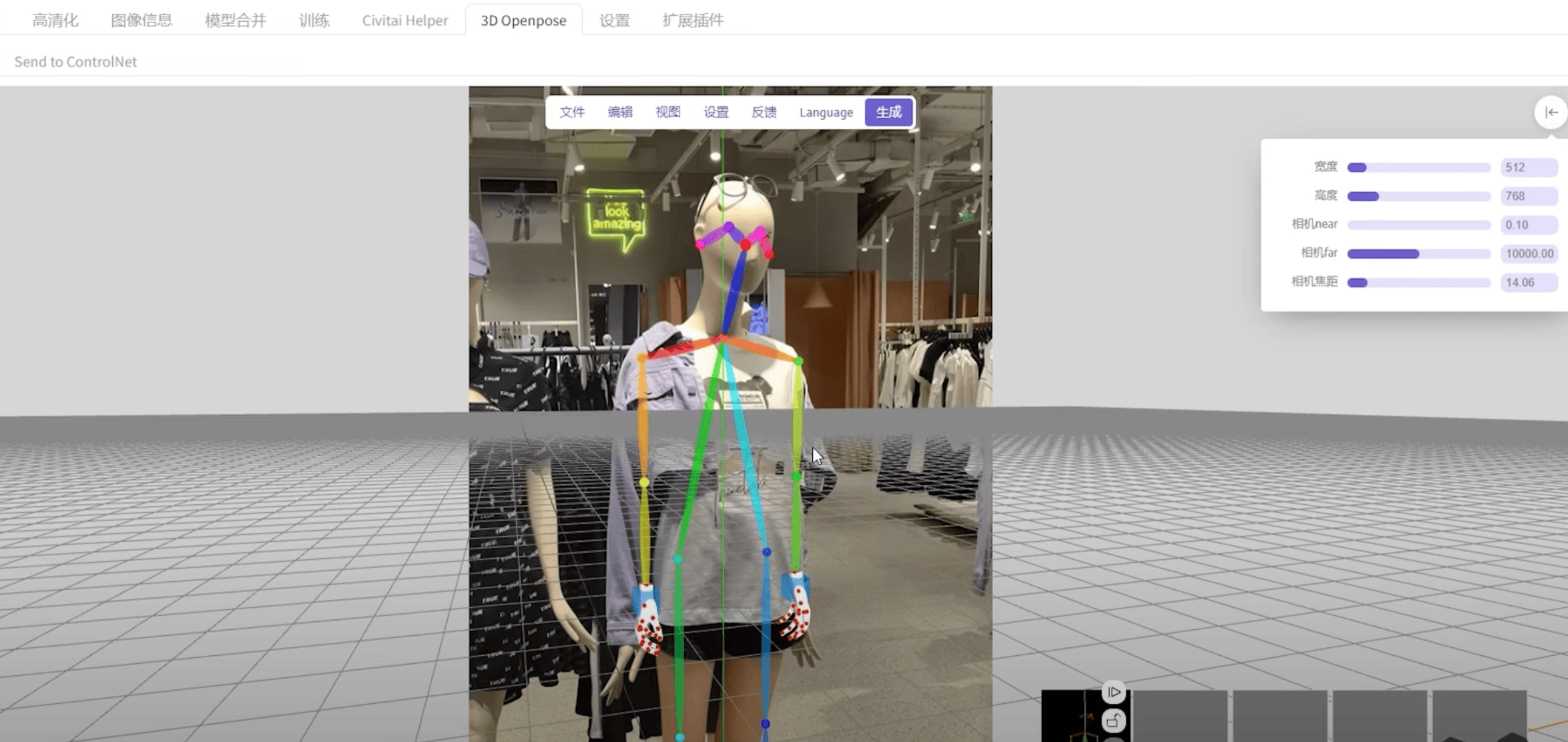
OpenPose(姿态)

3D Openpose插件

MLSD(直线)

Lineart (线稿)
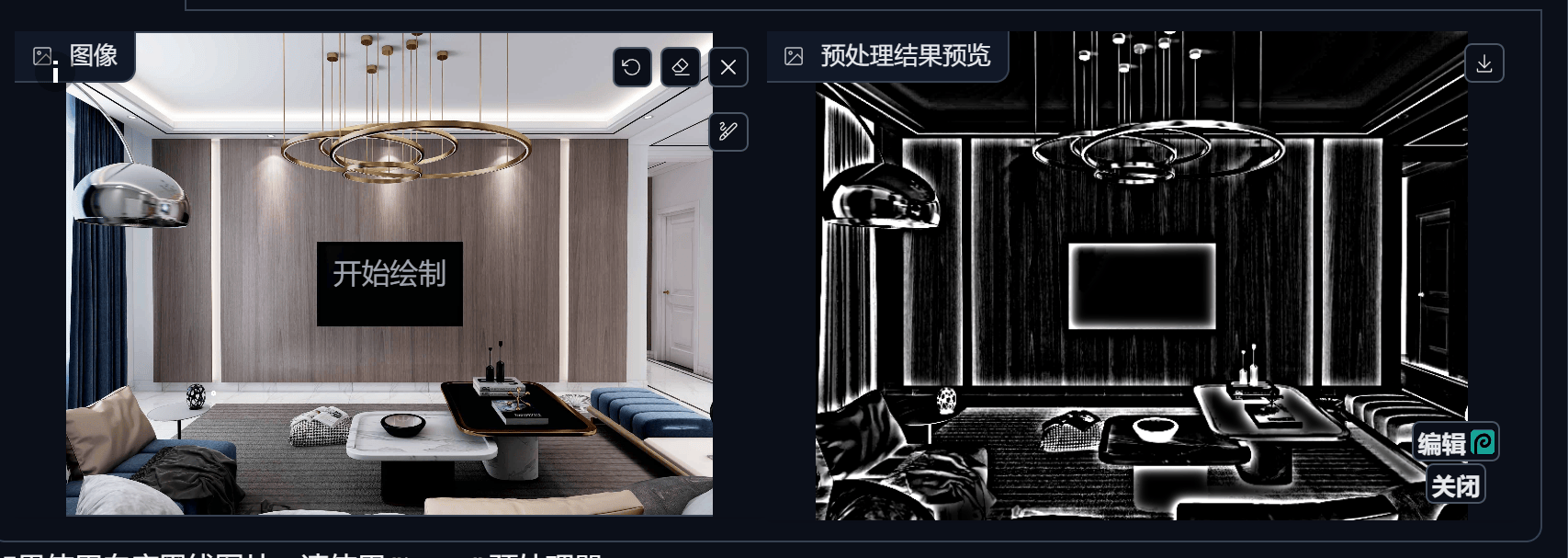
SoftEdge (软边缘)

Scribble/Sketch (涂鸦/草图)
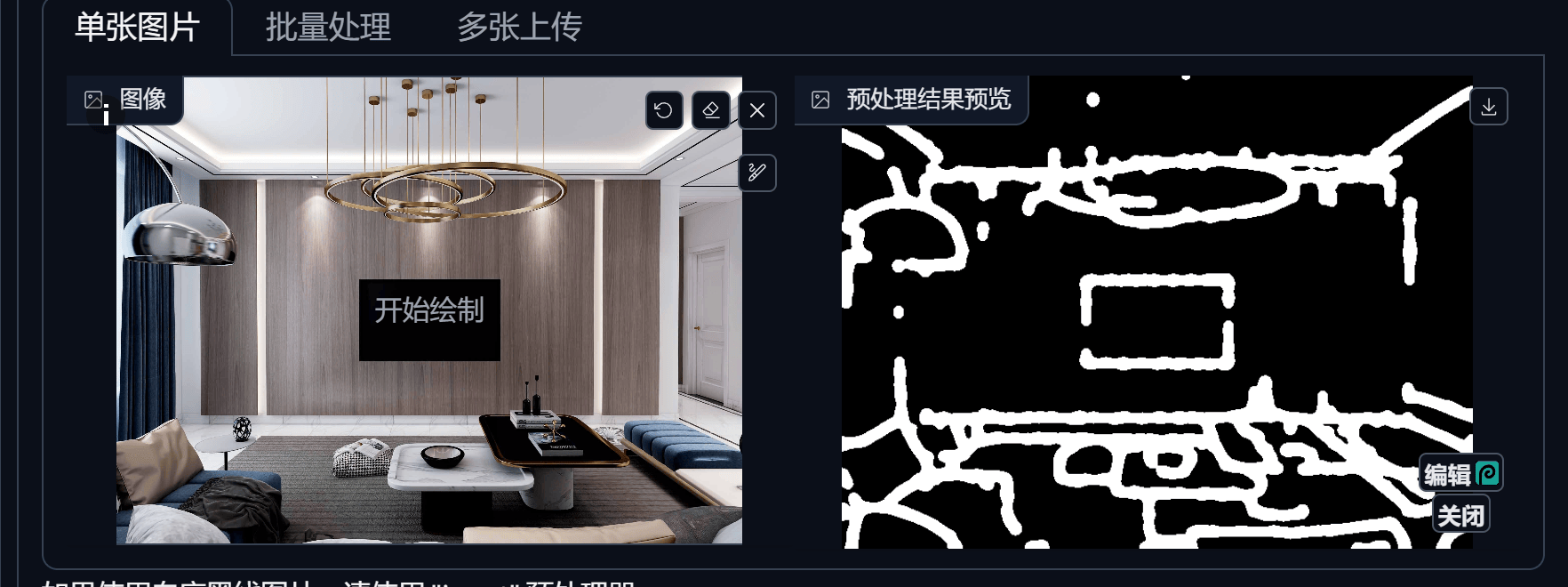
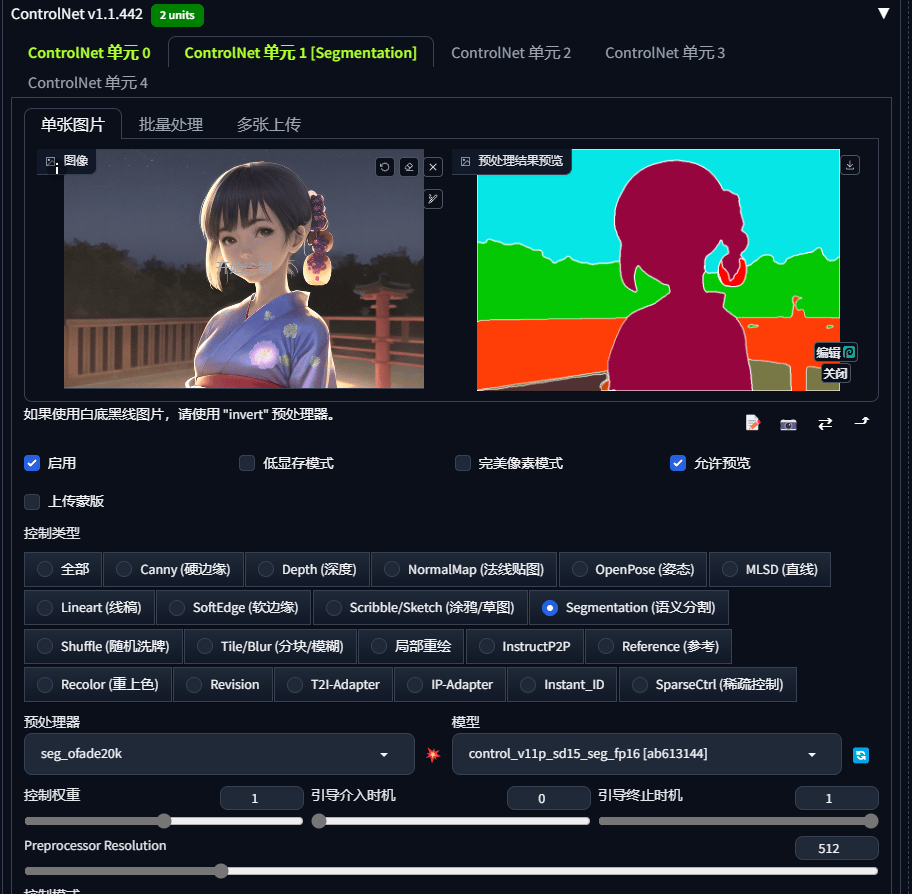
Segmentation (语义分割)
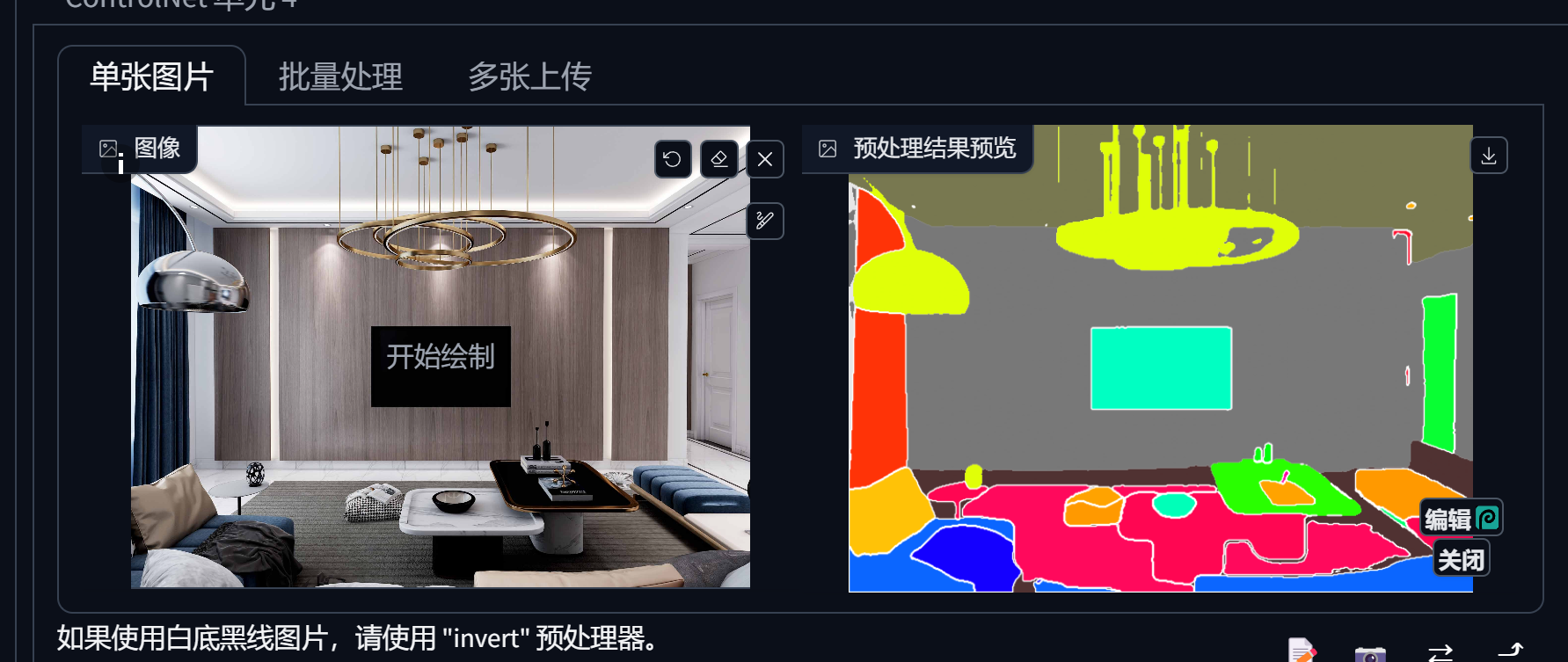
Shuffle (随机洗牌)

