一、基础知识
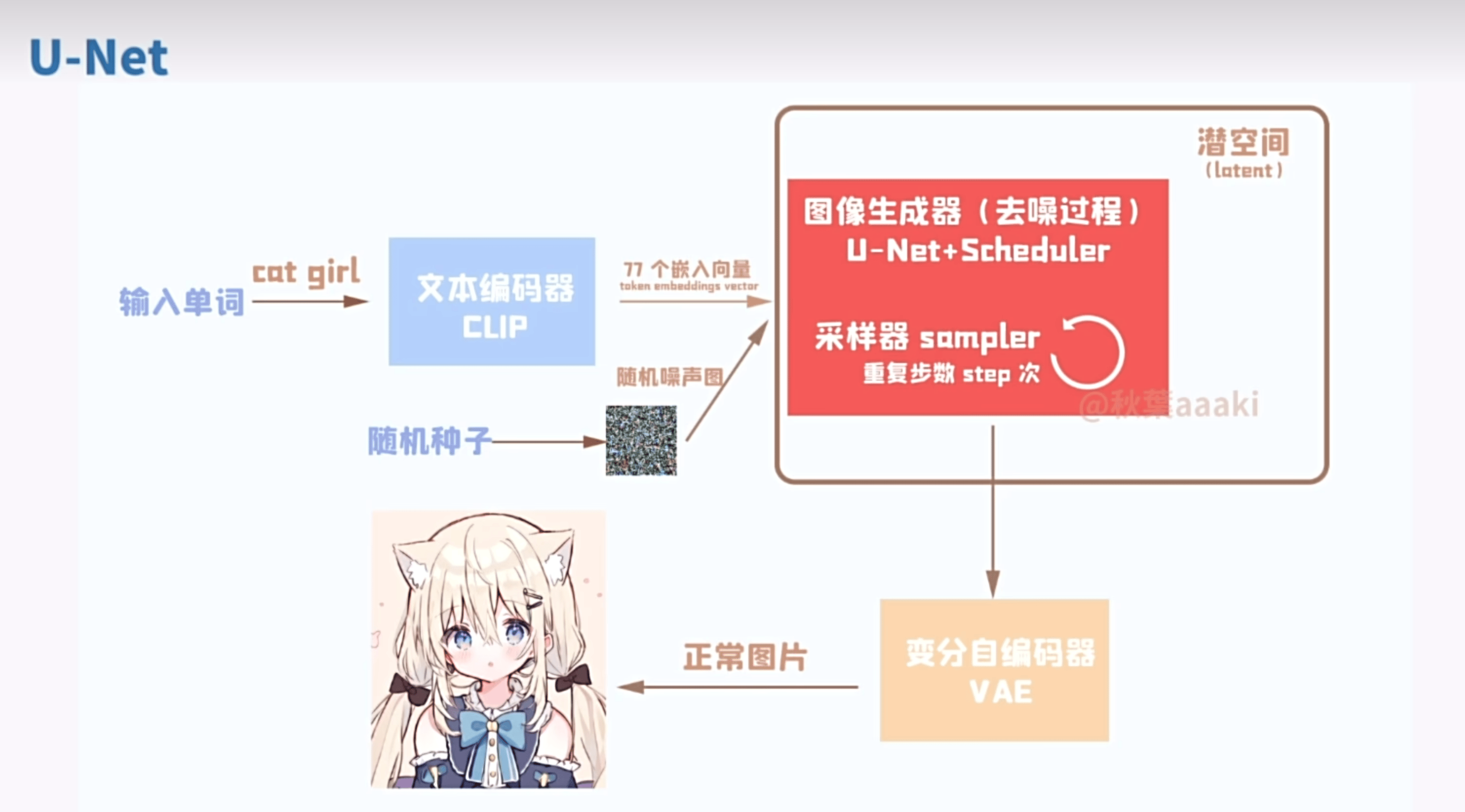
1.1 Stable Diffusion 原理
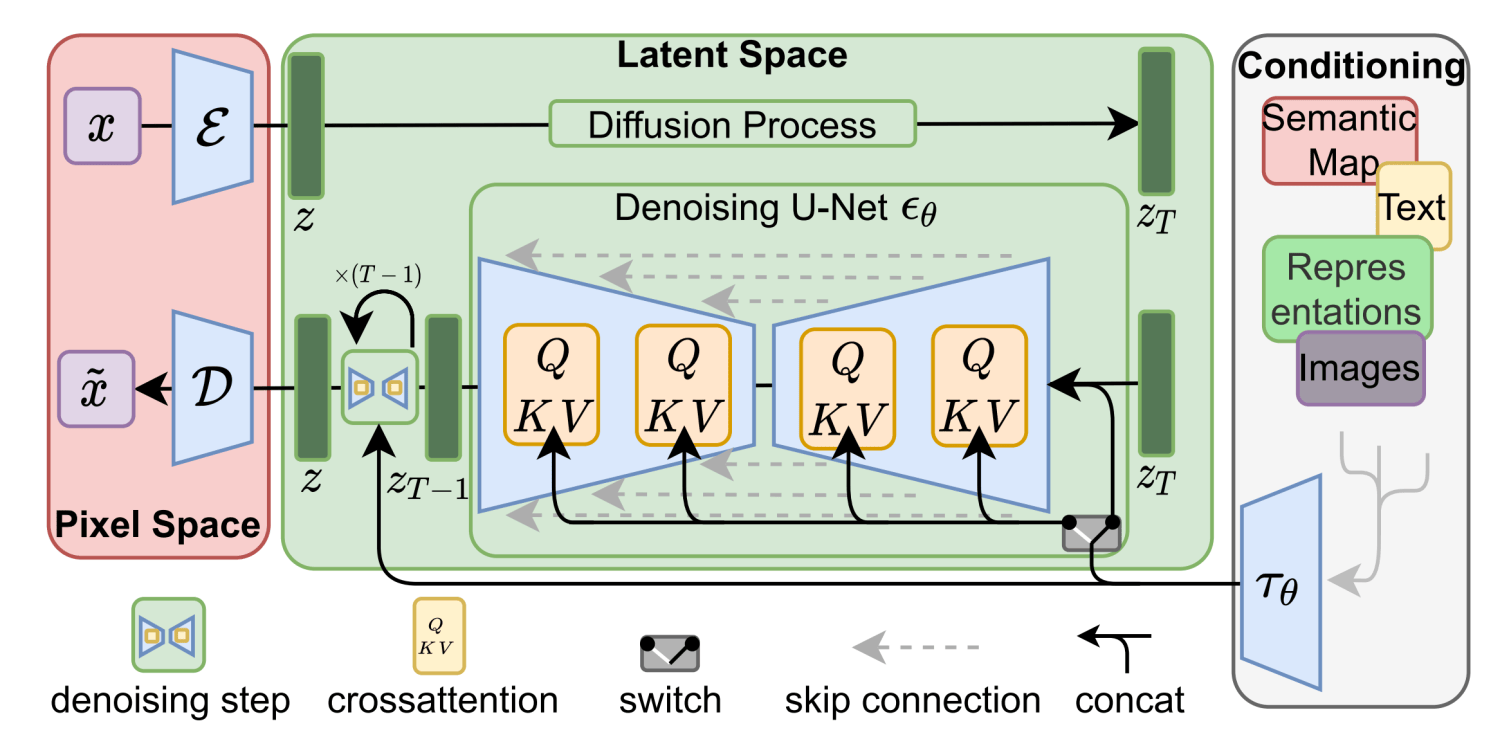
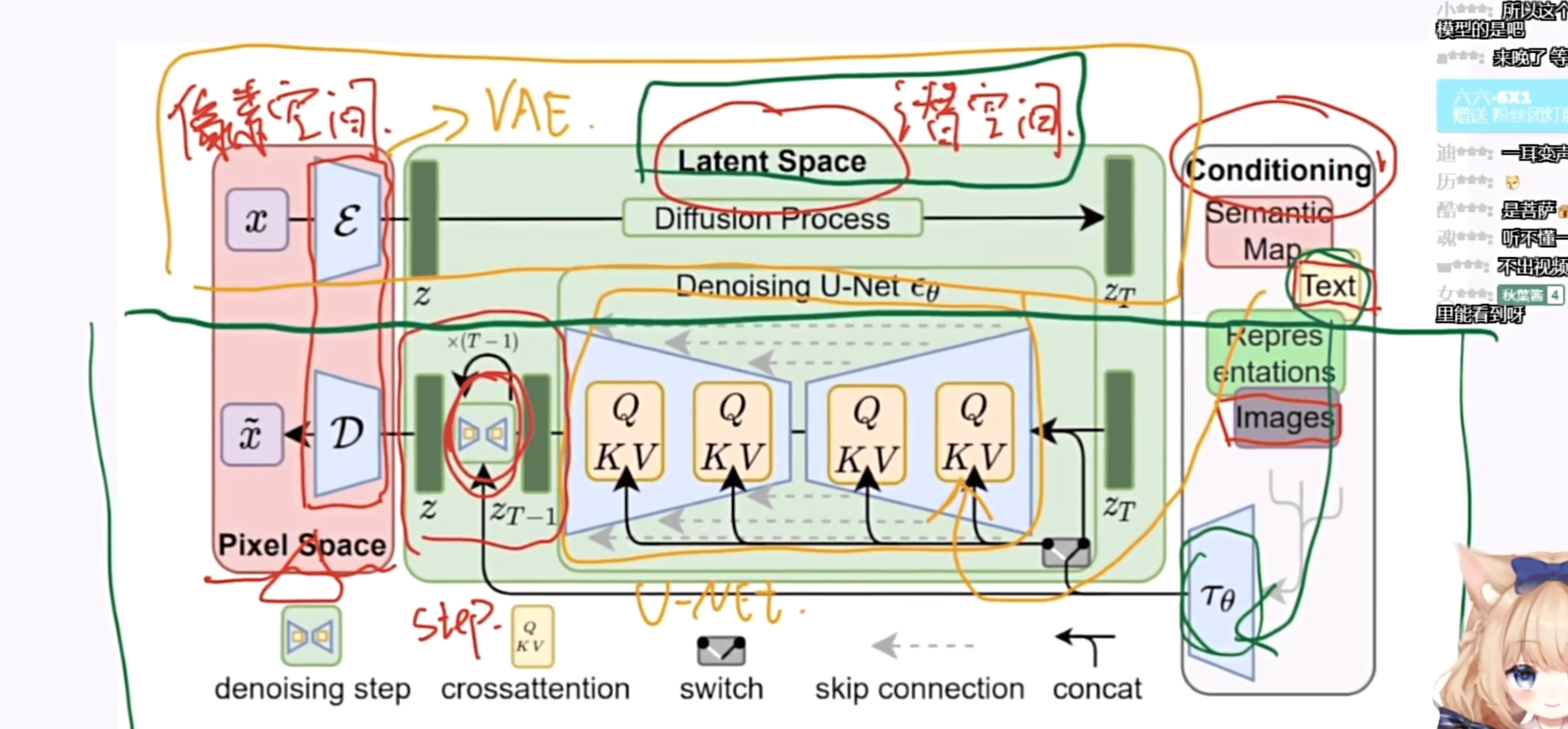
Pixel Space:实际 / 像素空间
Latent Space:潜空间,压缩过的空间,如果直接用原图像素量太大。
Conditioning:描述词
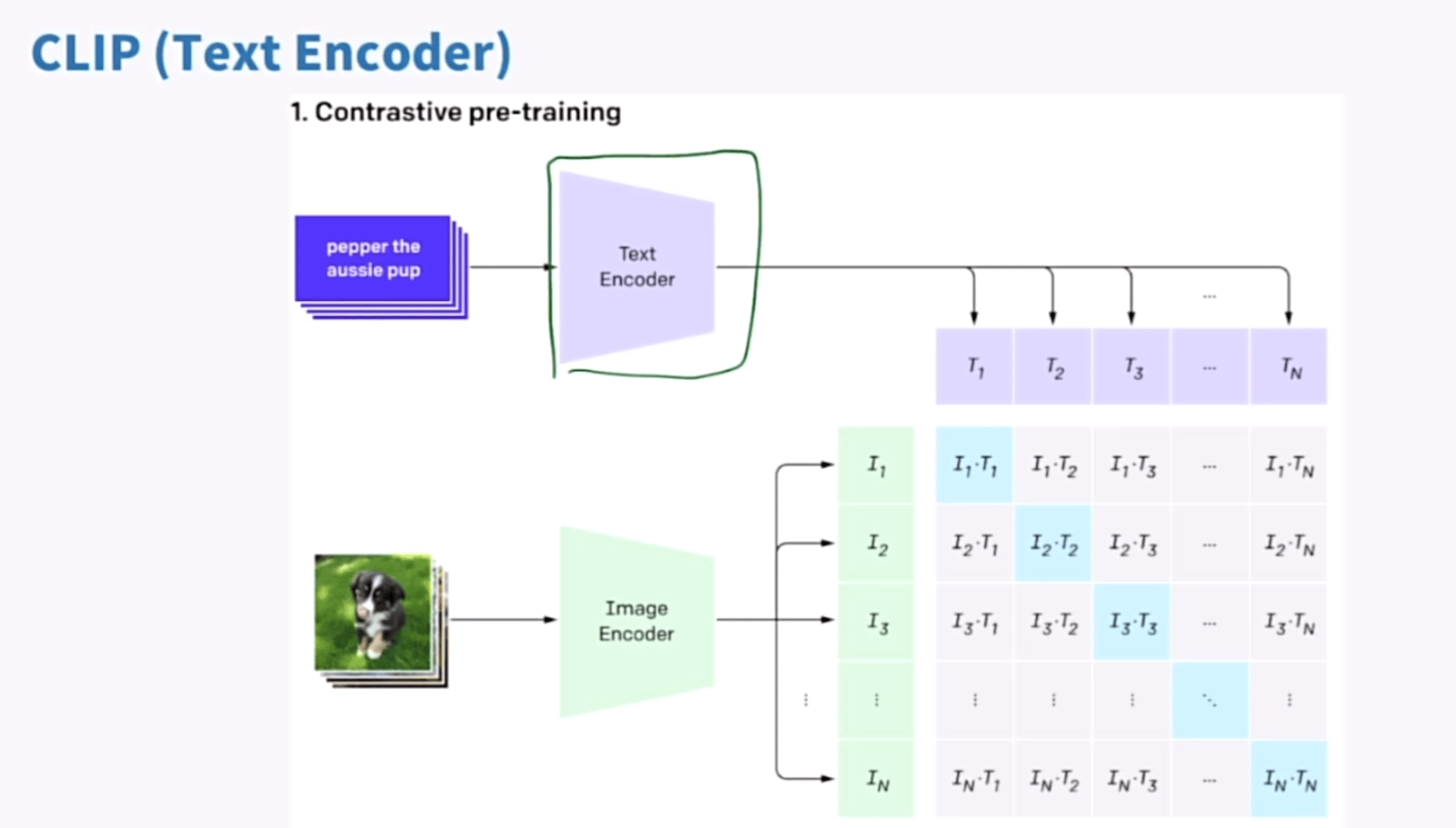
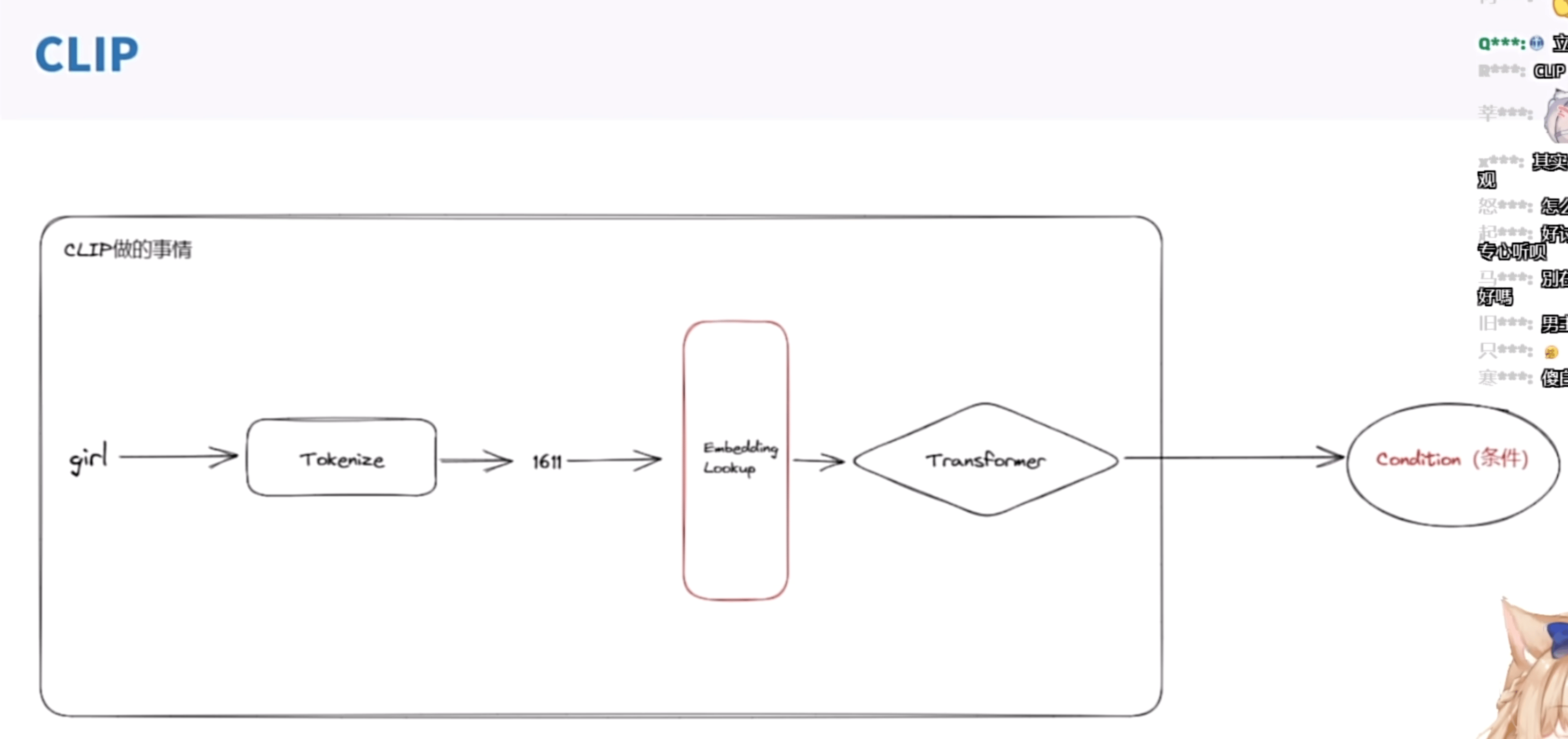
CLIP
一个基于对比的文本图像预训练方法,一个基于对比学习的多模态模型
U-Net
因为结构画出来是一个U形的东西,得名U-Net