Tile/Blur (分块/模糊)
增加细节、减少细节

局部重绘
参数解释
蒙版边缘模糊度
蒙版区域内容处理
原图适用于大部分情况,(会参考原图的风格色调)潜在噪声适合凭空出现某个东西的情况
重绘区域
全图模式充分参考了原图,重绘出的汽车与原图融合的更好仅蒙版区域下边缘预留像素该参数越小,绘制细节越丰富,推荐:如果蒙版区域较小,需要局部修改,就可以适当调大参考半径,如果蒙版区域足够大,需要重绘足够的细节,则需要适当调小参考半径。
InstructP2P
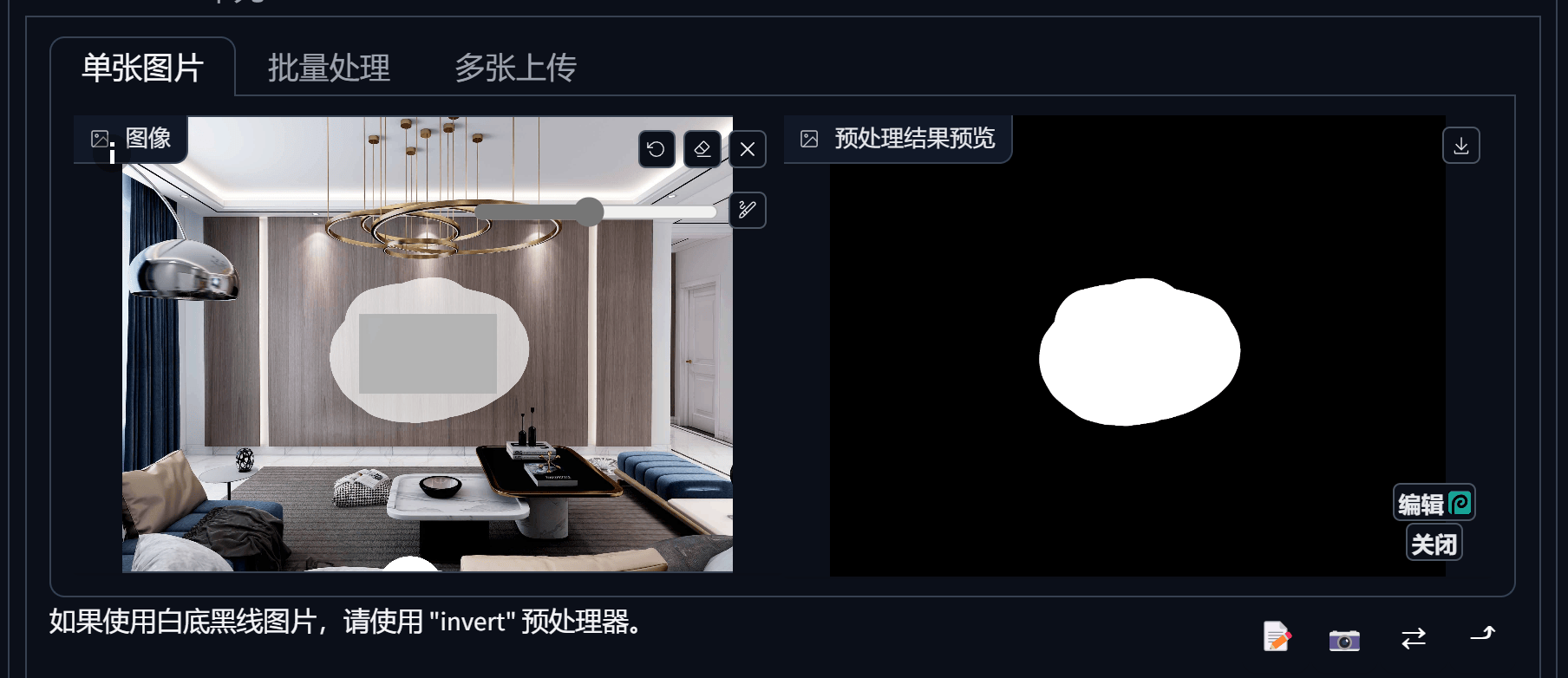
Reference (参考)
Recolor (重上色)
重新给图片上色
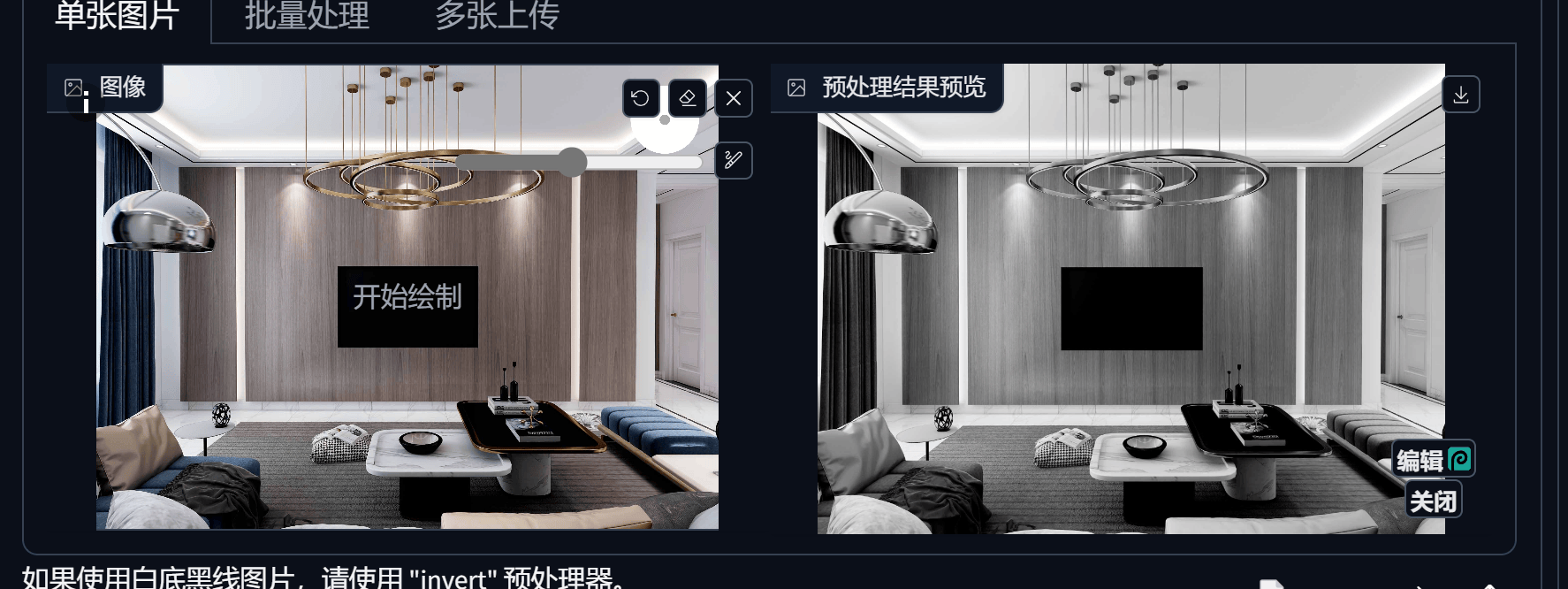
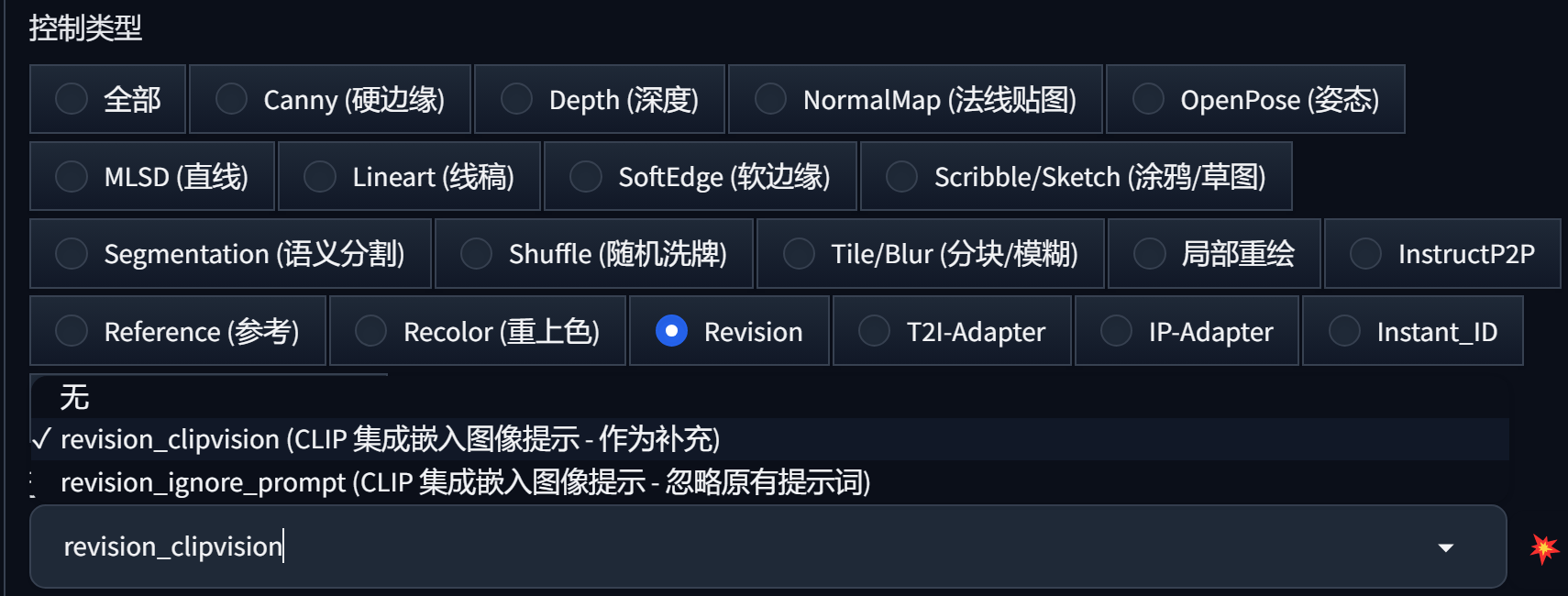
- Revision
只支持SDXL模型,功能解释:把图片当做提示词
共两种模式
- 把图片当做提示词作为文字提示词的补充
- 忽略文字提示词,完全把图片提示词当做提示词,
T2I-Adapter
IP-Adapter
Instant_ID
SparseCtrl (稀疏控制)
实操:给模特换腿换头
换腿:
局部重绘 + canny
换头:
局部重绘 + openopse + canny(权重可以适当降低)+ 提示词
衣服模型canny + 真人面部canny 在PS 中融合成新的 canny
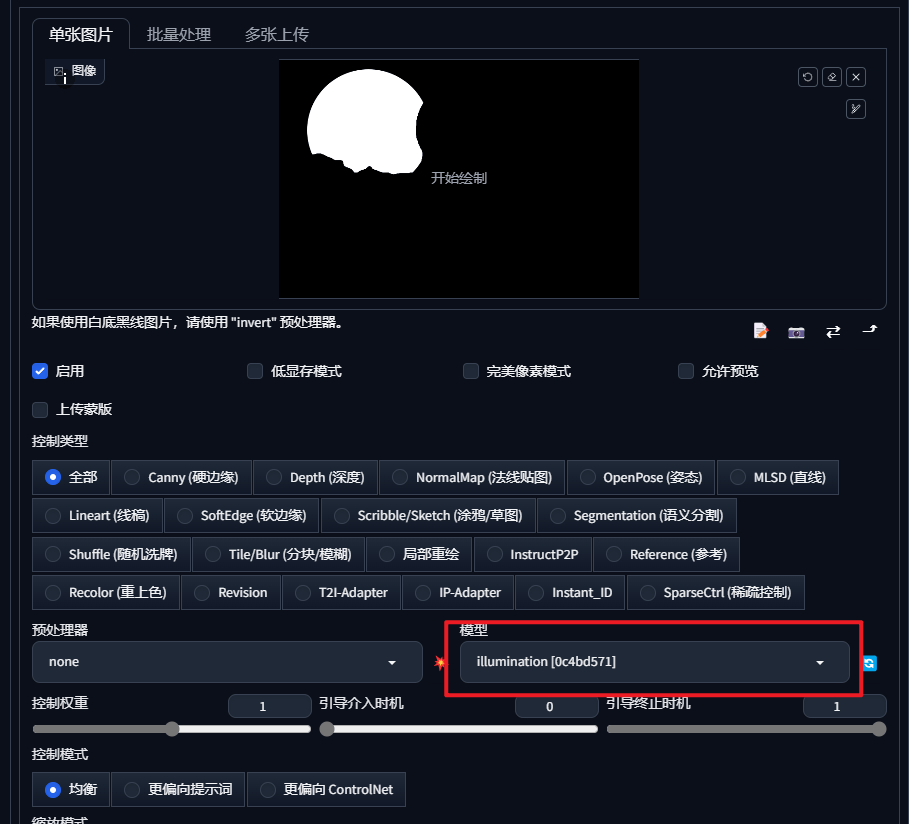
illumination(引导光影)
(Lighting based picture control controlnet - v1.0 | Stable Diffusion Controlnet | Civitai)
通过灰度图模板引导成图光影(灰度图模板需要自己制作)
生成图片
1 | (ultra realistic, best quality) ,perfect face, in japanese Yukata, night,sky,1 girl solo, |

制作蒙版(想加一个月亮)
1 | 增加提示词 |

选择CN
结果:

对比不同CN 权重 和 引导终止时机


结论:
① 由于上传的灰度图完全是黑白,因此如果
权重1,结束时机1,会出现过拟合现象;② 调整
权重和结束时机能够有效解决过拟合现象;③ 权重 和
结束时机的权重之和相同时,画面明暗相同;④
权重的大小会影响构图;但是结束时机不会
FaceSwapLab(换脸)
安装好后再 文生图、图生图、扩展栏、均有FaceSwapLab
案例:
把图1人脸换到图2
图1:

图2:

选择图生图:
结果

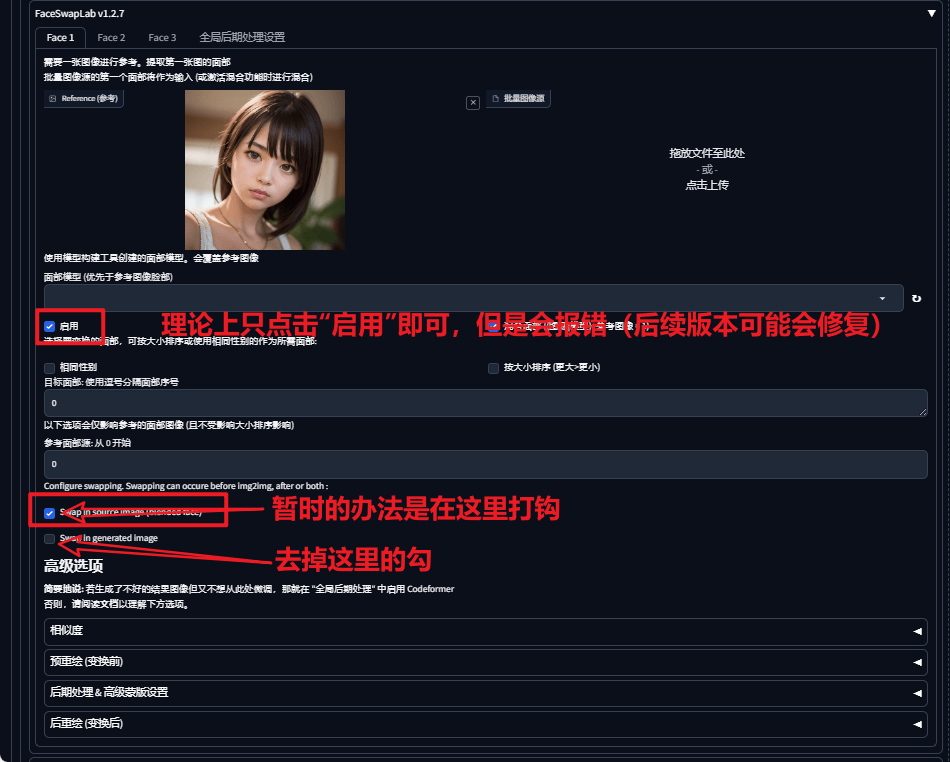
高级功能:
这里可以设置训练的面部(可以自己训练,在插件页的FaceSwapLab中训练或上传到指定文件夹即可)
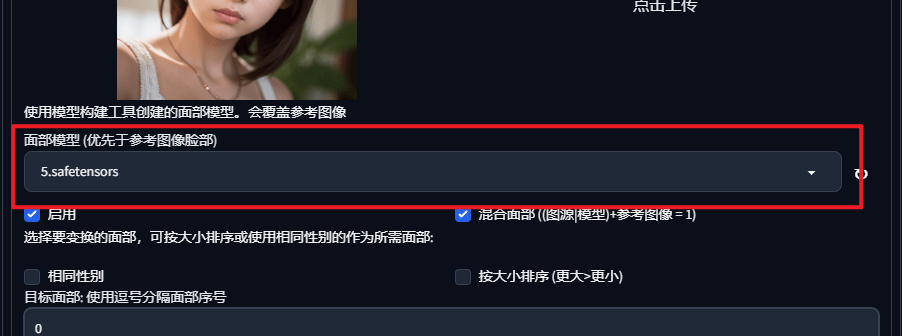
实验结果表示 模型换脸 和 直接reference换脸 没啥区别

如果遇到一张图片多张脸,可以在这里选择人脸序号

高级选项里的

相似度:根据参数,选择是否丢弃换脸结果
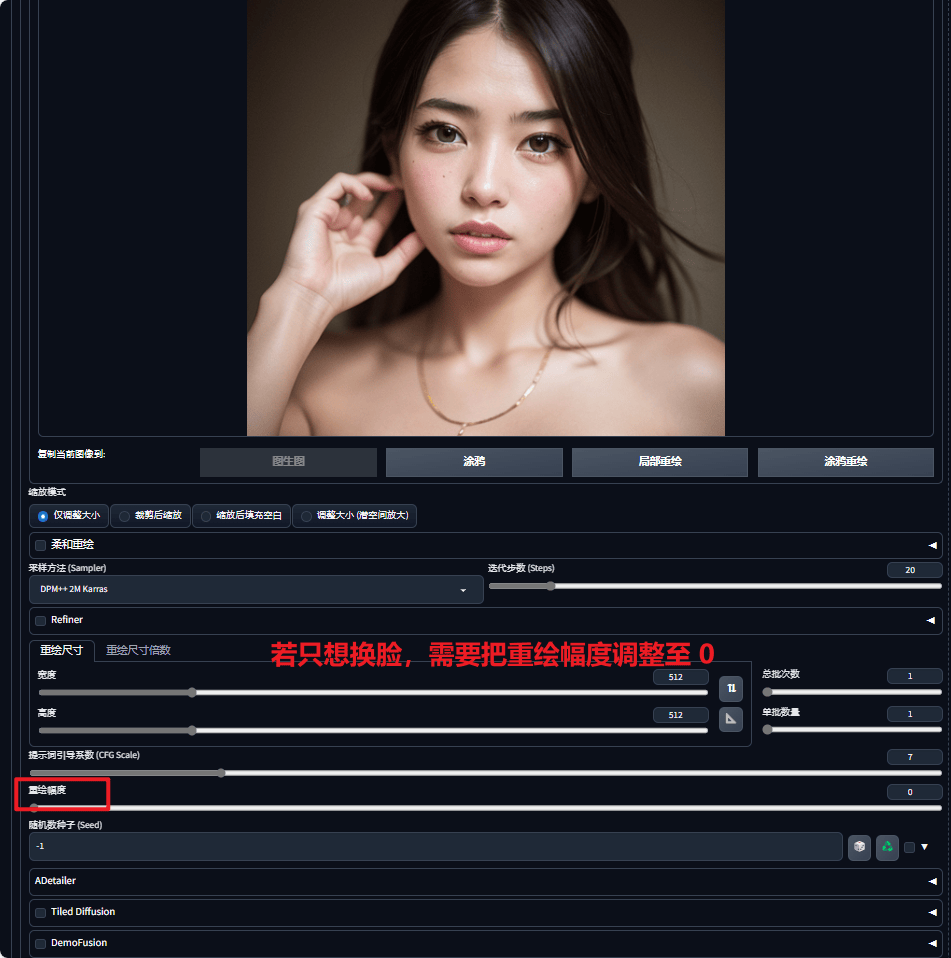
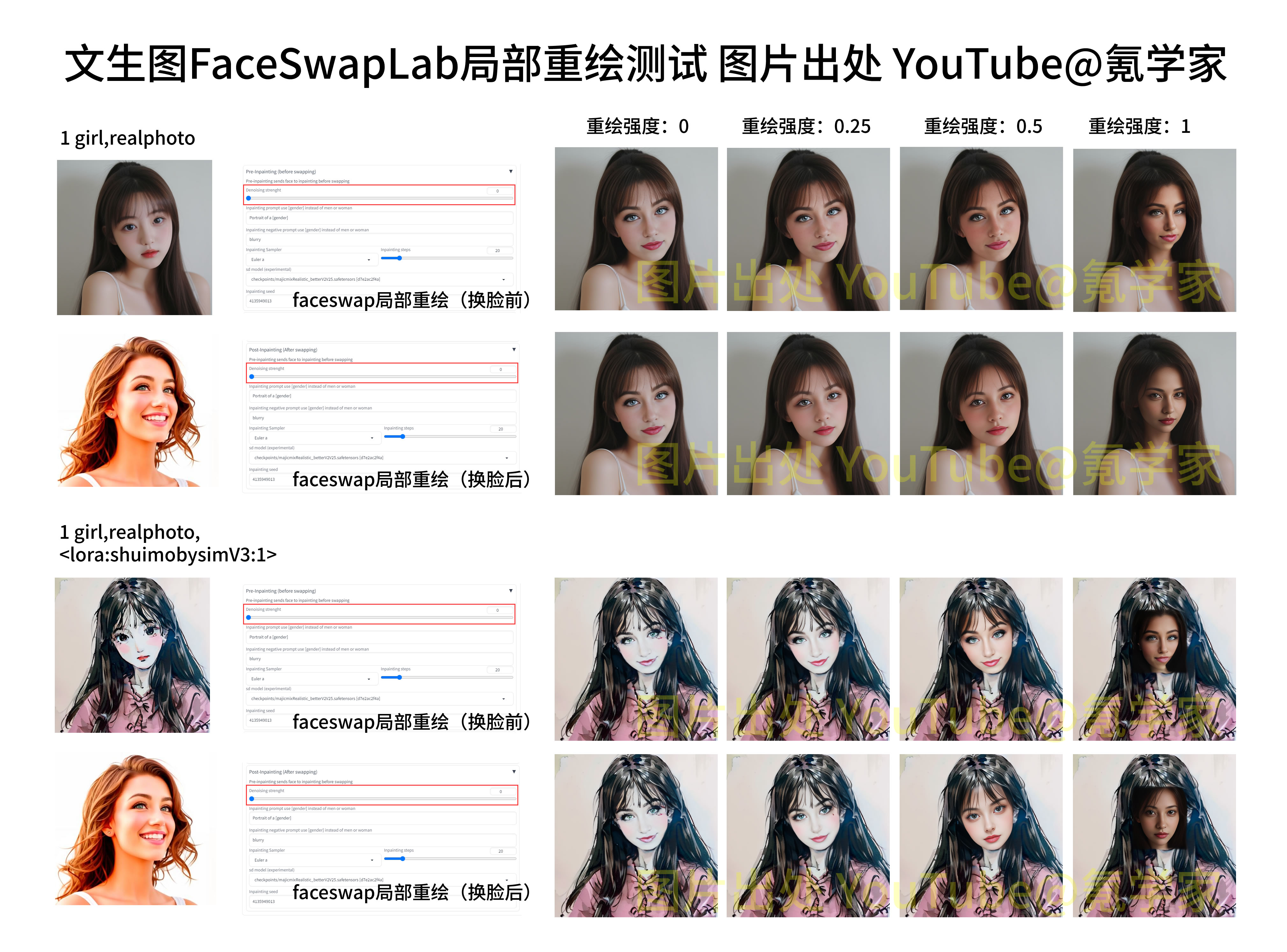
预重绘(变换前):调整两张脸融合效果(具体对比见下图,推荐重绘幅度参数
0.3左右)后期处理: 增加细节、提高分辨率,修正肤色等
预重绘(变换后):调整两张脸融合效果(具体对比见下图,推荐重绘幅度参数
0.3左右)