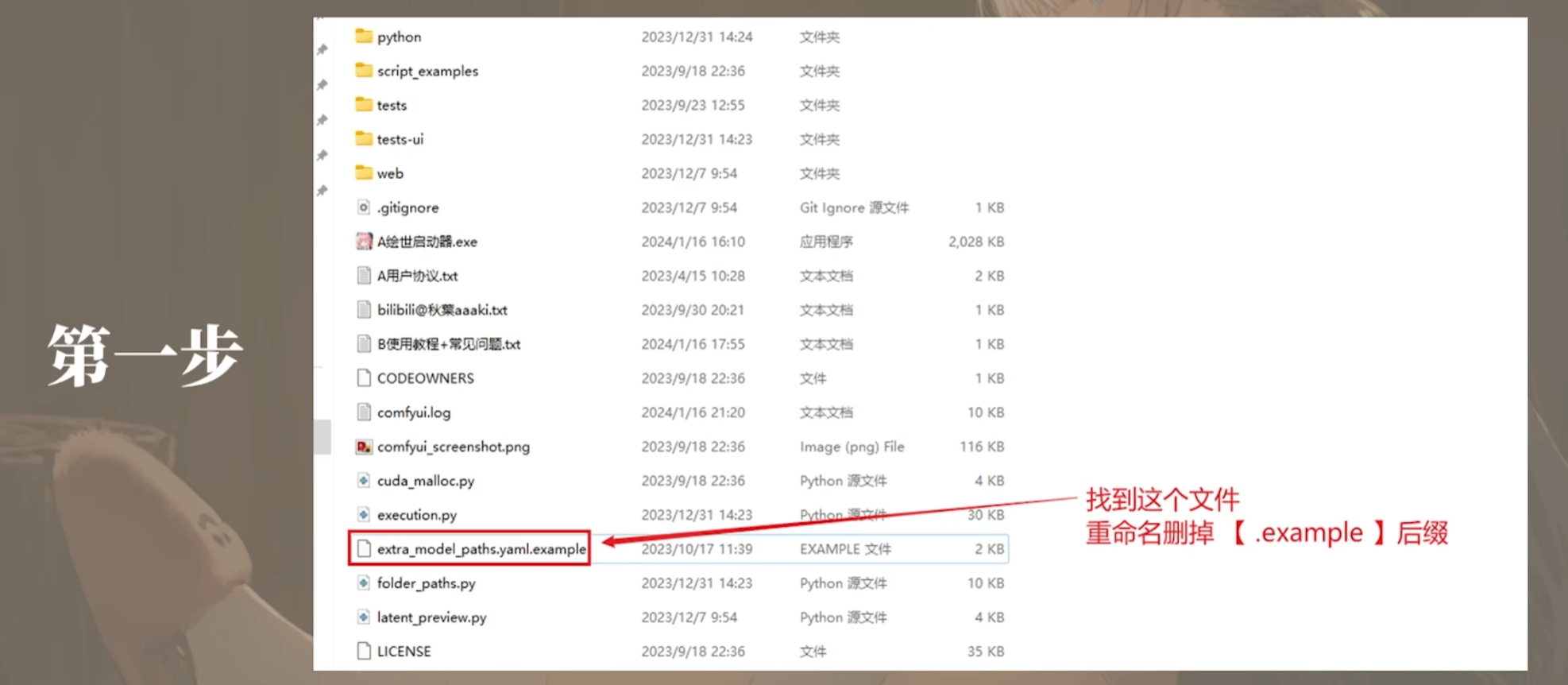
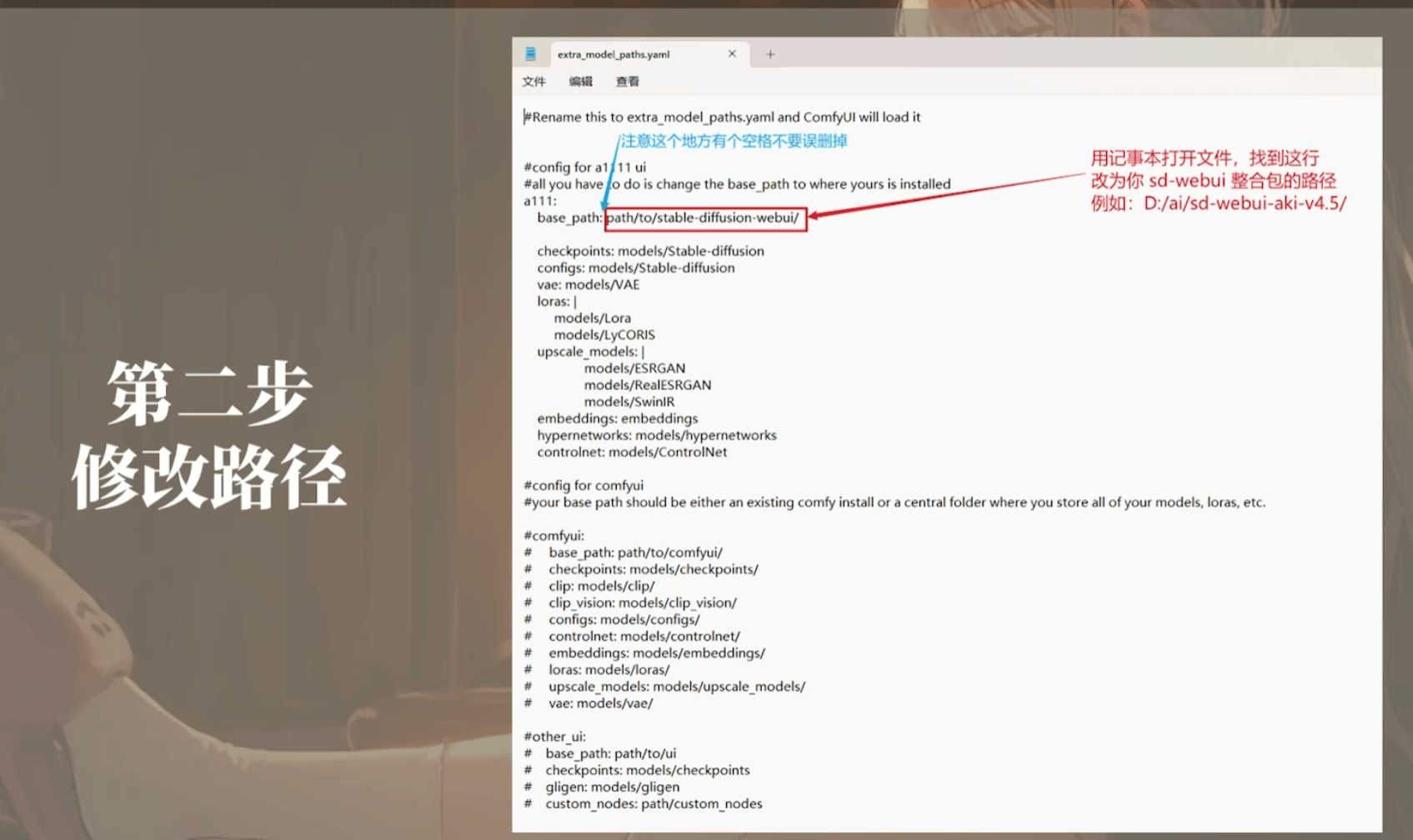
1.2 ComfyUI 文件结构
1 | # 插件地址 |
同步WebUI和ComfyUI模型
1.3 ComfyUI 快捷键
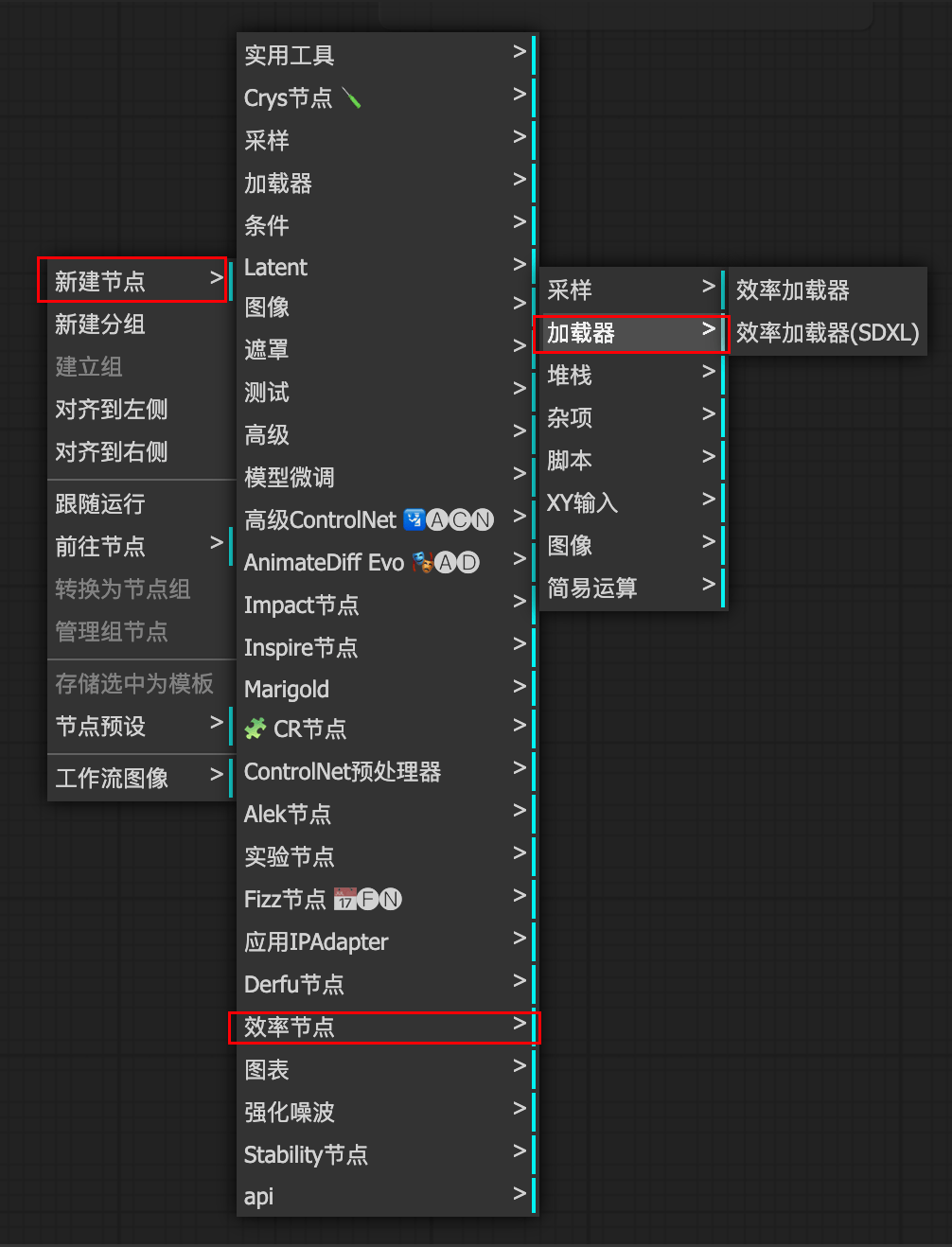
1.4 打包
解包 与 封包:解包的意思是把打包好的管道打开修改里面某一项,然后再次把修改的封起来

题词权重方式:
A1111:SDXL的权重方式
解包

封包
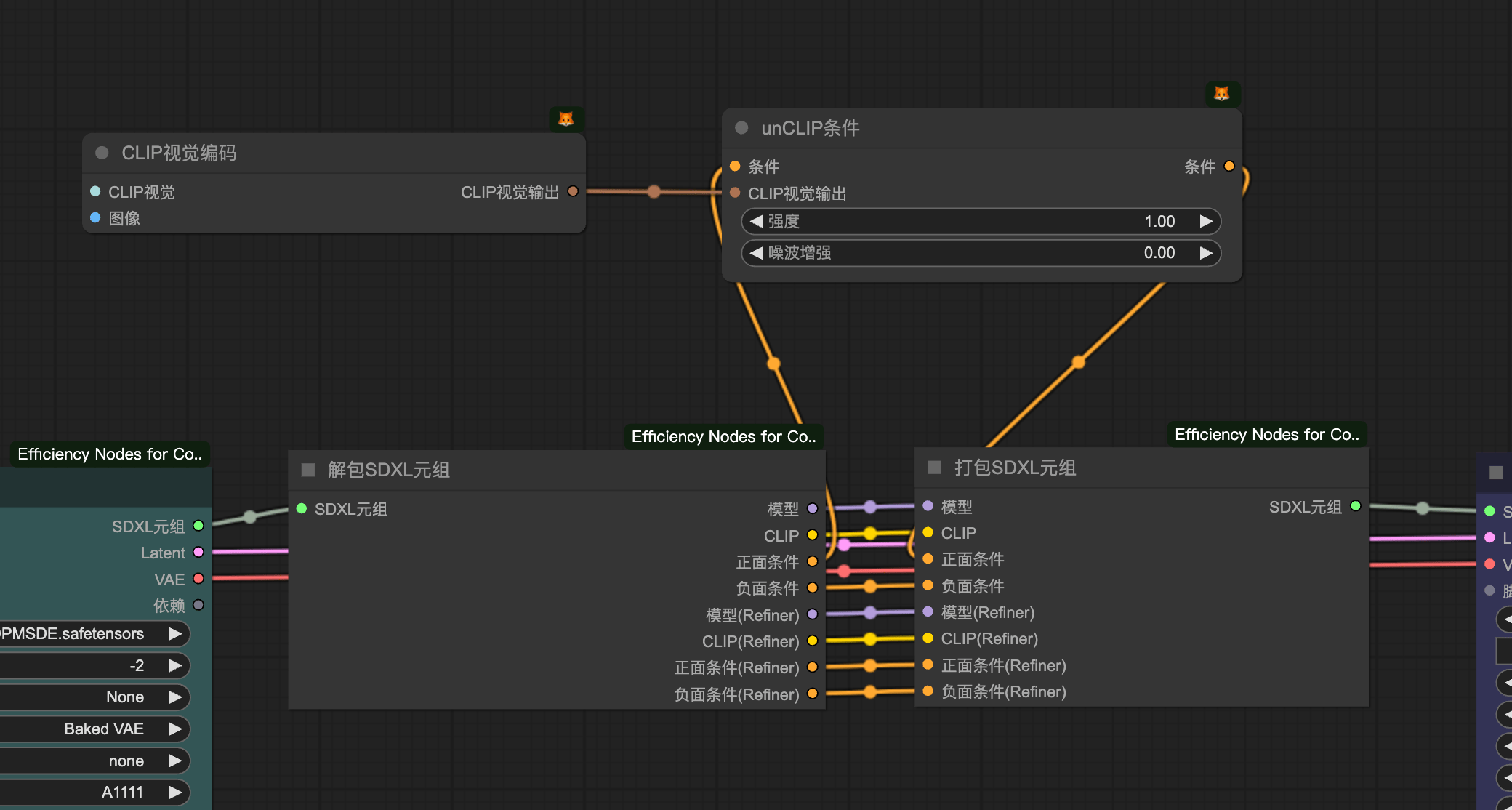
自制集成节点


二、模型
2.1 ConrtolNet
manager-搜索
controlnet安装地址:
F:\ComfyUI-aki-v1.3\models\controlnet
Aux集成预处理器可以选择任何一种预处理器,使用起来比较灵活,推荐