插件其他功能
构建:提供多张照片以构建一个人脸保存成特定文件供更频繁方便的使用
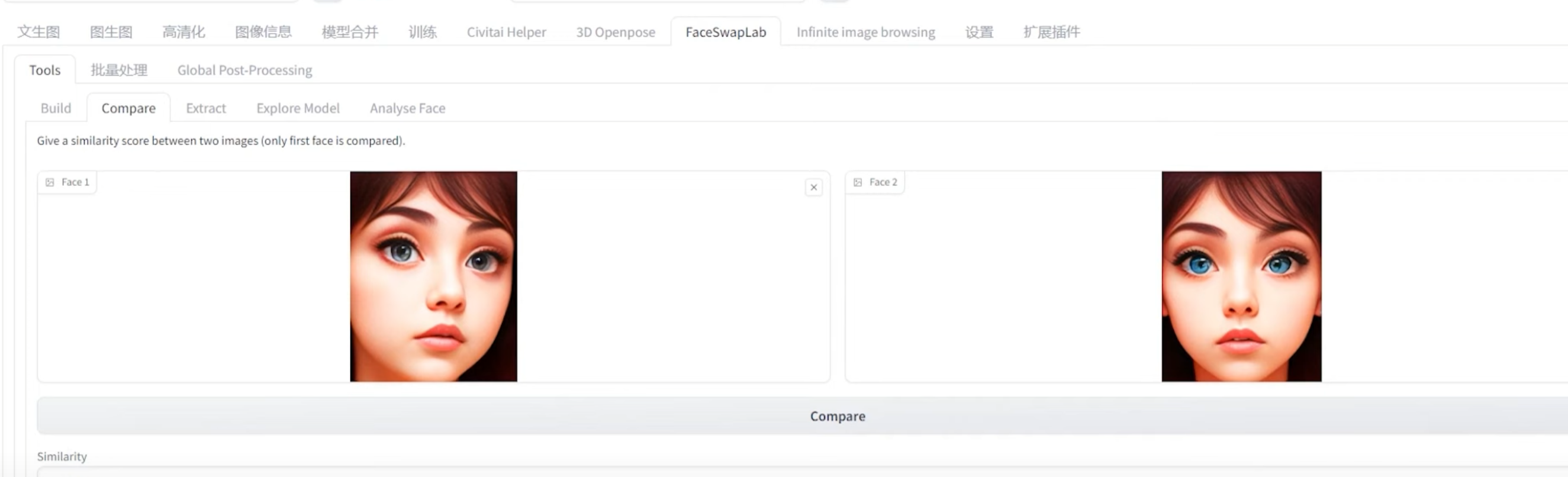
比较人脸,给出结果百分比:
提取:把一张照片里的所有人脸提取出来
分析面部:
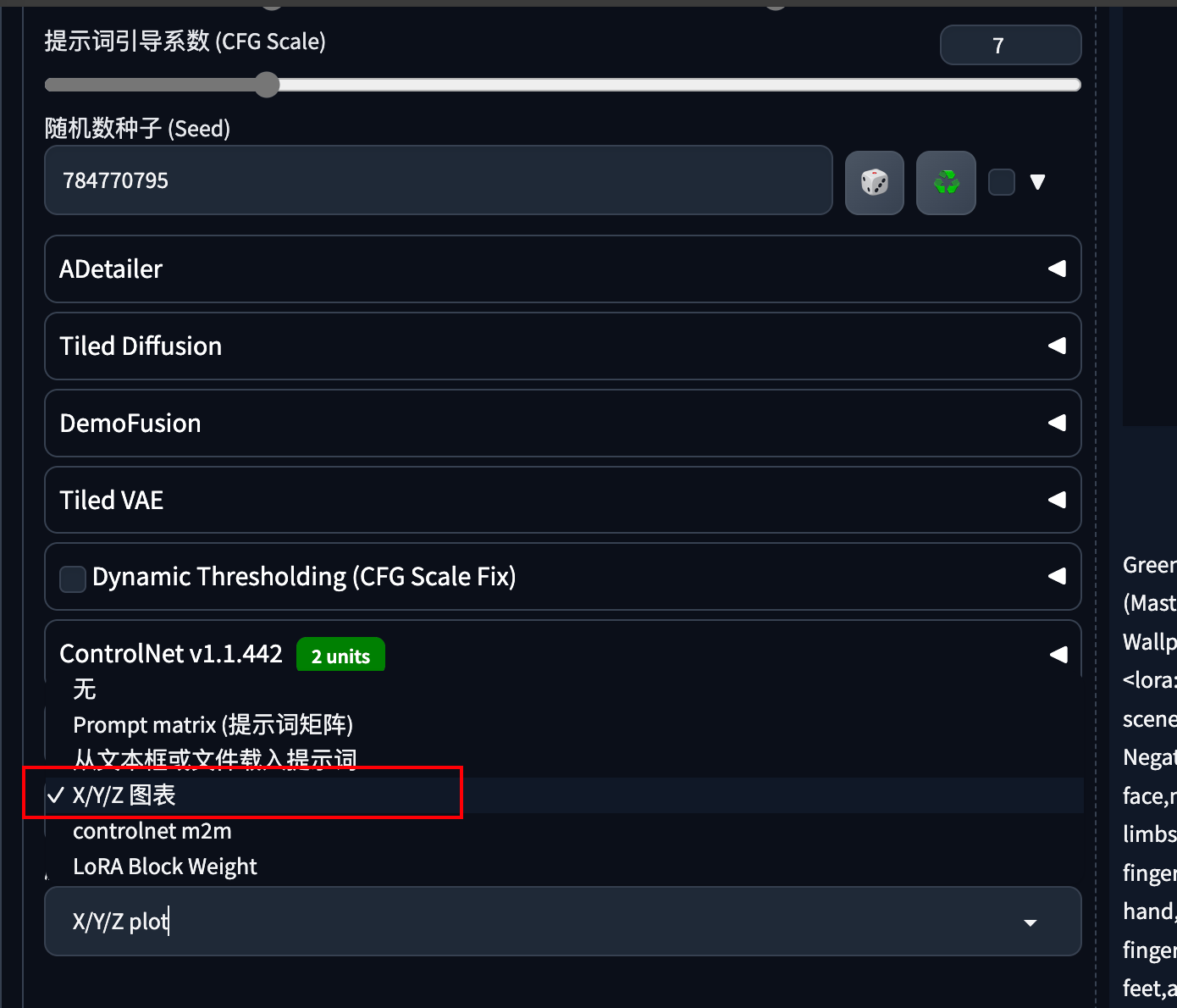
6 X/Y/Z 图表
XYZ图表是以三个轴来对比不同设置【参数、模型等】
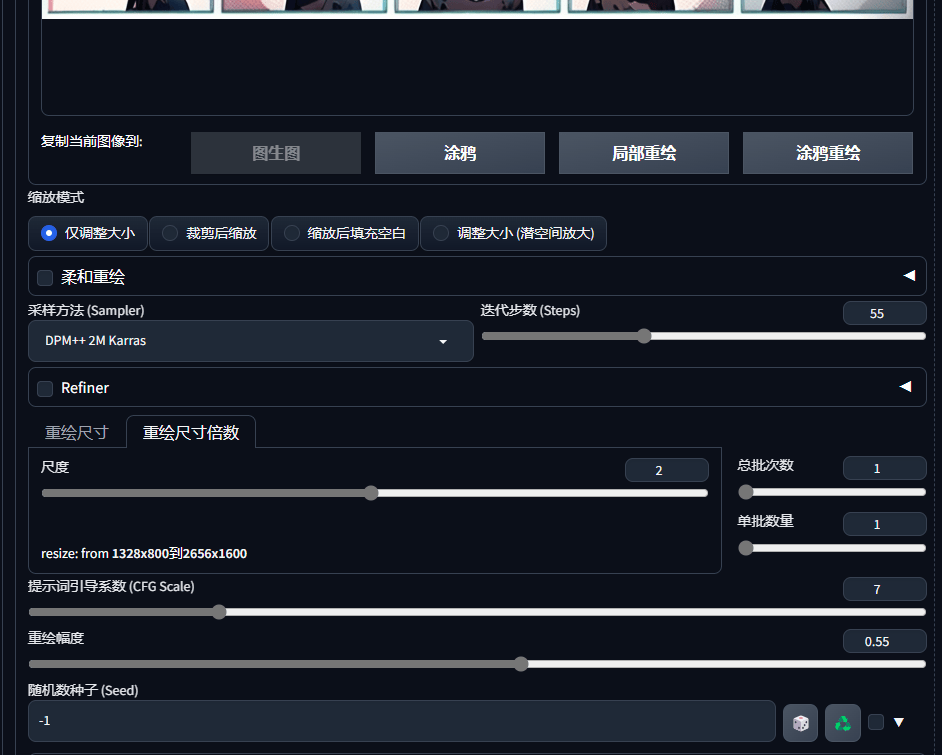
7. 高清化放大
共有三个地方有高清化,分别在 文生图、图生图、单独的高清化
结论:
R-ESRGAN 4x+ 和 R-ESRGAN 4x+ Anime6B 适合动漫风
ESRGAN_4x 适合真人
LDSR算法耗时长,细节效果好,但是人面部会有”假滤镜“,整体会略微偏黄(可PS白平衡拉回)
ScuNET、ScuNET PSNR、SwinIR_4x 适合降噪处理
放大方式:
方案一:
直接用“后期处理”里的工具完成。
方案二:
提示词:原提示词反推+增加提示词
Best quality,Photorealistic,Raw Photo模型选择:Realistic Vision V5.1
重绘幅度:0.4
Tiled Diffusion:① 启用+MultiDiffusion+R-ESRGAN 4x+ ② 取消勾选输“保持输入图像大小”③放大倍率
ControlNet:启用+ Tile+完美像素
8. Inpaint Anything
狭义上讲,是个快速抠图工具
应用: 保留衣服,控制
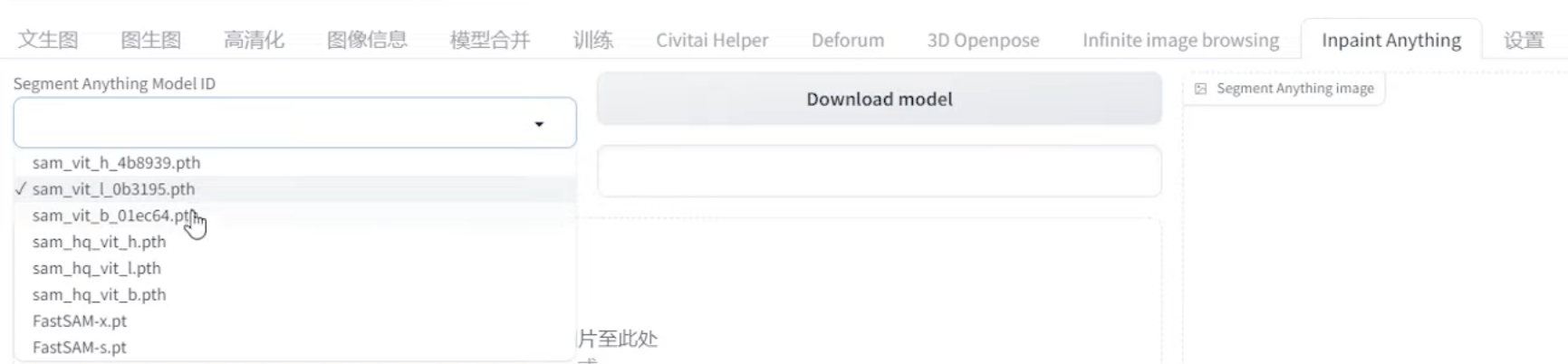
sam_vit_h_xxx.pthHuge 体积最大sam_vit_l_xxx.pthLarge 较大sam_vit_b_xxx.pthBase 体积最小
体积越大理论效果越好,但越吃资源
使用方法
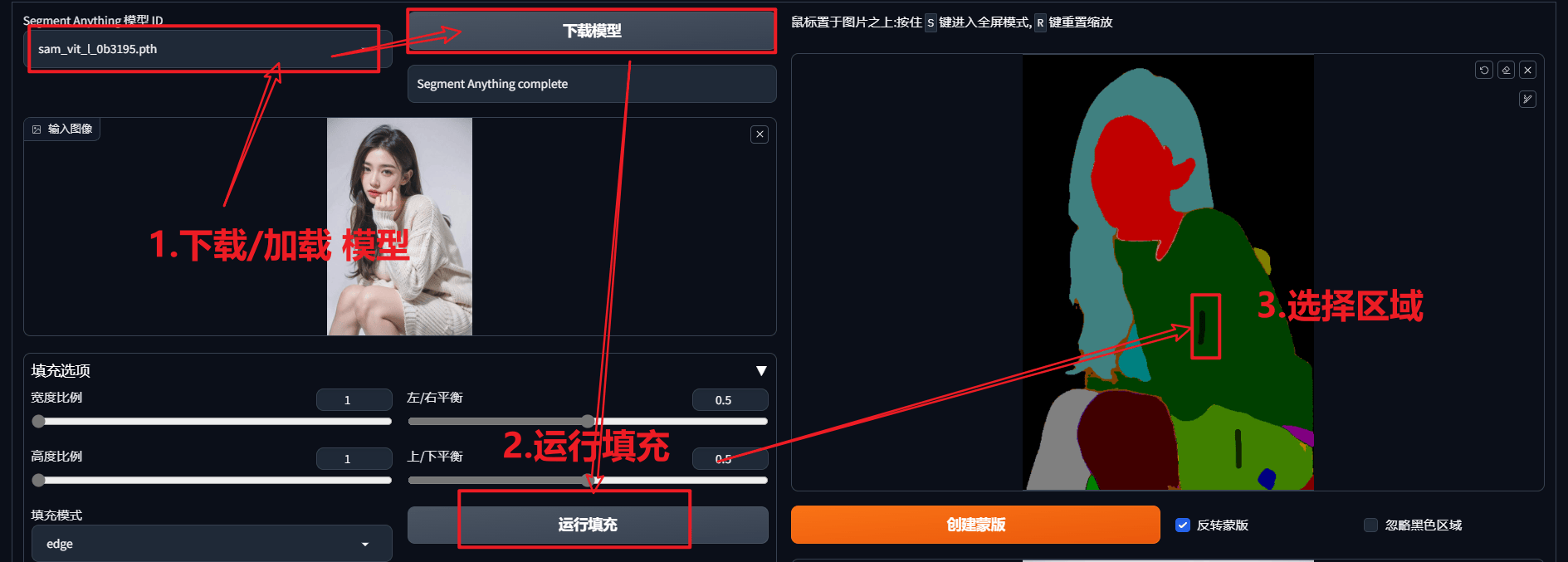
选择区域:【灰色是保留部分】选择的是不想保留的区域,如果需要,可以反转蒙版
功能1:重绘
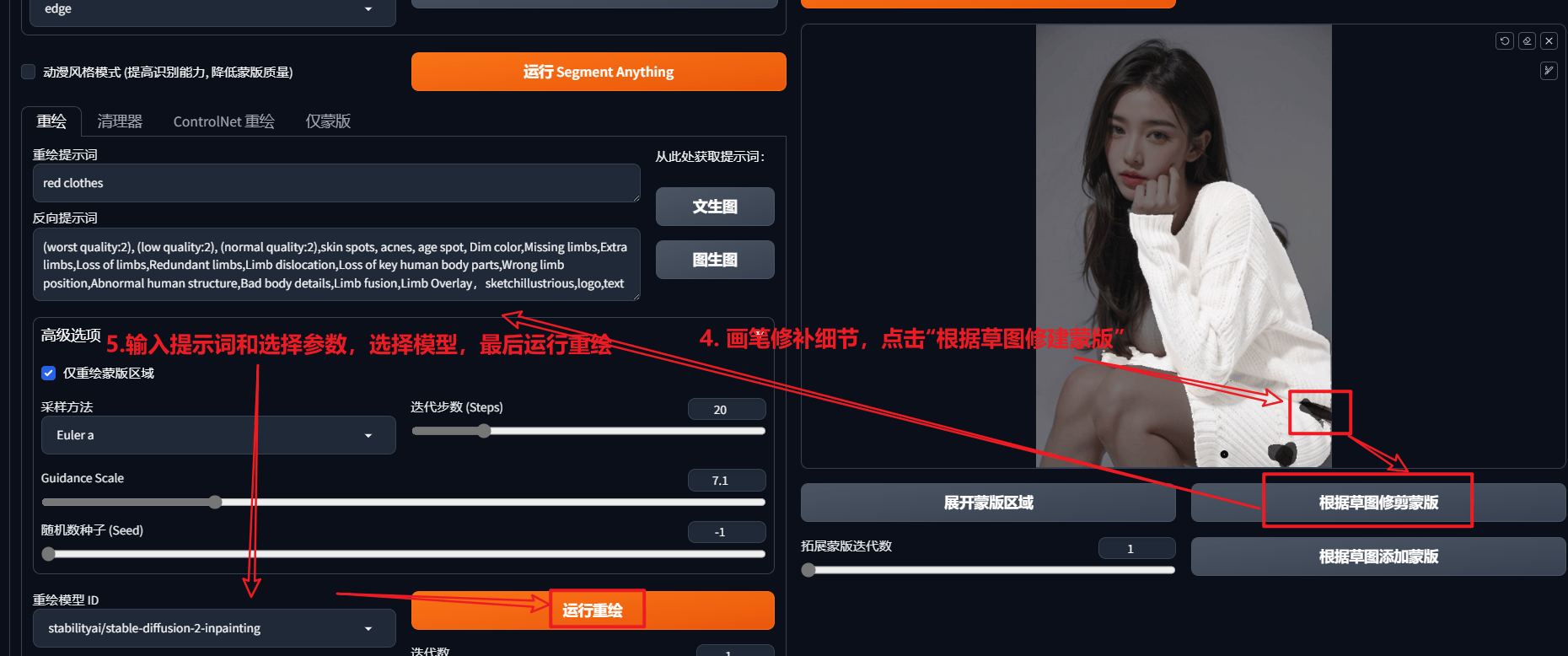
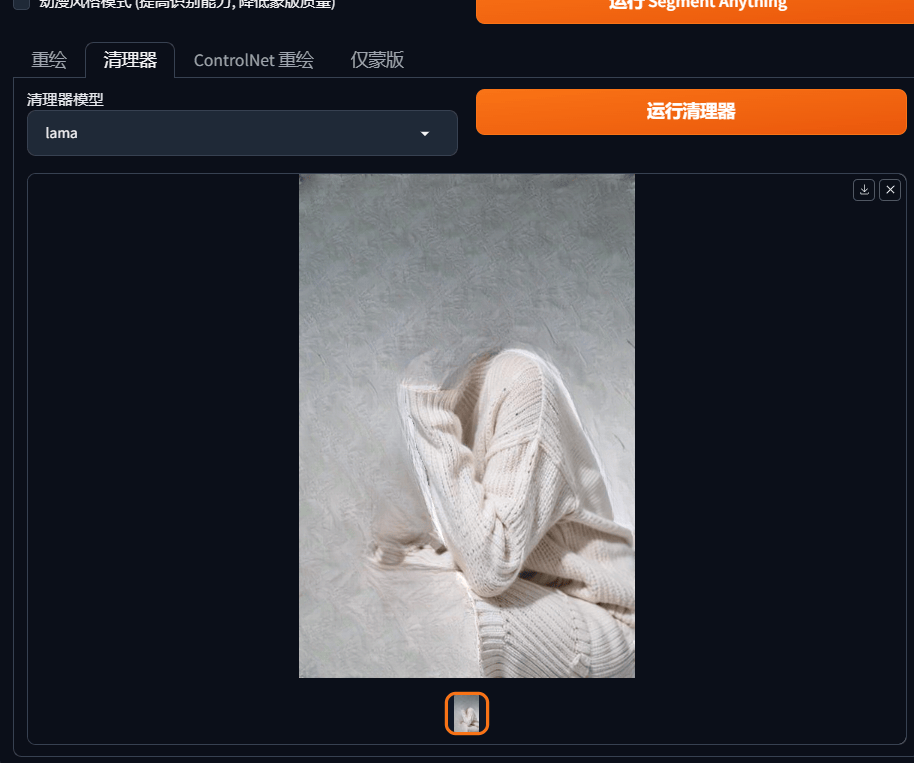
功能2:清理器
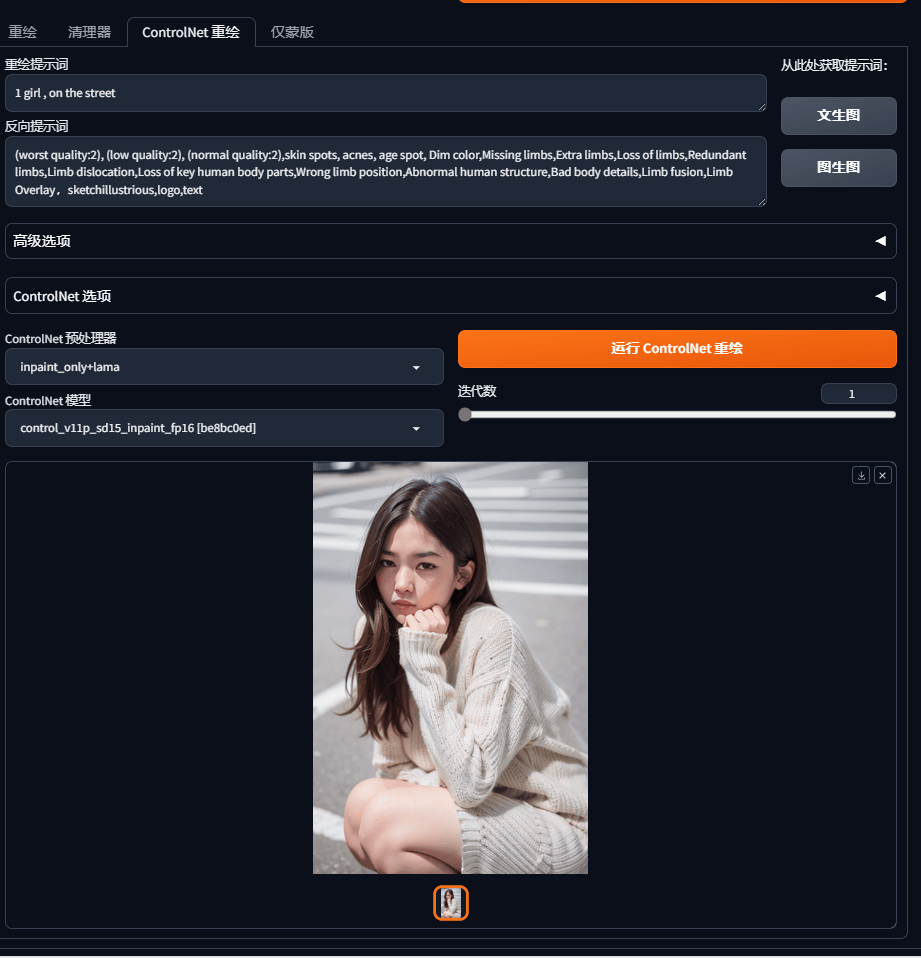
功能3:
ControlNet重绘
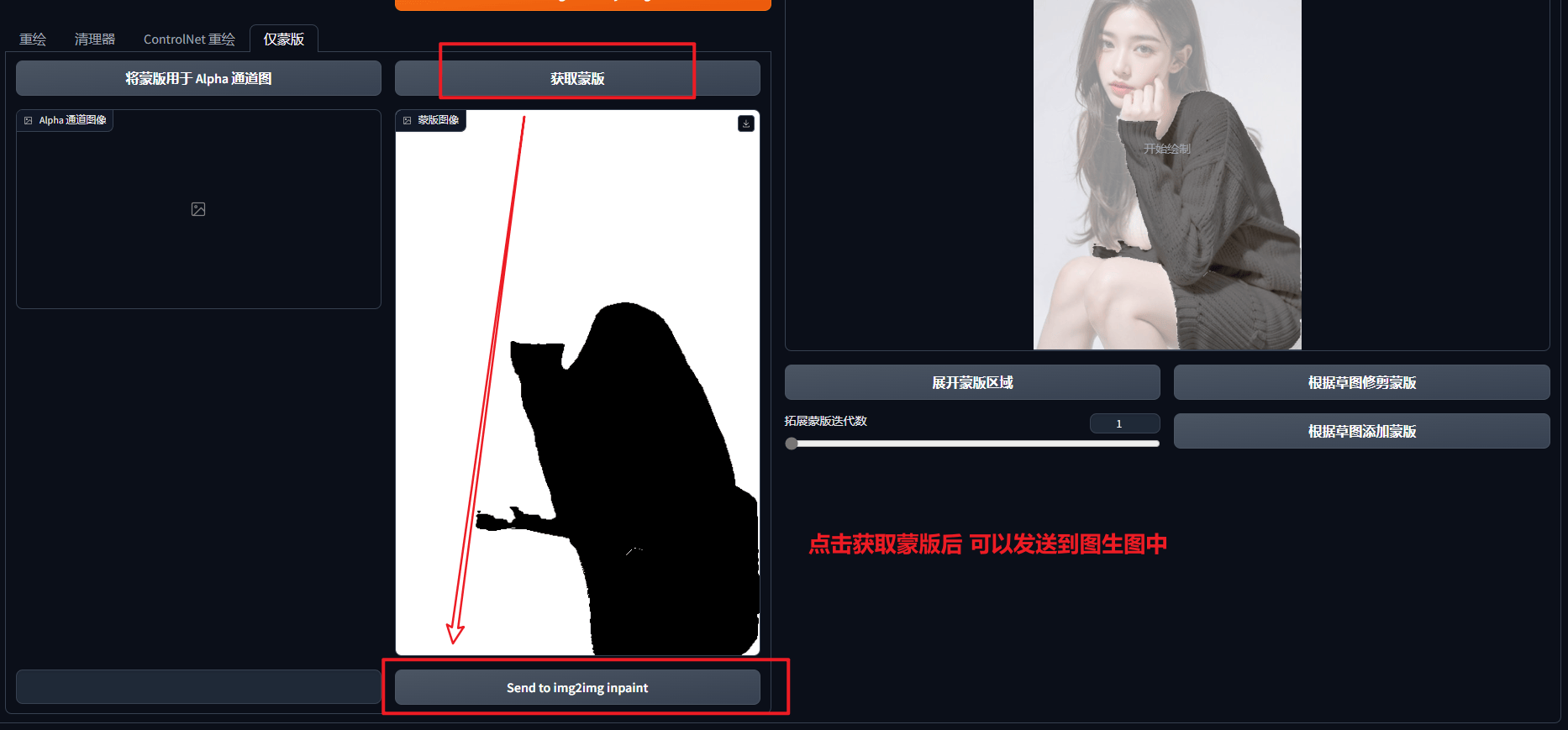
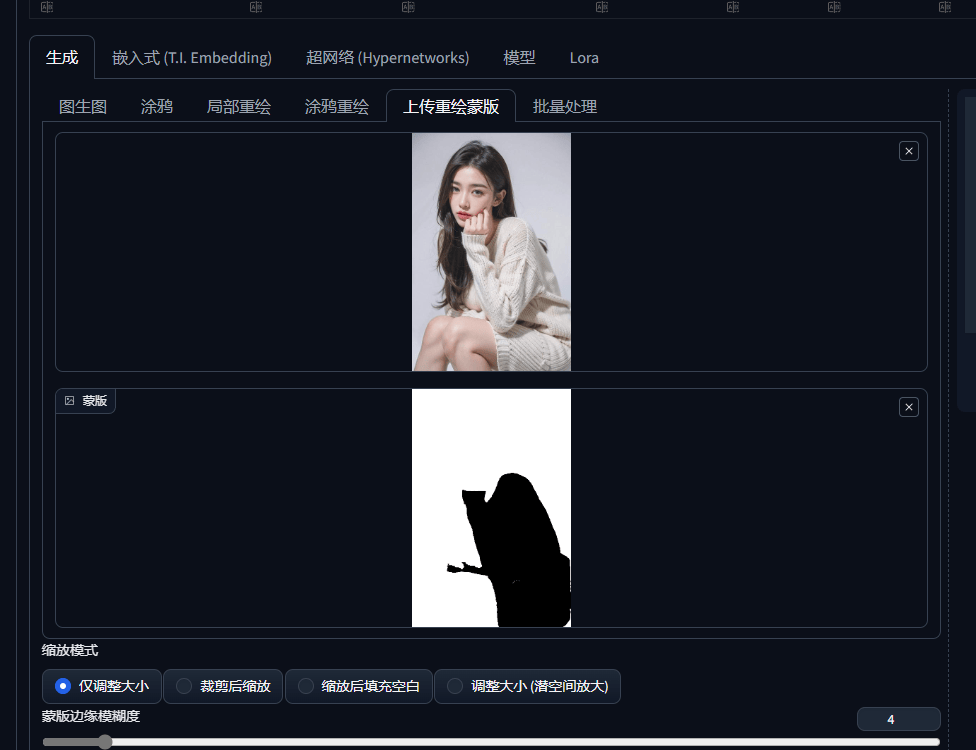
功能4:仅蒙版