2.2 CLIP视觉编码
将图片转化成CLIP条件的工具
需要三大件:
CLIP视觉加载器——>CLIP视觉编码——>unCLIP条件注意:尽量使用SDXL模型,支持效果更好
.png)
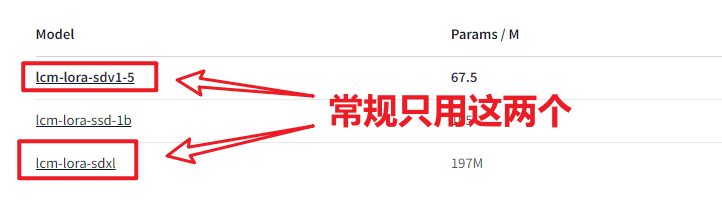
2.3 LCM-lora快速出图
使用注意:
模型对
K采样器有要求:
步数:4-8
CFG:1-2
采样器:LCM(不是必须,但是LCM会更快)
采用
模型离散采样算法会细节更丰富,当然不用也可以注意
v1.5和SDXL选择

.png)

同Seed下,用了
LCM离散采样的细节会稍微好一点
2.4 SDXL-turbo 快速出图
官方只能识别
512x512分辨率的参数推荐:
步数:1
CFG::1-2
评价:速度快,但是效果并不好


分辨率提高到1024
参数推荐:
CFG: 1-2
Step: 4-8
采样器:DPM++ SDE Karrars
意义:如果性能足够,参数可以稍低,实现实时生图
.png)
三、必备插件
3.1 Comfy-UI-Manager

3.2 WD1.4 反推
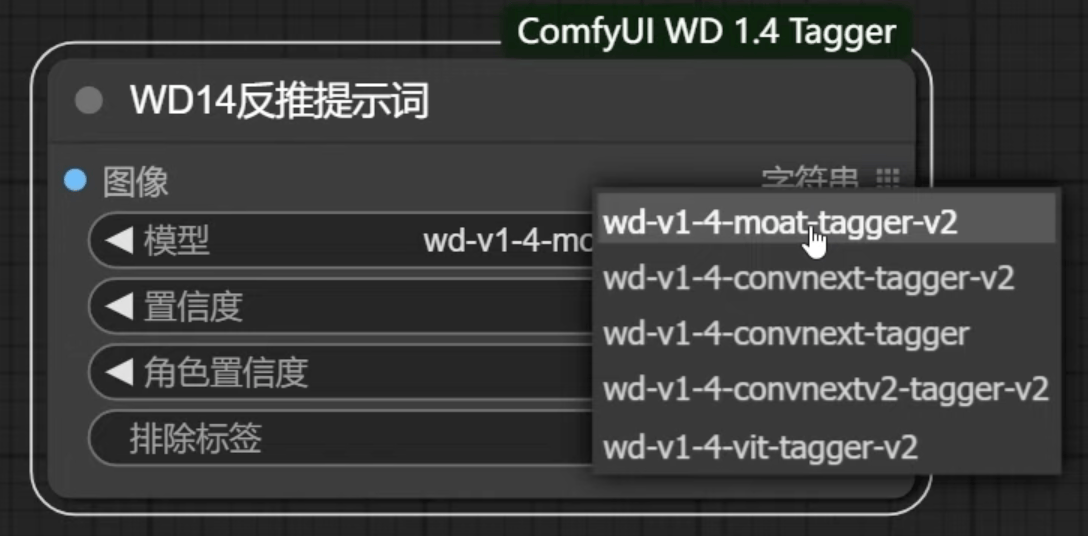
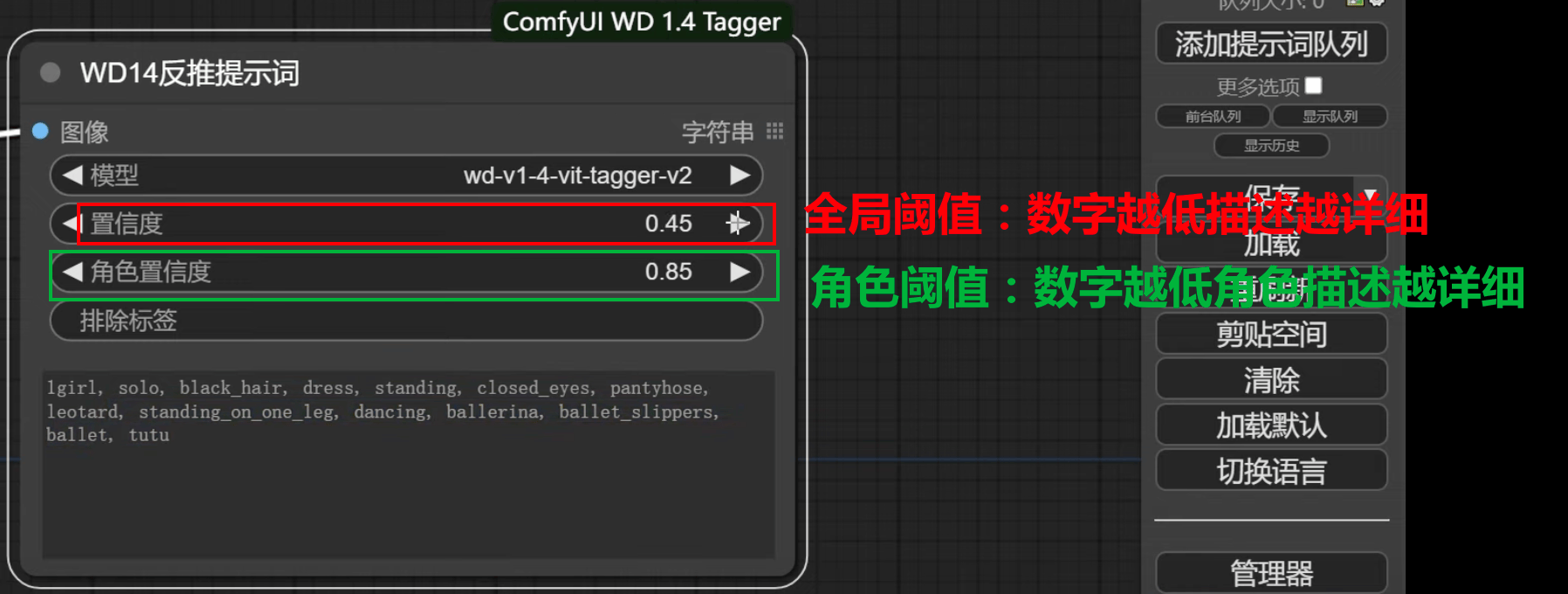
3.3 SDXL风格化
提示词界面

提示词界面,高级版本
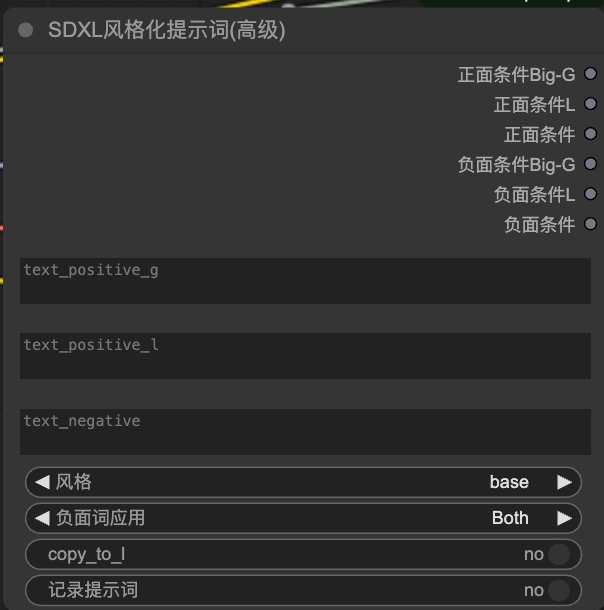
text_positive_g: (形容词),eg:xx样式的牛仔裤
text_positive_l: (名词),eg:1个牛仔裤
text_negtive:抹除画面物体
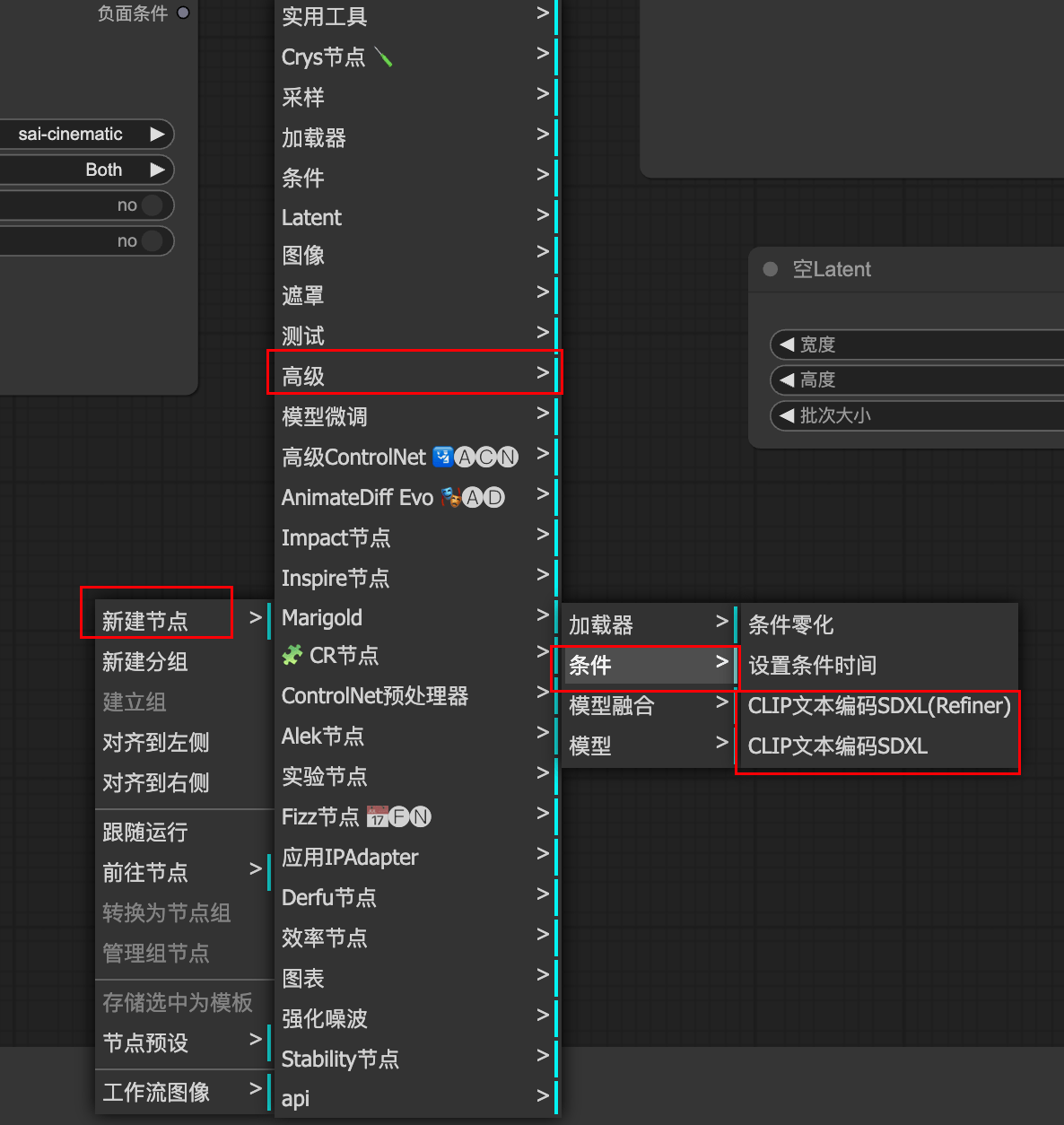
CLIP文本提示词SDXL优化版本
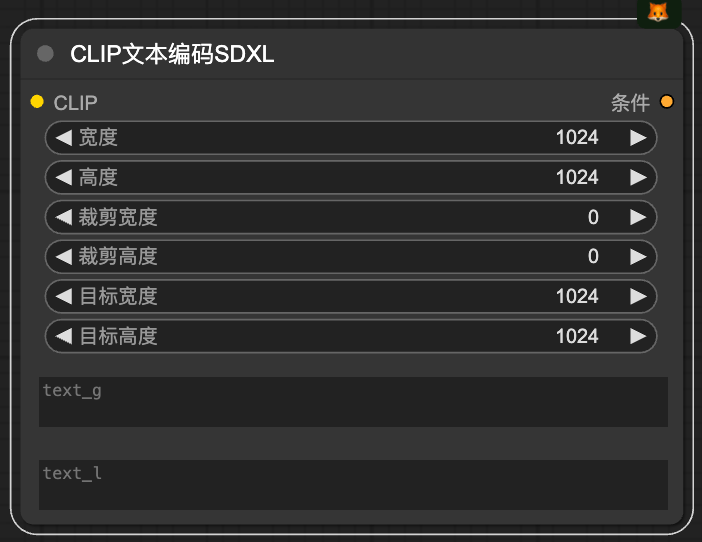
clip 空间大小应该是 实际图片大小的 2~4倍

3.4 AnimateDiff
AnimateDiff 需要:专门加载器的大模型 + 匹配的LoRA才能生效
AnimateDiff v3 模型动物园
| Name | HuggingFace | Type | Storage Space 存储空间 | Description |
|---|---|---|---|---|
v3_adapter_sd_v15.ckpt | Link | Domain Adapter 域适配器 | 97.4 MB | |
v3_sd15_mm.ckpt.ckpt | Link | Motion Module 运动模块 | 1.56 GB | |
v3_sd15_sparsectrl_scribble.ckpt | Link | SparseCtrl Encoder SparseCtrl 编码器 | 1.86 GB | scribble condition 涂鸦条件 |
v3_sd15_sparsectrl_rgb.ckpt | Link | SparseCtrl Encoder SparseCtrl 编码器 | 1.85 GB | RGB image condition RGB图像条件 |


AnimateDiff Evolved :配套更全,只安装这个即可
核心处理器

动态缩放:影响运动强度

动态LoRA


控制运镜方向的,只能v2
联系上下文
理论上一个视频只有2s,但是有了联系上下文功能,就可以实现理论上无限时常的视频生成

参数一般情况保持默认即可
参数解释:
上下文长度:一批次出几个图像,默认16(即8帧),设置为8的倍数即可,显存高可以开的大
上下文步长:一帧一帧推理还是跳着推理,1最细腻
上下文叠加:上下文连接的帧数,理论运动越激烈叠加的越少,极限可以开到1。
sparcectrl




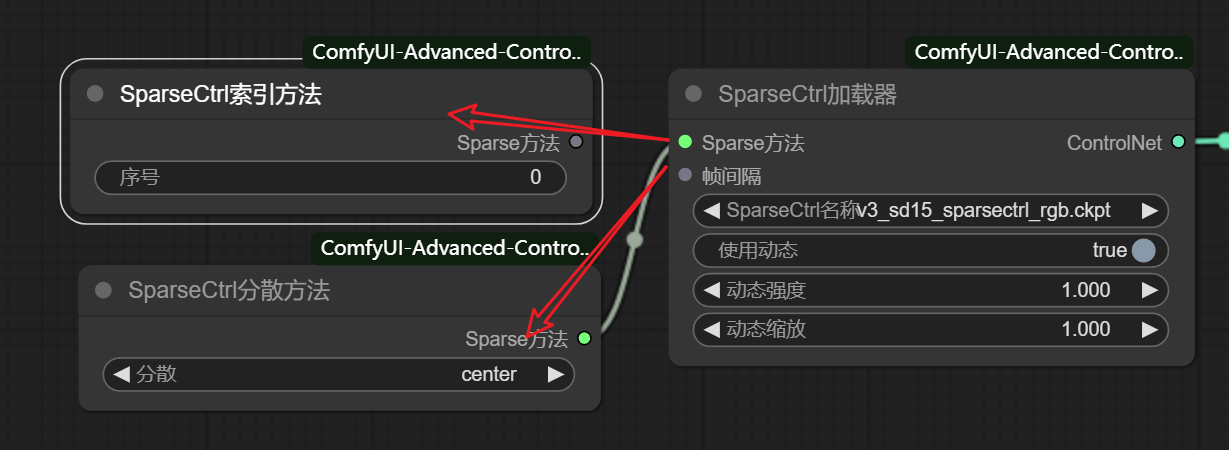
SparseCtrl 索引方法: 图片出现在视频的第几帧
SparseCtrl分散方法:
- 不变:即不变
- 起始:图片为视频的开头状态(视频补齐之后运动)
- 结束:图片为视频的结尾状态(视频补齐之前运动)
- 中心:图片为视频的中间状态(补齐两端运动)
3.5 VideoHelperSuite
处理视频帧组成视频的插件

Ping-Pong:视频从头到尾,再从尾到头,如此重复
3.6 FIZZ
普通使用:通过类似关键帧的方式控制图像生成
高阶使用:通过数学函数更加精准控制生成图像
普通使用
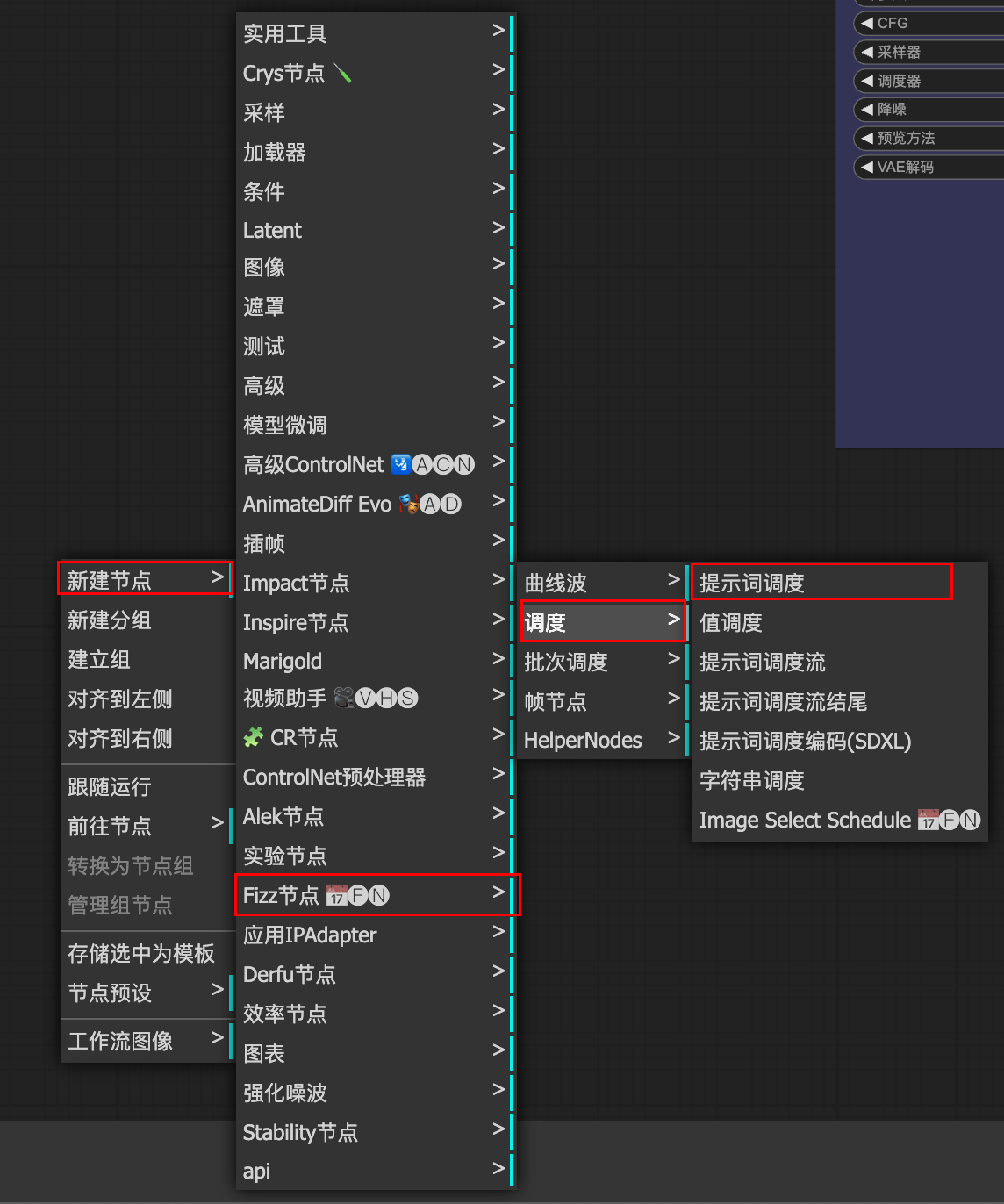

注意:
关键帧提示词的末尾不应该有”,”
3.7 Advanced-ControlNet
高级ControlNet
animediff_controlnet_checkpoint.ckpt模型下载地址