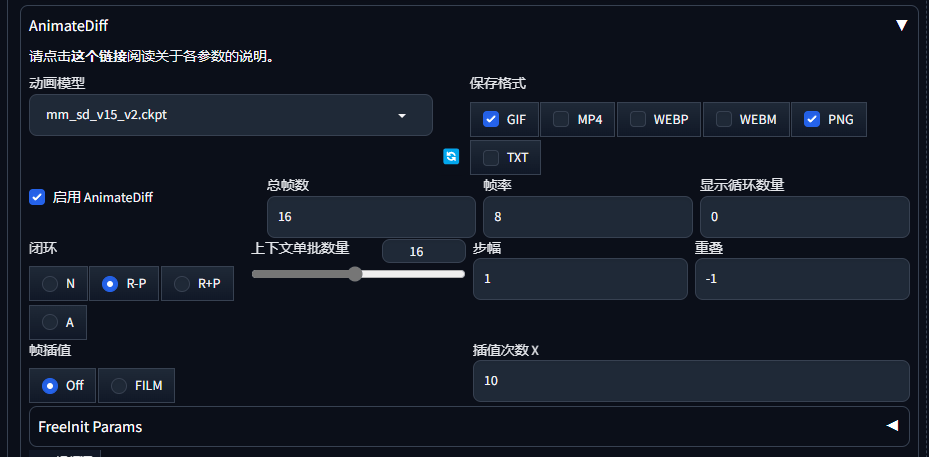
9. AnimateDiff GIF插件
[animatediff 插件地址](GitHub - guoyww/AnimateDiff: Official implementation of AnimateDiff.)
生成动画
推荐模型:toonyou
生成文件地址:
outputs/txt2img-images/AnimateDiff下
10. 应用
10.1 海报制作
先制作好文字底 ,黑白,然后使用 canny + depth 和适合风格的模型 + LORA ,刷图即可