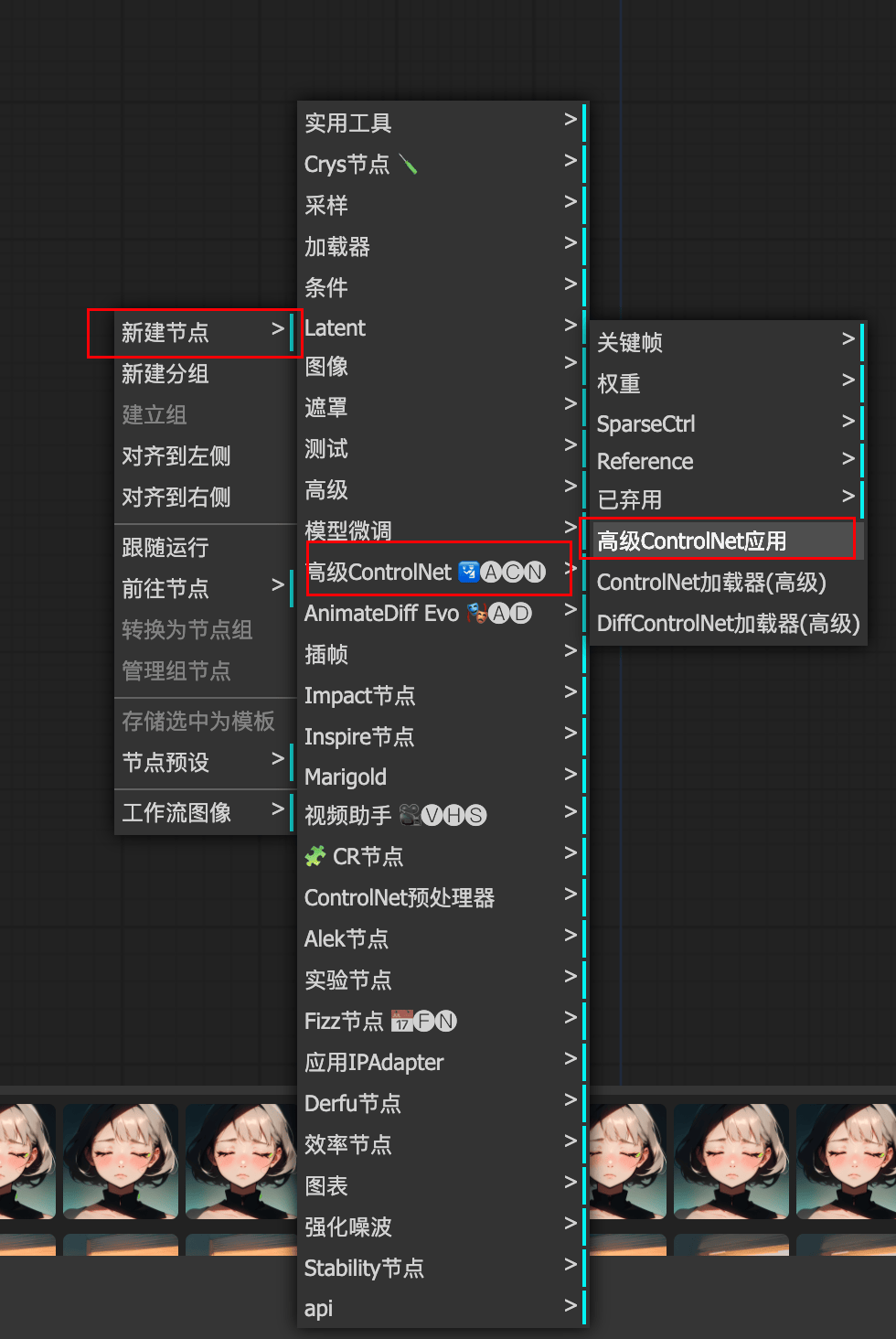
3.8 Frame-Interpolation补帧
补帧工具
manager 直接搜索下载
补帧方式
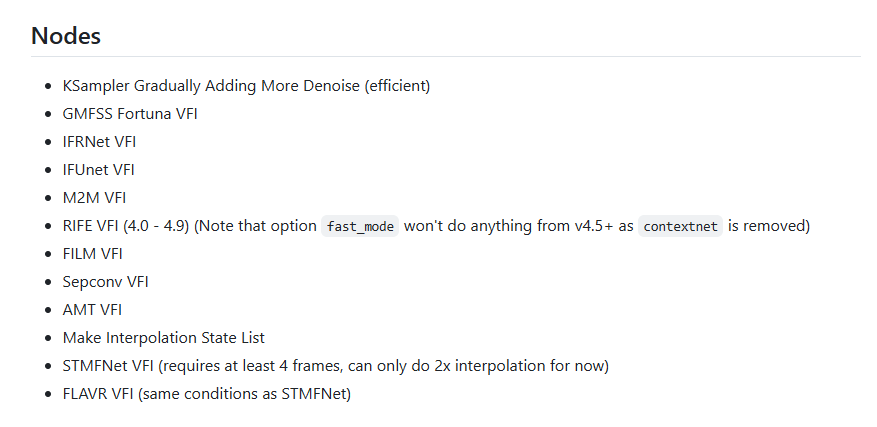
由于补帧方式太多,随大流用 RIFE VFI 即可
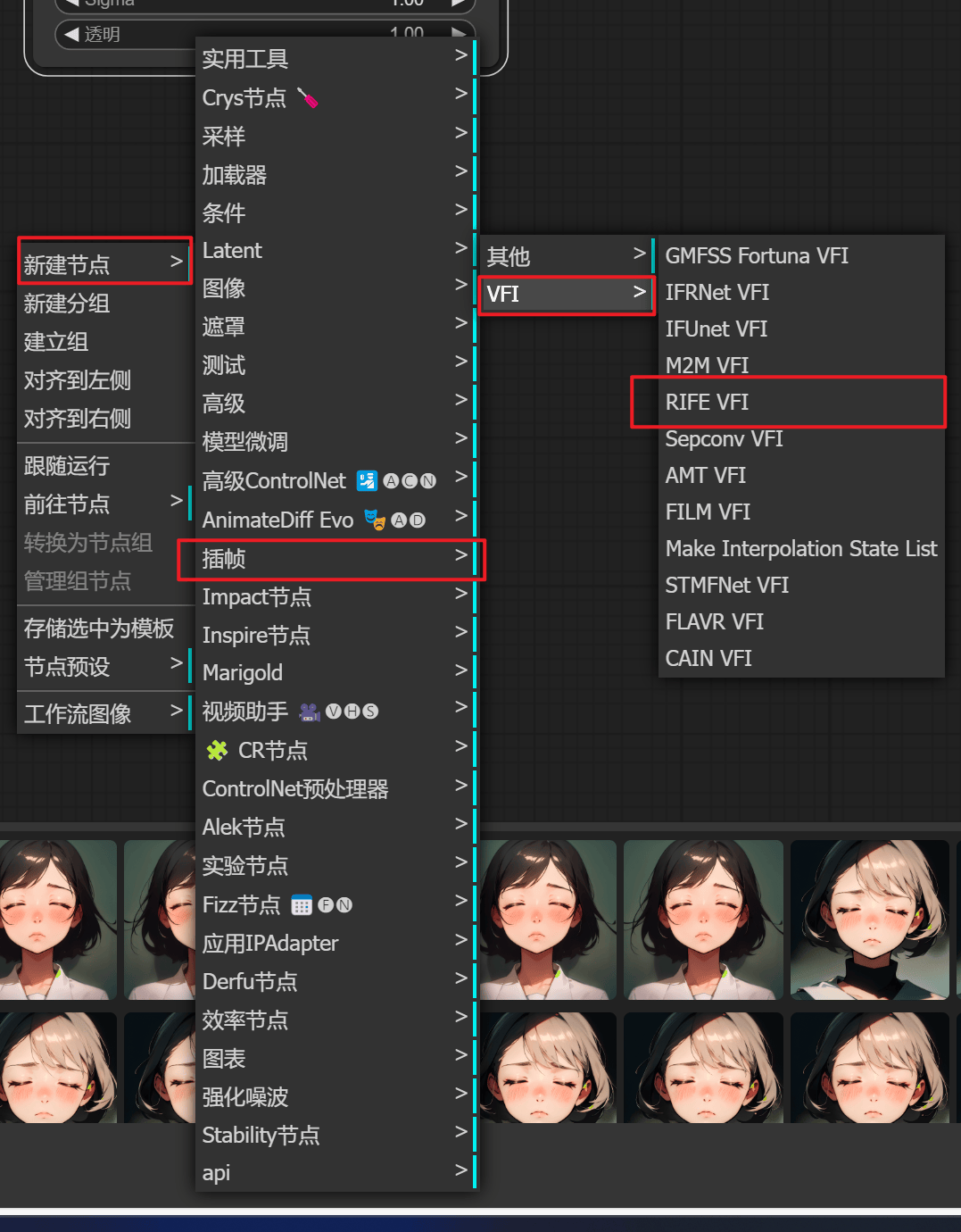
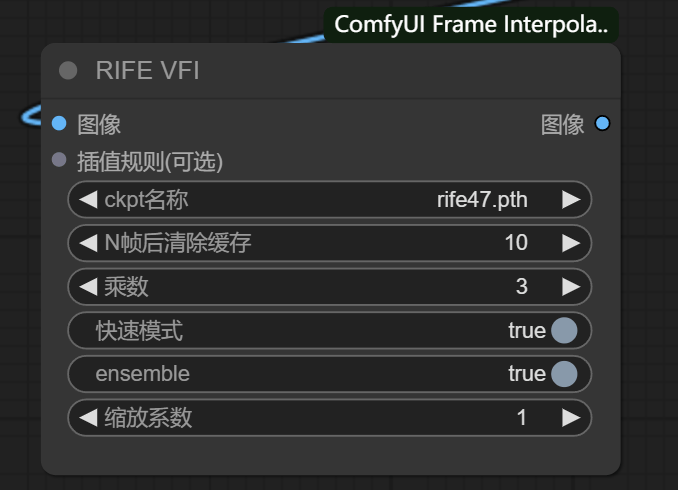
ckpt名称:用默认 rife47.pth 即可
乘数:想让帧数翻几倍
其他选择默认即可
3.9 XY图表
前提:必须用效率节点
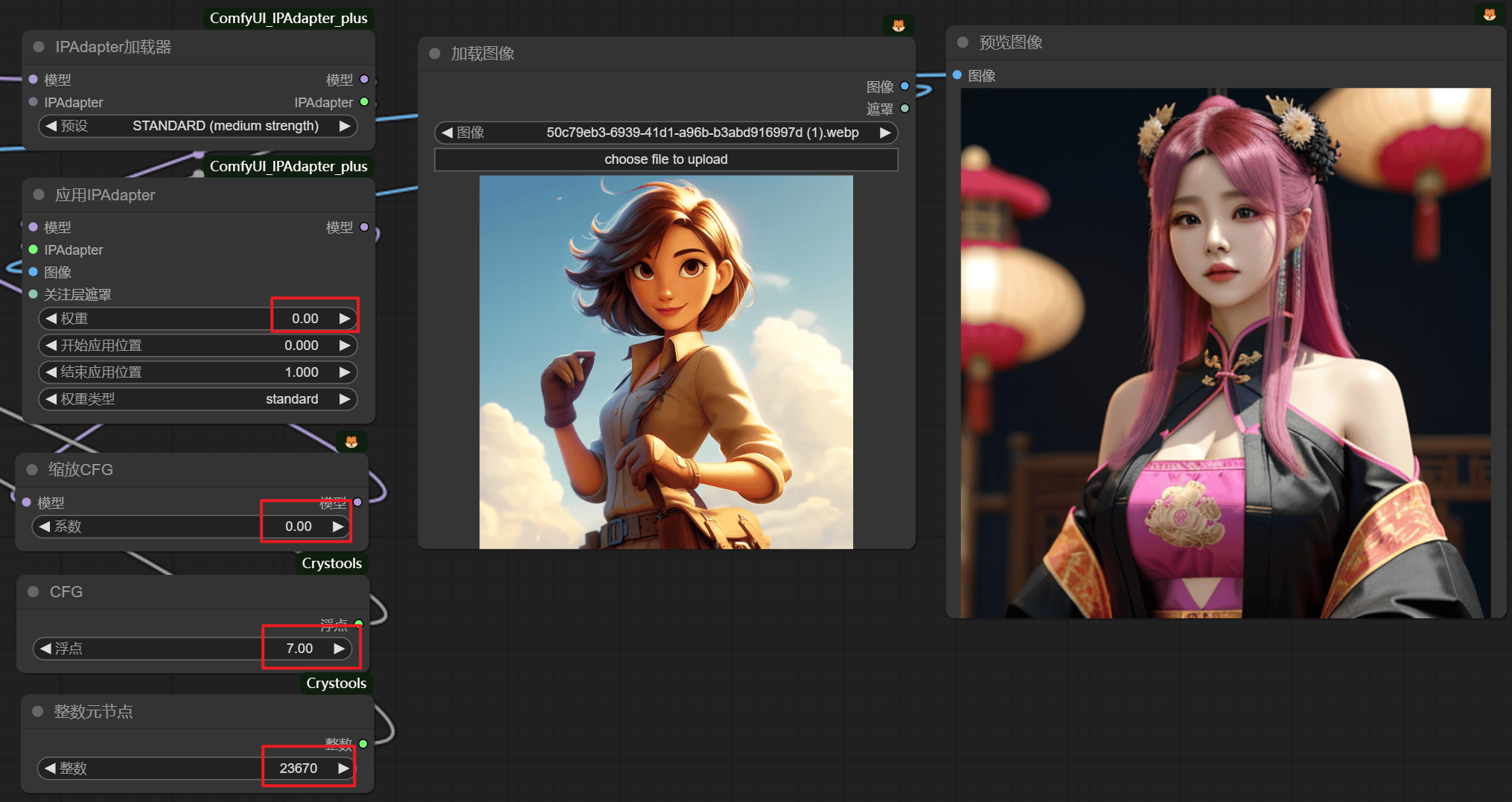
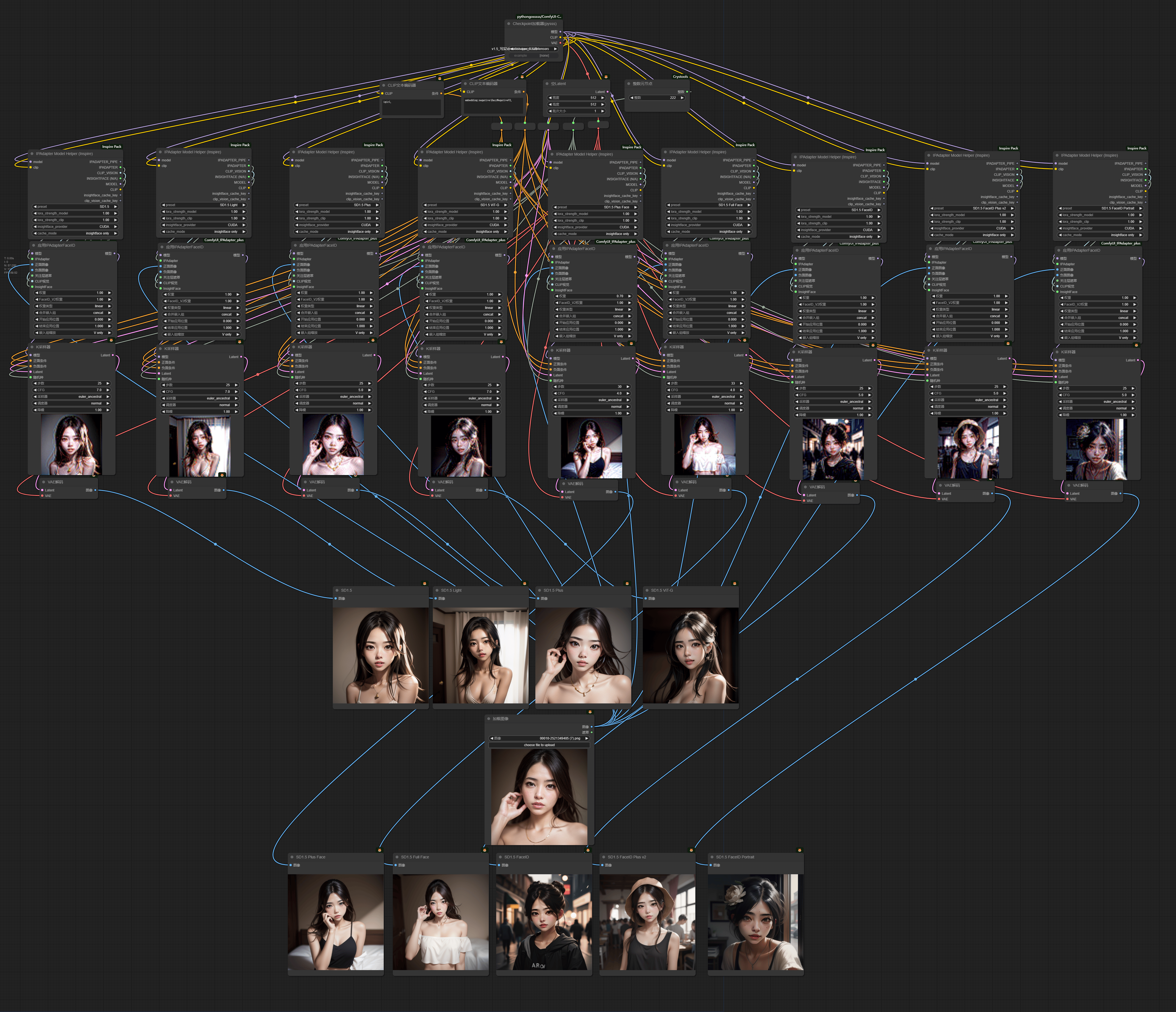
3.10 IPAdapter
InsightFace
注意:使用
InsightFace需要单独安装InsightFace,默认秋叶启动器是自带的,能用就别重装啥的瞎搞,不能的话或者用的原版comfyui看教程https://www.youtube.com/watch?v=72xow6bNWSc&list=PLK7sA3zrSa4s0tO8w2pdc7zPTcIAgS7ru&index=16
原理
unCLIP 过程的升级版,把图像、文本分别分析成 TOKEN ,组成embedding 传入 U-Net