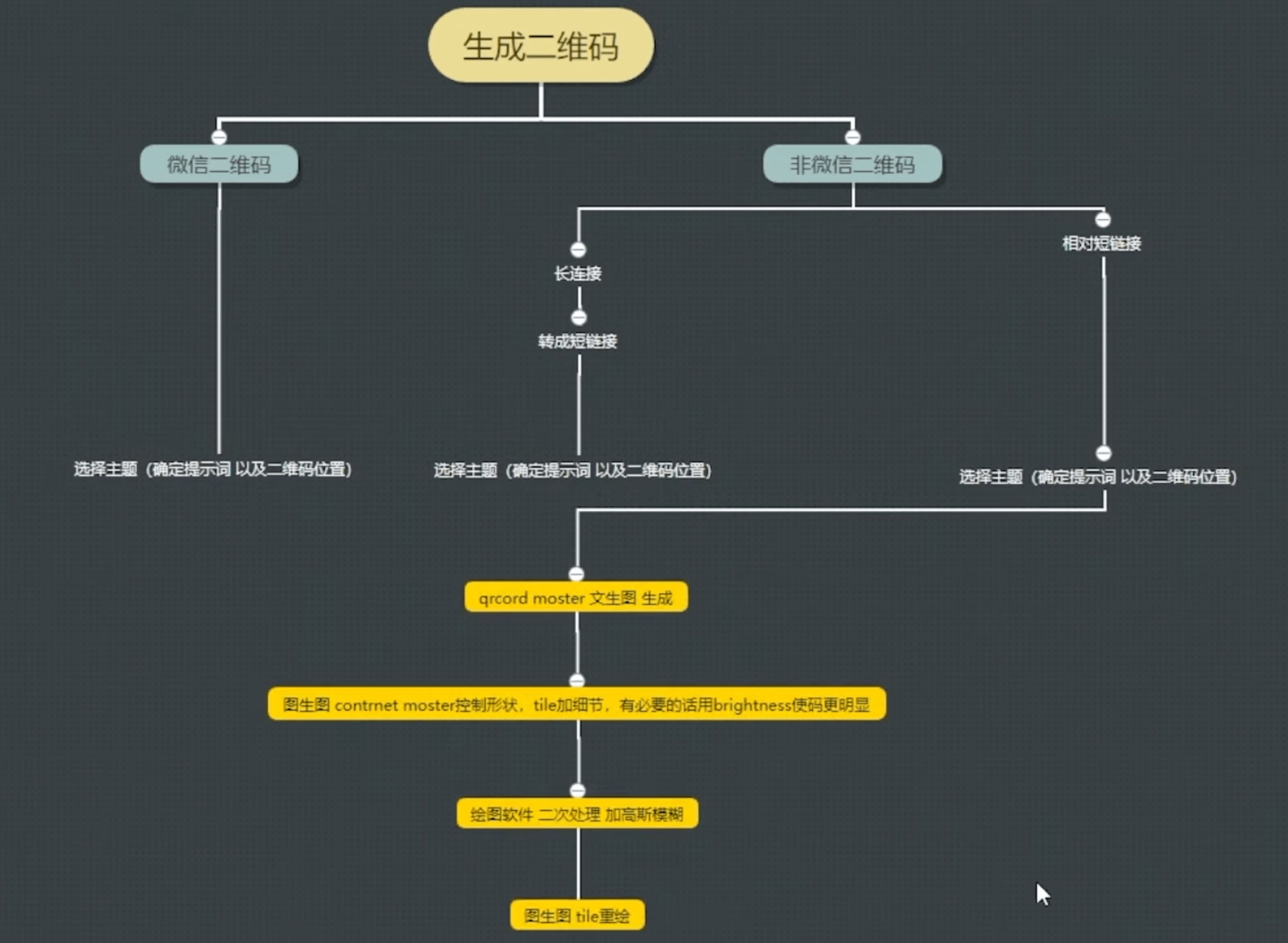
10.2 二维码美化
本质上
二维码制作工具:https://qrcode.antfu.me/
二维码解码:https://jiema.wwei.cn/
所用到的模型:
tile:https://huggingface.co/lllyasviel/con...
qrcord-monster:https://huggingface.co/monster-labs/c...
Brightness Control:https://huggingface.co/ioclab/ioc-con...
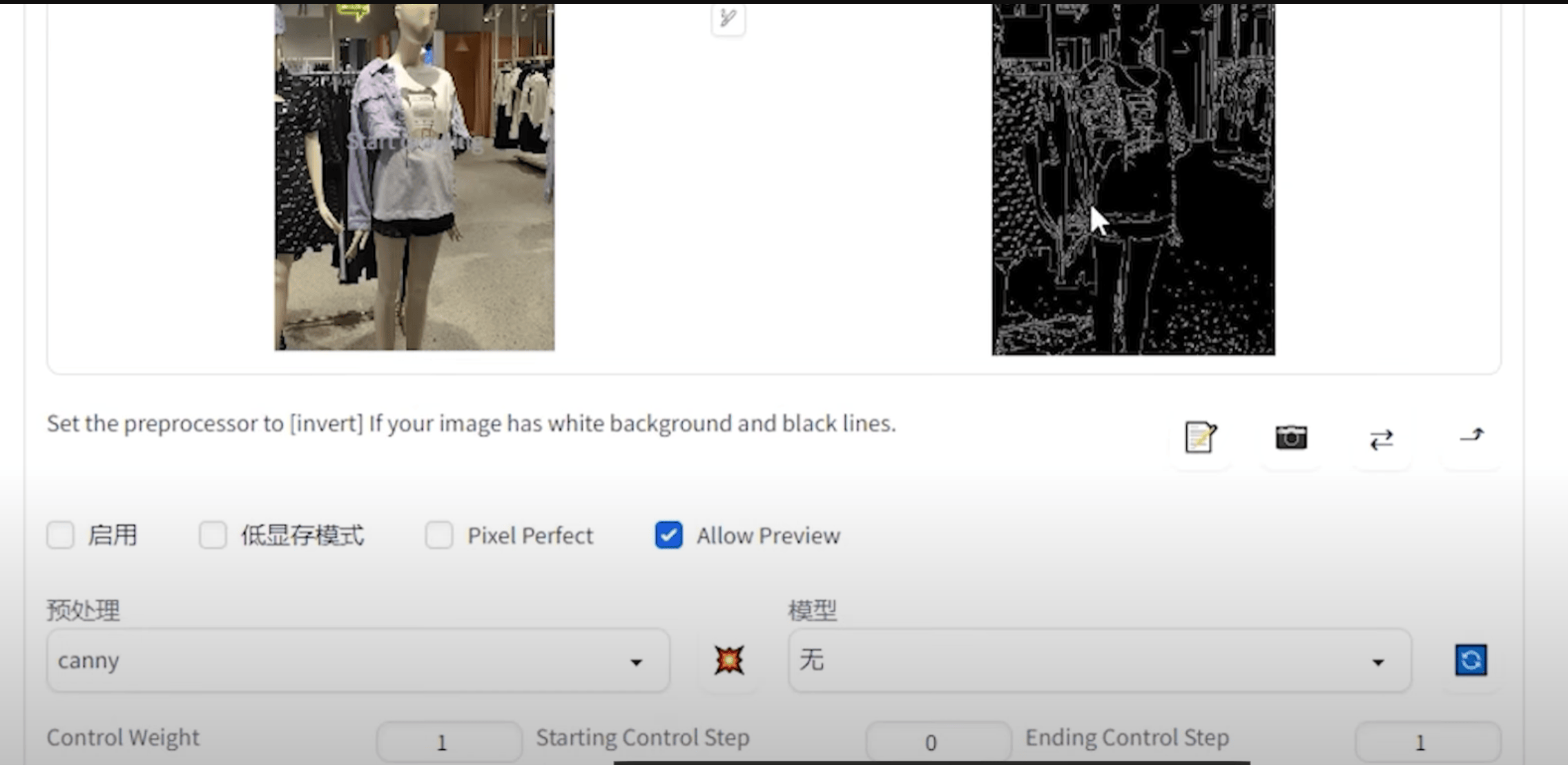
10.3 电商换装
① 换腿:不需要描述词,局部重绘即可
② 换脸:局部重绘,canny,openpose,(看情况加Prompt)
③ 完美颜值:理想人脸图 canny 处理 + 叠加覆盖到原canny图脸上,脸上局部重绘,(看情况加Prompt)
① 换腿:不需要任何提示词


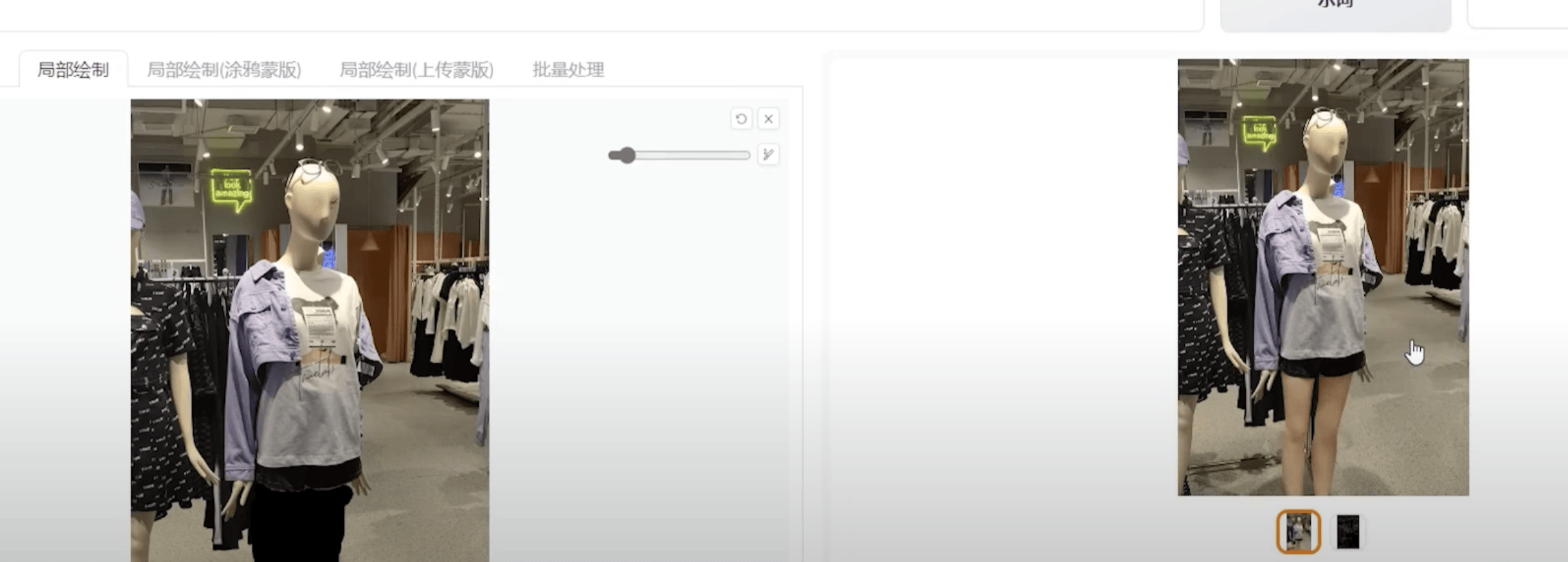
② 上一步基础上换头



③ 调整人脸朝向

④ 完美颜值


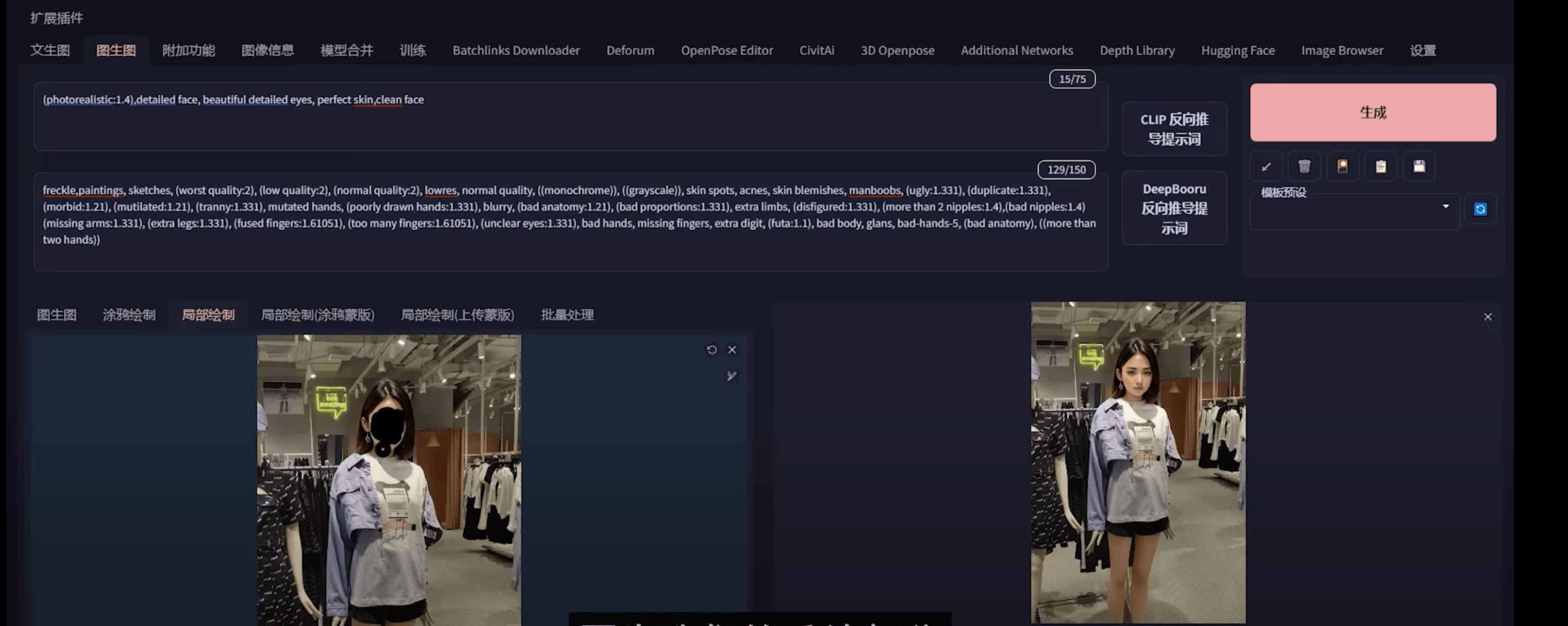
10.4 老照片上色
黑白照片——>(图生图)Lineart 做底 + 局部颜色描述词 ——> 新照片
局部变色——> (图生图)局部重绘+Lineart 做底 + 局部颜色描述词 ——> 新照片
实验发现:Lineart 比 canny 模型效果要好一点
CN里的Recolor也是很好的一个上色方式
10.5 拓图
(图生图) ① CN局部重绘 ,缩放模式选择:填充;② 图片尺寸:大一些,然后缩放模式选择:填充
(不想写提示词:控制模式选择:以CN为主)
局部重绘 inpaint 模式对比:
inpaint_only_LAMA细节更好一点;
Inpaint global harmonious 除了会修改模板部分,还会修改给其他地方细节做一些修改