模型列表

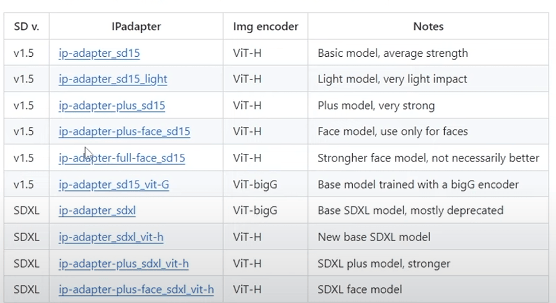
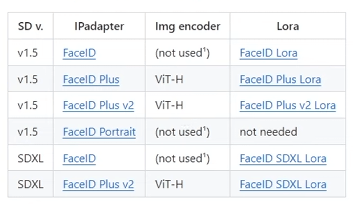
模型特点分析:
ipa_v1.5:Token 8个,对于风格有一定的迁移,像与不像的阈值在0.4-0.5之间
ipa_Plus_v1.5:Token 16个,能更加还原原图风格,保持姿态一致性
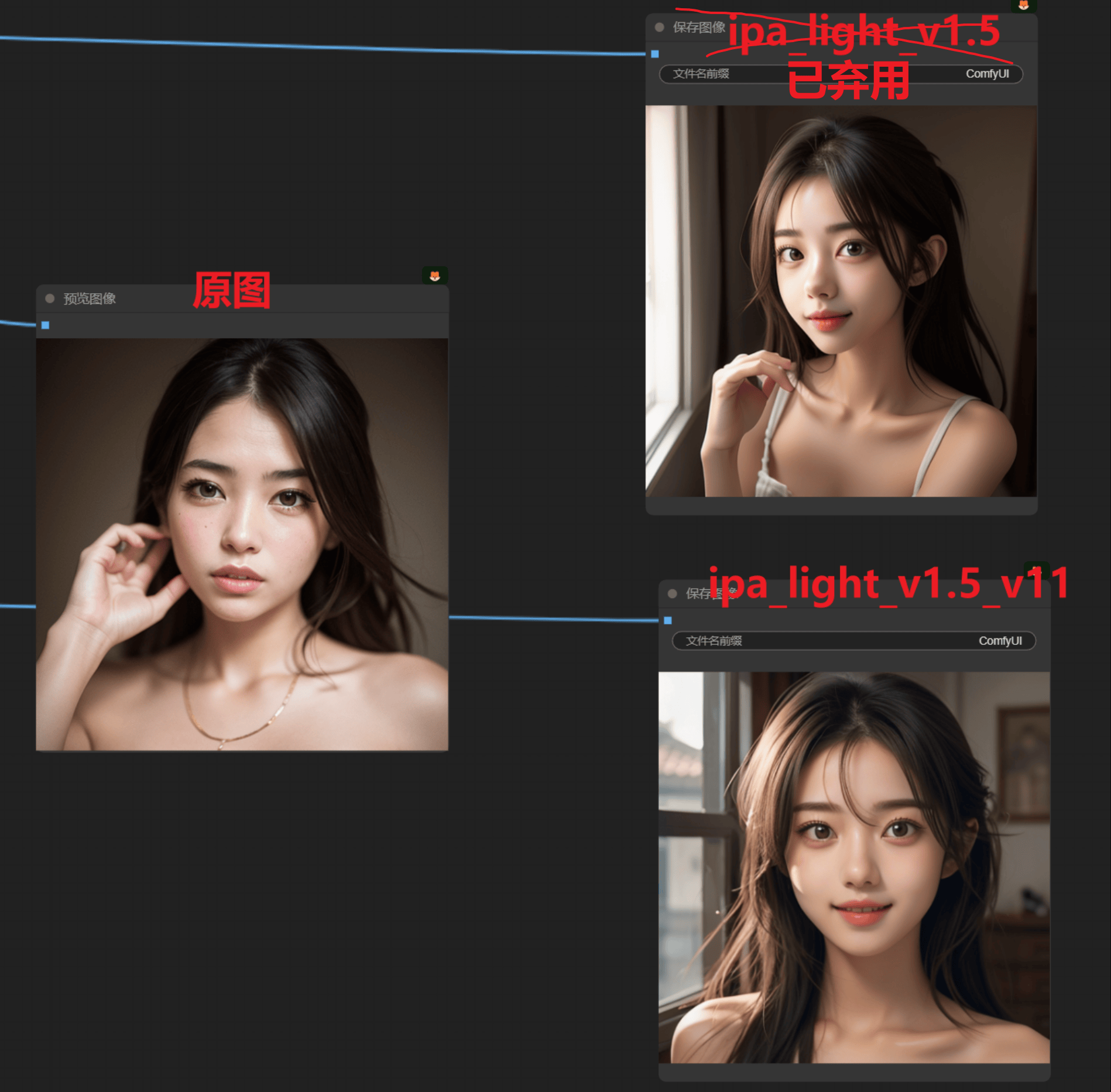
ipa_light:更轻量级的模型,如果想要更偏向参考词而不是图片,用这个合适
ipa_vit_G: 为一个用 大参数clip_vision的模型,出图更加细腻,但是也不会保持姿势

ipa_full_face_v1.5:8个Token,参考整张图片,面部如果在原图占比小那么效果会不好
ipa_plus_face_v1.5:16个Token,单独把人物面部从原图中裁切出来进行参考
ipa_faceid_v1.5:基础 faceid
ipa_faceid_plusv2_v1.5:效果更好的 faceid
ipa_faceid_portrait_v1.5: 可通过多张图片进行ip定制,CLIP可以更好地发挥


ipa_plus_face 和 ipa_faceid和 ipa_faceid_PlusV2区别
ipa_plus_face:基于clip_version进行
ipa_faceid:基于insightface库进行
ipa_faceid_PlusV2:融合clip_version和insightface运行

权重:
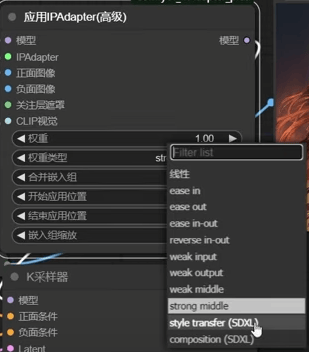



Ease in out : 提词起不了多大作用






Style trsansfer(SDXL) ,也并不一定是sdxl才能用,兼容sd1.5模型
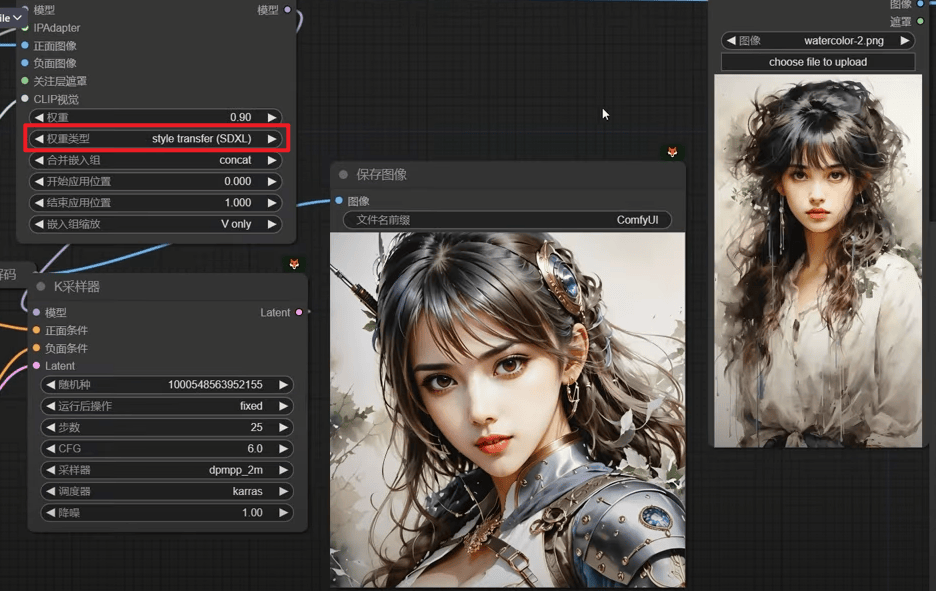
composition(SDXL) 只模仿构图