10.6 动图制作
方法1:AnimateeDiff插件
方法2:提示词权重控制 [1man:Joker:0.2] + x/y/z 图表 + 剪辑软件变成GIF

测试边界:0.02
0.46和0.47结果是一样的,也就是等差数列公差至少0.02
10.7 IP 制作
多角度人像 用来训练 LORA ——> 达到角色统一的目的
使用这两个图片作为CN模板
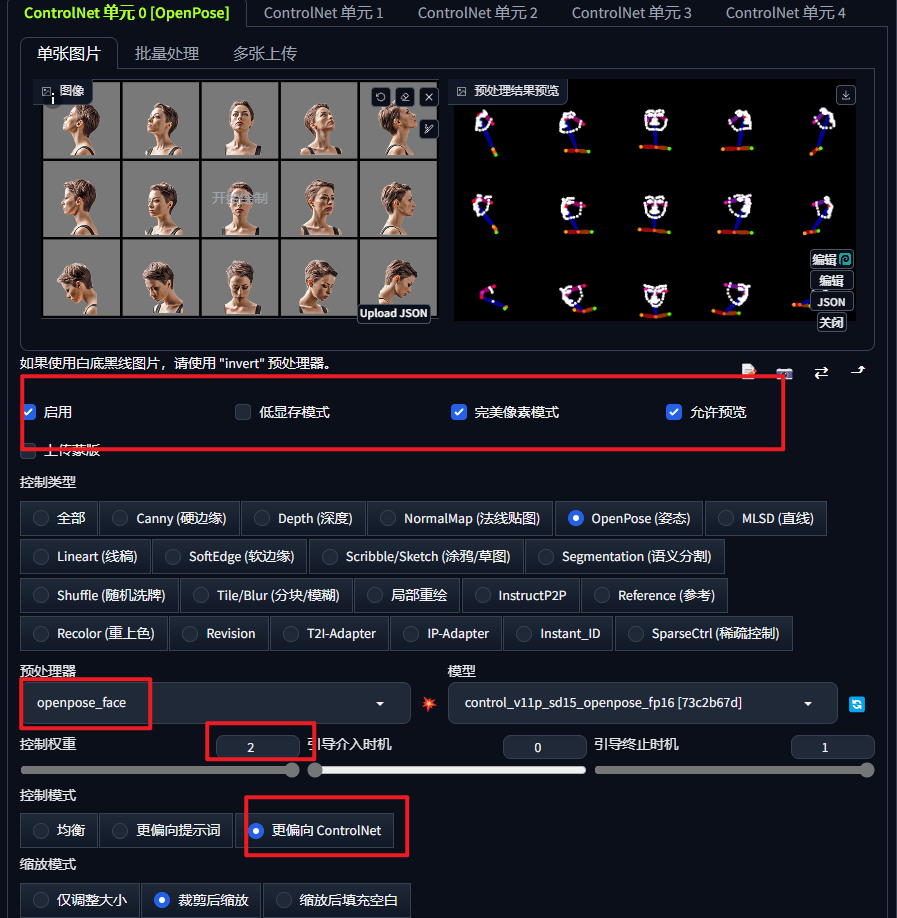
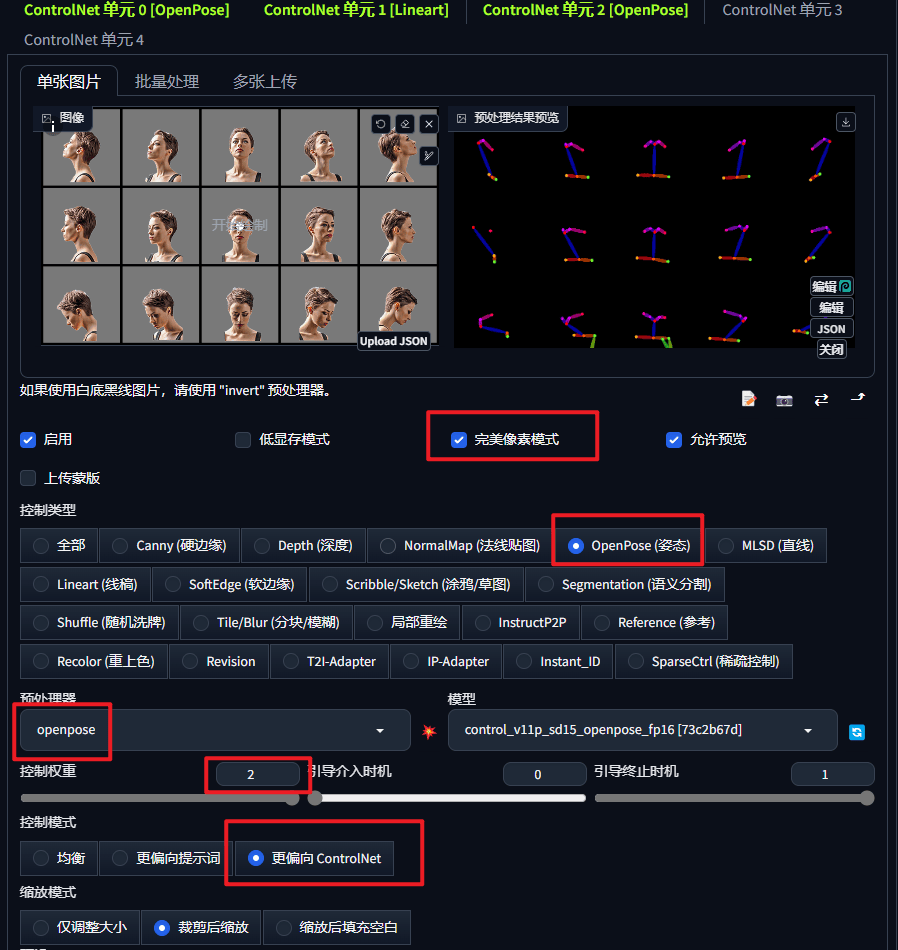
① 用来 Openpose 控制面部朝向

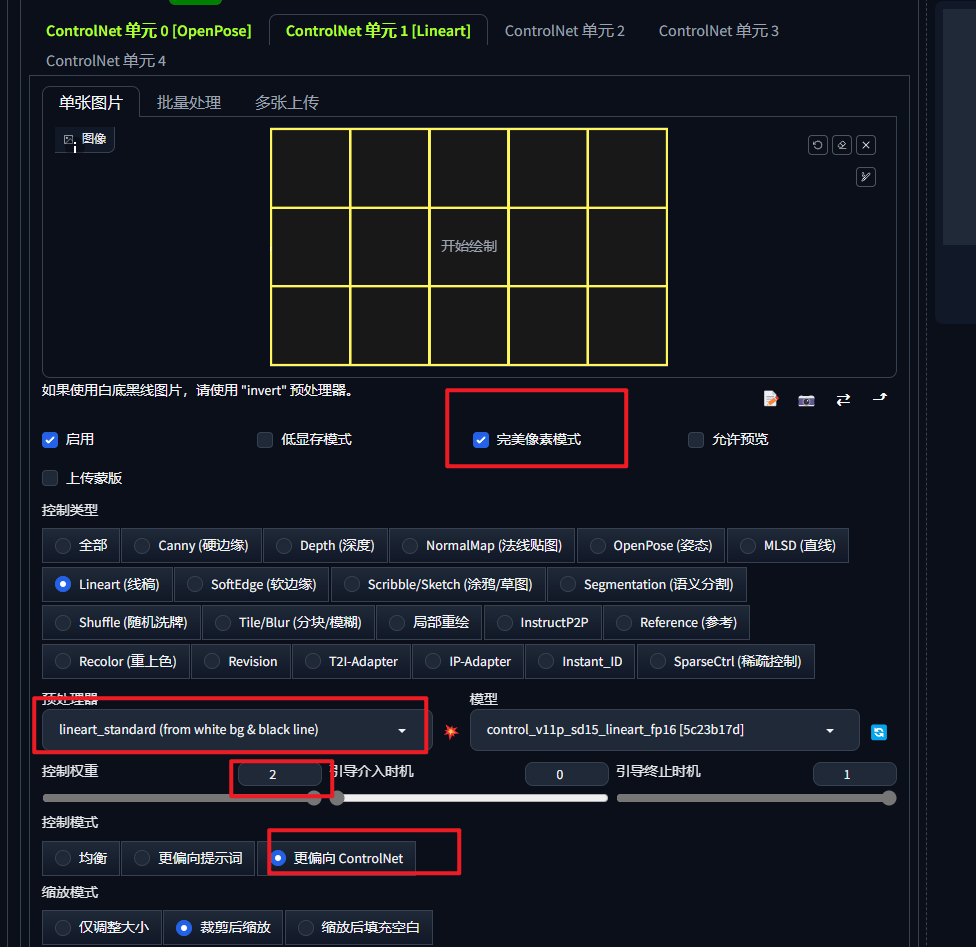
② 用 Lineart 区分分区

1 | # 提示词参考 |
原理解释:
用 Openpose 控制出图姿势,来获取到360度角色样貌
用 Lineart 和 Prompt 告诉SD 需要的图片
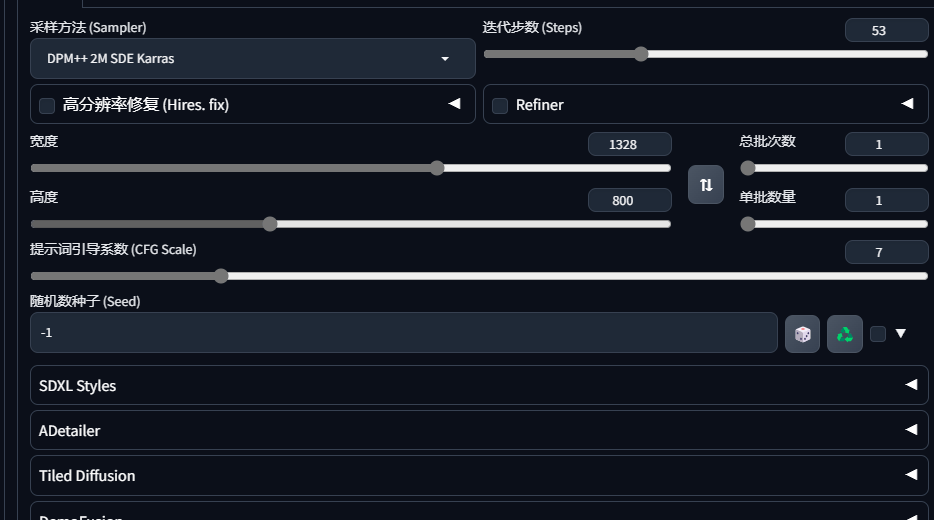
使用同款模板,推荐图片的比例为
1328*800(和黑色方框分割图大小一致),这样生成后的图片为矩阵中每个图片256*256,需要放大到512*512会比较适合训练 LORA;
点击生成

通过 图生图 中的 图片放大 +CN的Tile模型 放大和补充细节即可, 推荐放大模型 E-XXX 4x+
10.8 换脸
方案一: IP-Adapter(效果一般)
方案二:Openpose 【上面 3.5 有介绍】
方案三:FaceSwapLab 插件 【上面 3.5 有介绍】
10.9 同人同景、不同角度
步骤:
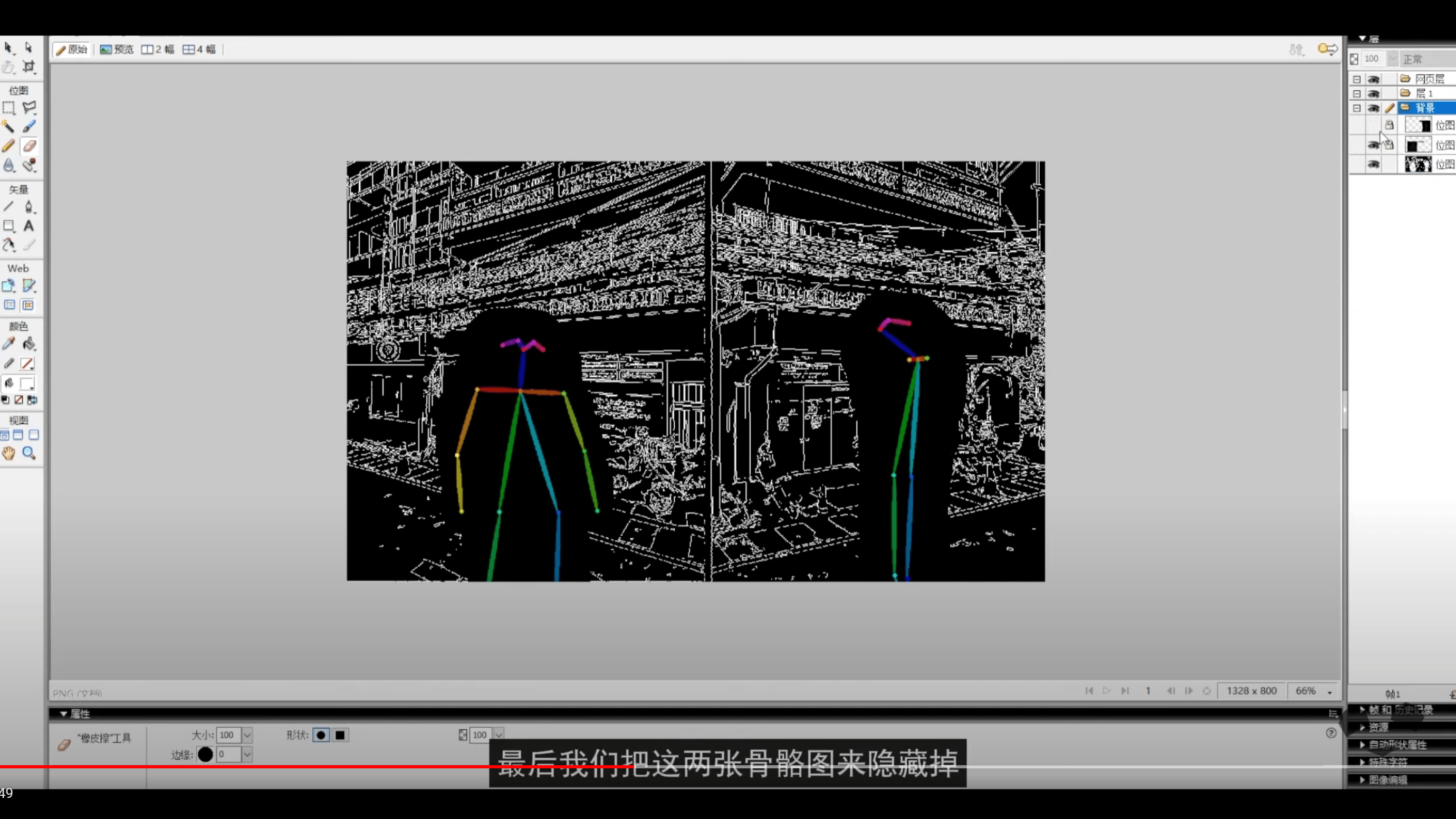
① 前期图片素材准备:获取同一场景不同角度图片(拍摄、谷歌地图等);分割模板;骨骼图
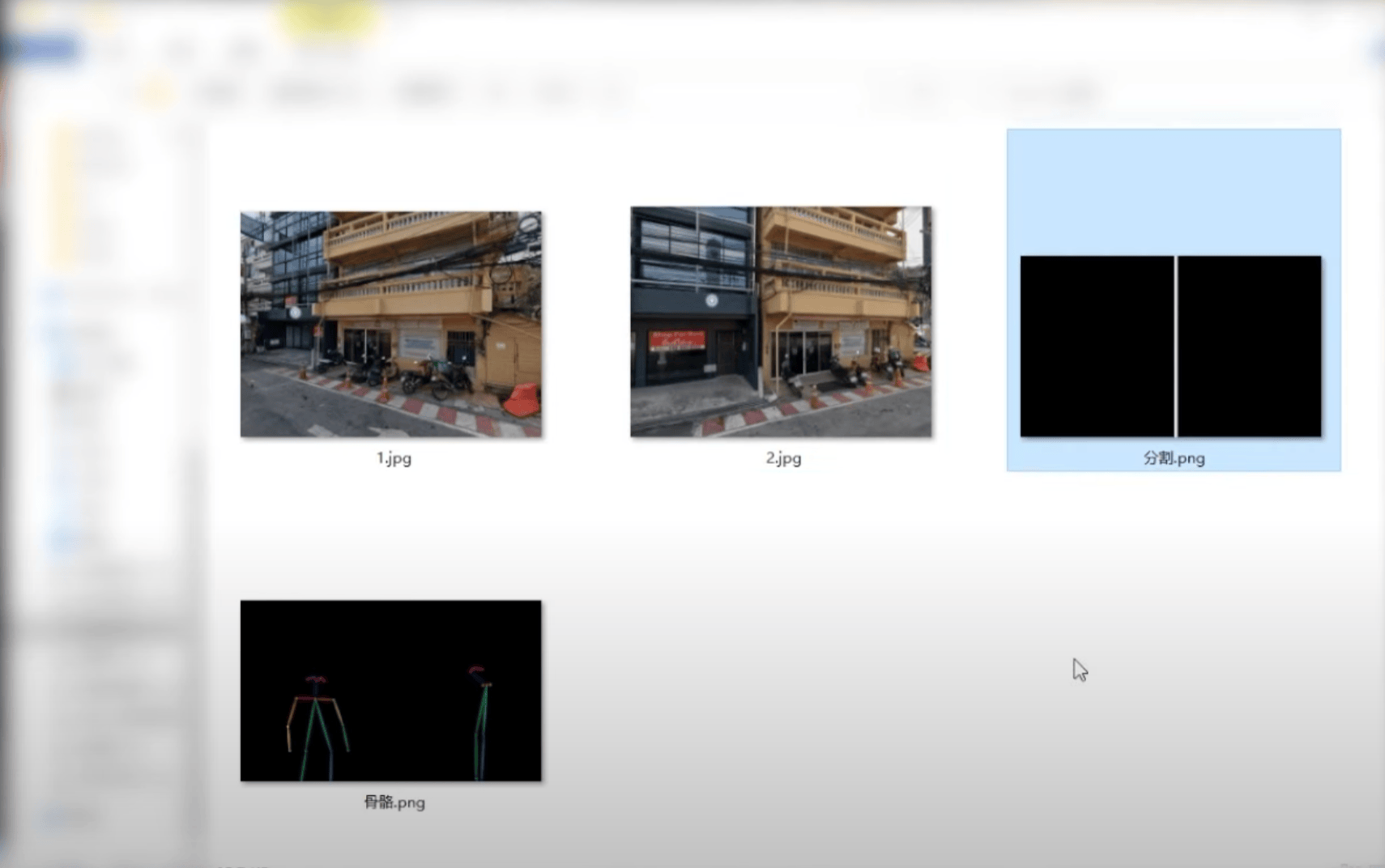
② 图片处理:两张街景放到分割板子上

这步注意 CN 分辨率
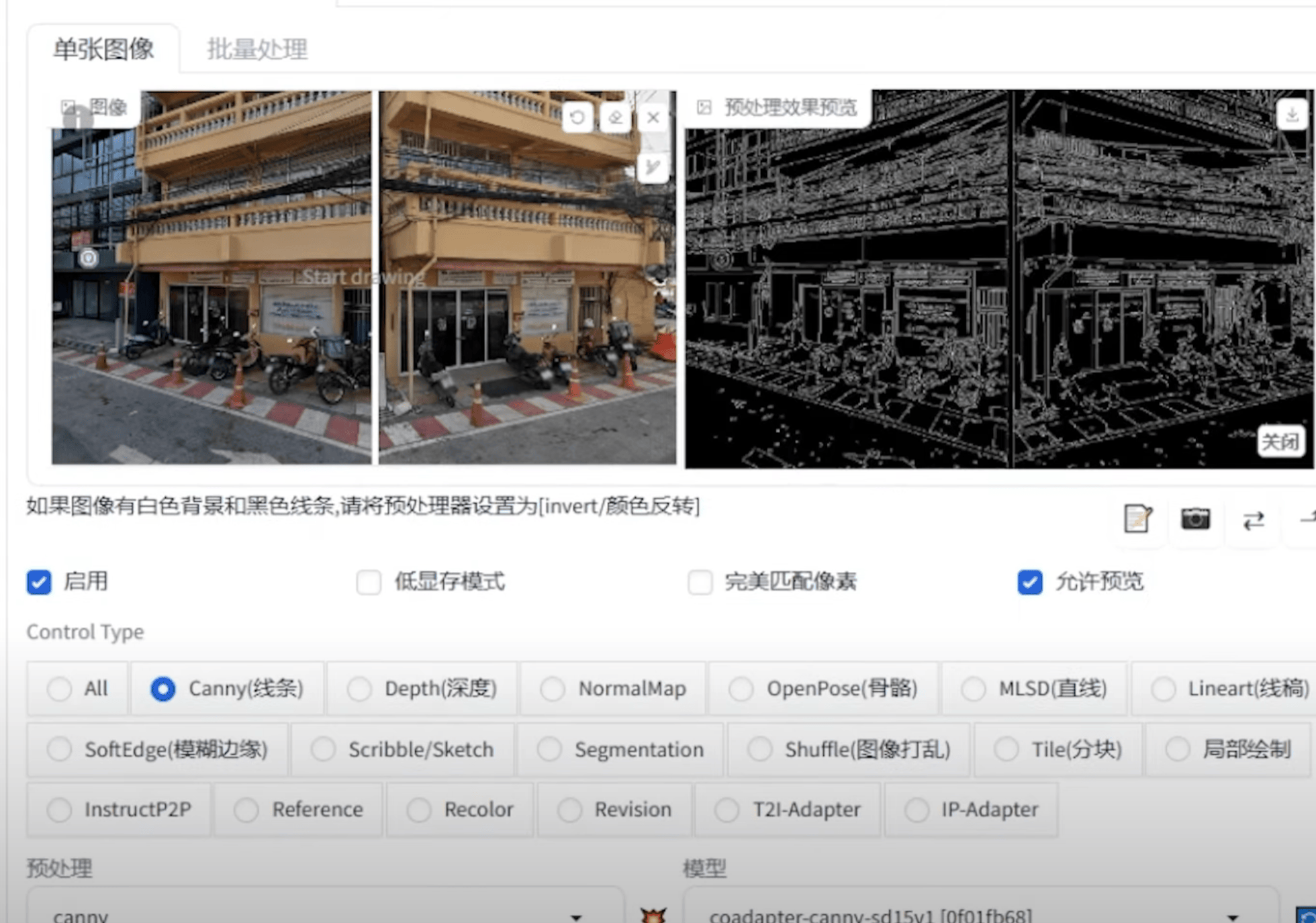

③ 出图
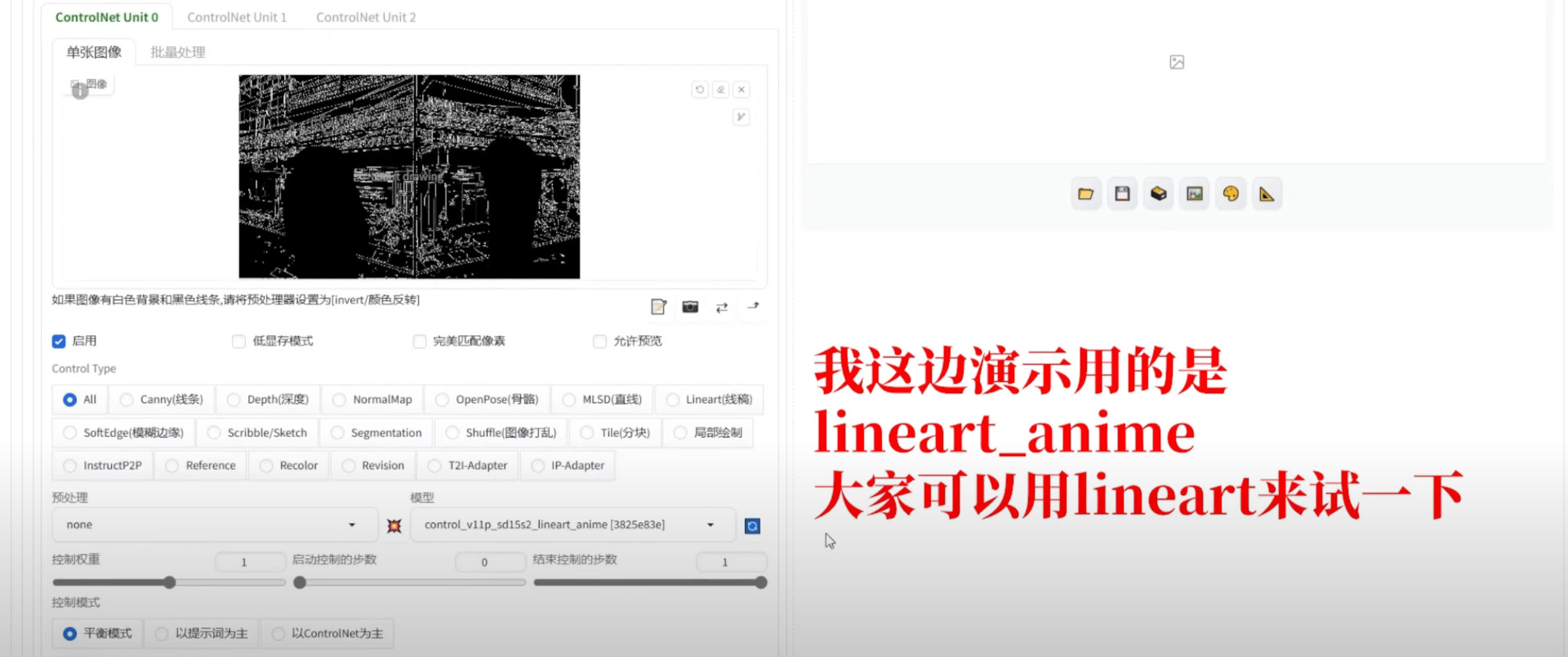
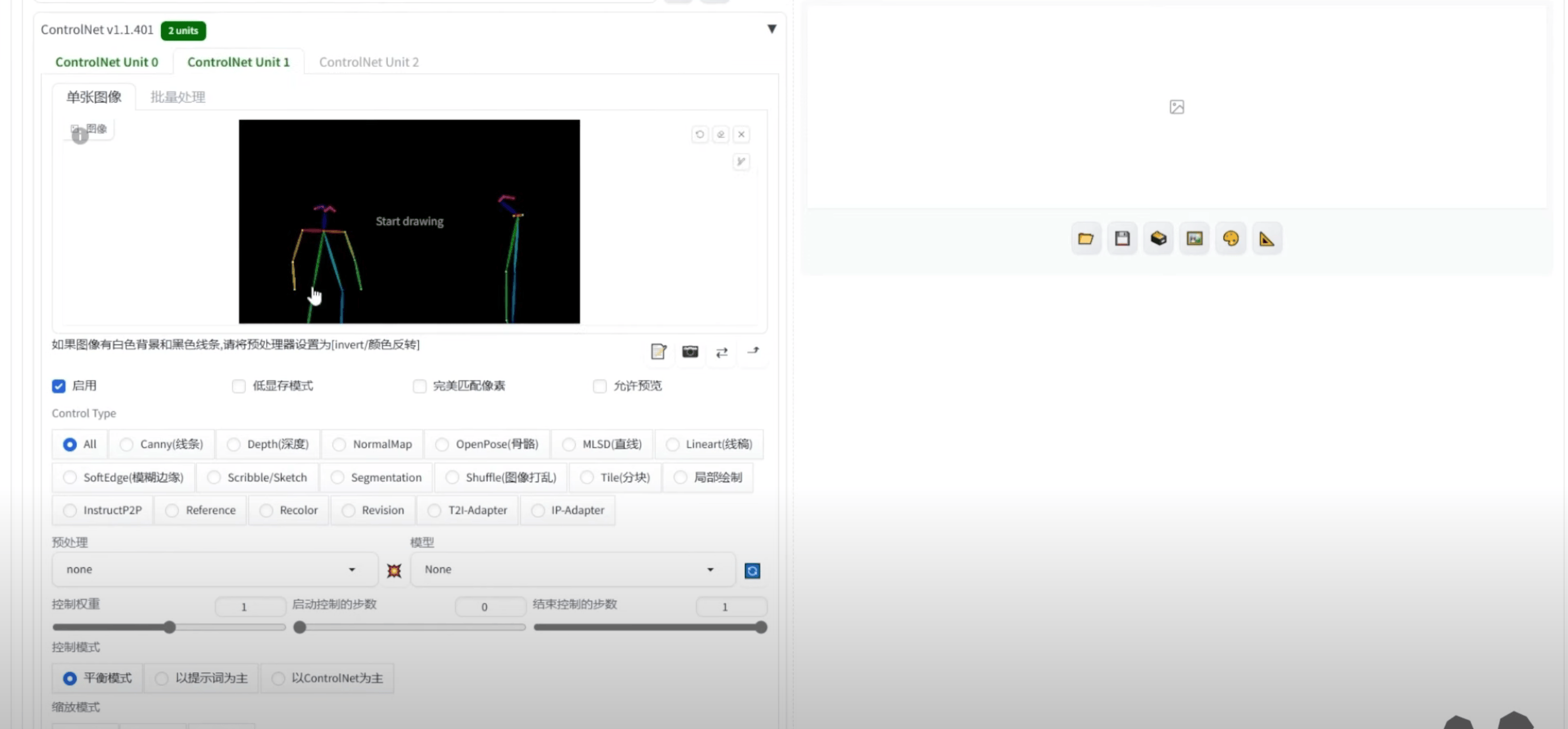
④ 得到初步图片

⑤ 图片
图生图,Prompt 增加景深描述,重绘幅度0.6,CN-Canny + CN-Tile 0.3
得到结果

10.10 人脸修复的三种方式
① 后期修改 - 分辨率提高 - 面部修复
CodeFormer② 图生图,局部重绘,CN-Canny + CN-Openpose + CN-Tile
③ FaceSwapLab 换脸