负面图像是用来校正成品图片的
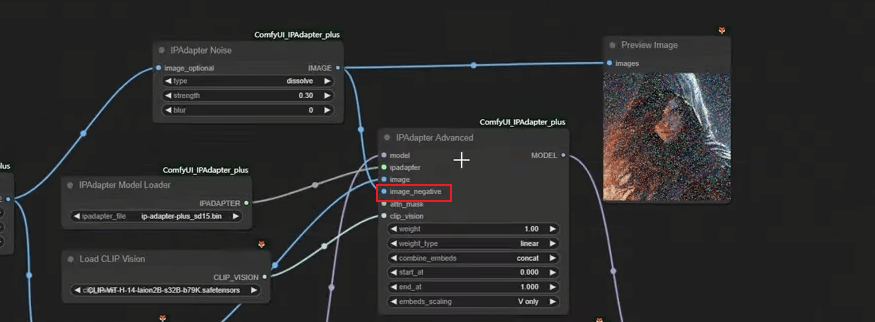
3.11 InstantID
默认通过CN参考原图的头部位置,如果需要额外的面部控制,可以给另一个图片来控制头部位置
更多参考图,组批次
3.12 DynamiCrafter
安装方式:Manager安装
配合Dynami的模型 下载至checkpoint

【特点:擅长物理世界的东西的运动】
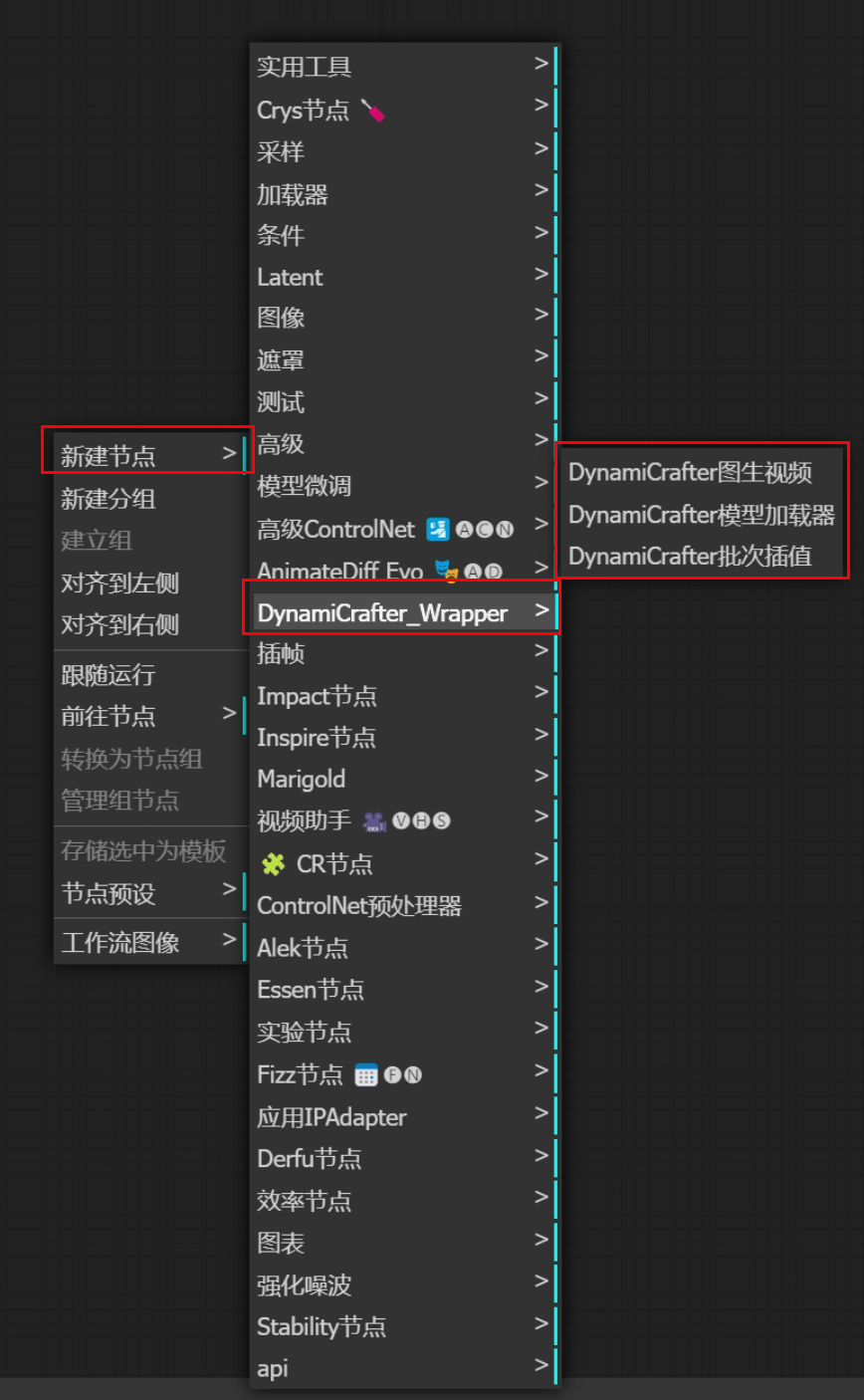
插帧
起始和末尾画面都给
四、工作流构建
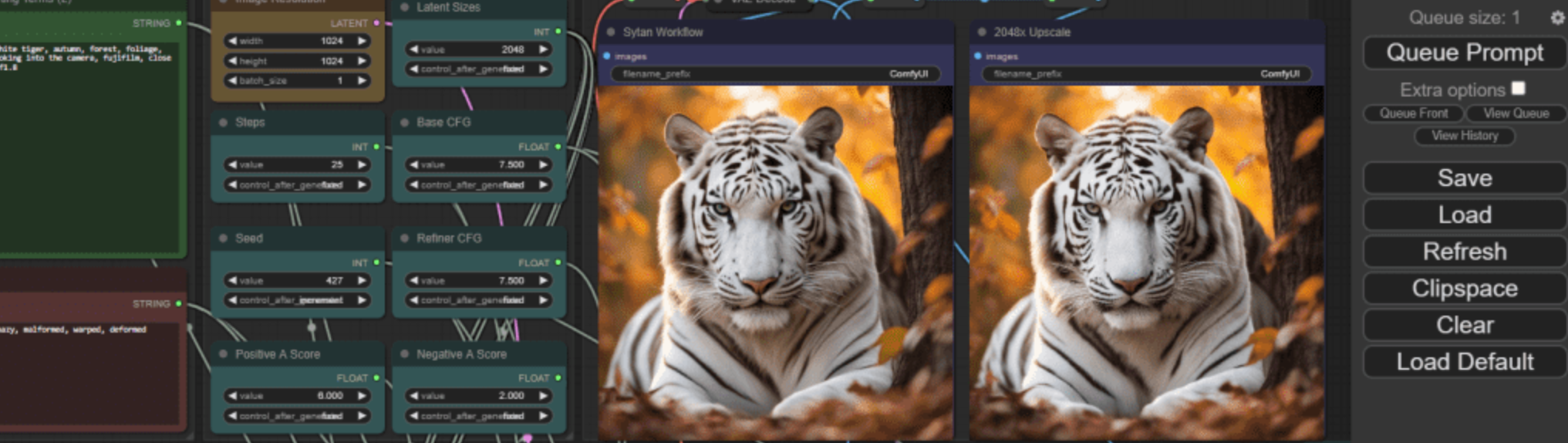
4.1 放大
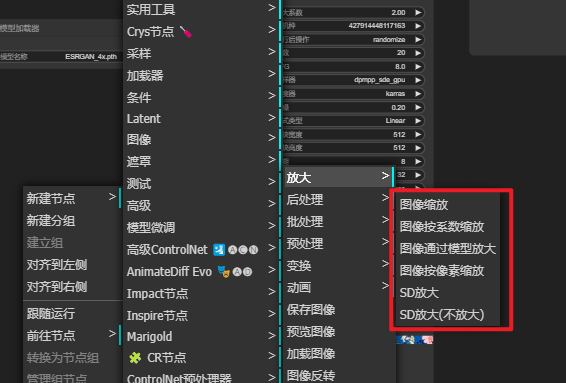
自建放大模板:
① 二重放大(2 Step Normal Scale)
原始图像——>① 潜空间放大(Latent)——>②模型放大——>出图
.png)
② 三重放大(3 Step Super Scale)
原始图像——>① 潜空间放大(Latent)——>②SD放大——>③模型放大——>出图
.png)
① 潜空间放大

SD 放大

运行速度:
模型放大 < 潜空间放大(二次采样)< SD放大
4.2 SDXL风格化文生图
简易SDXL风格文生图流程
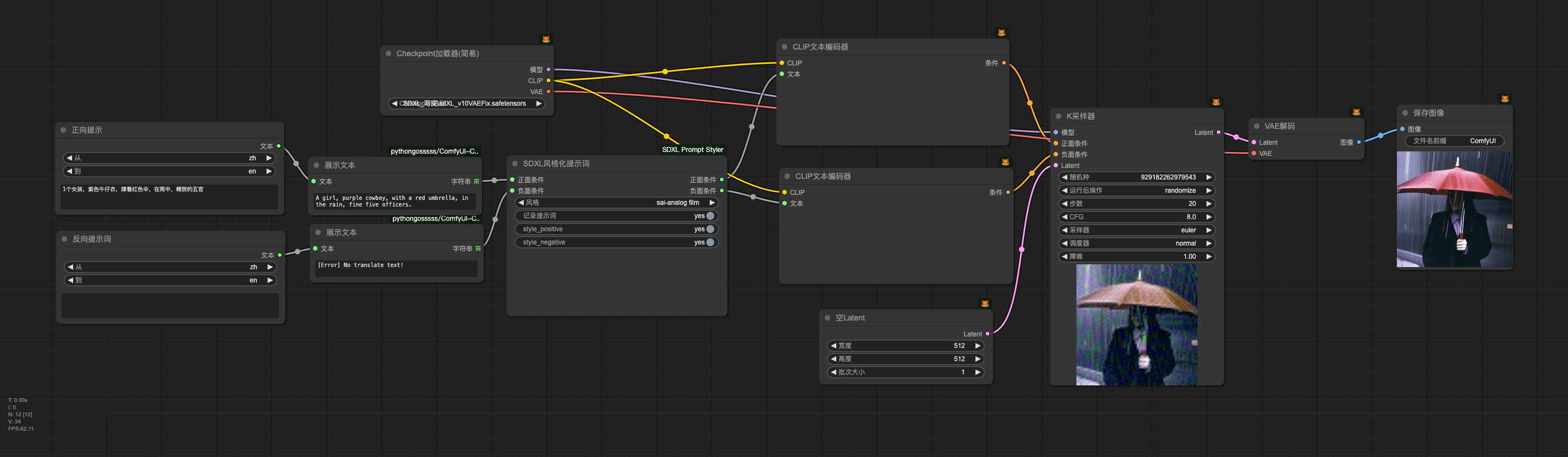
高级SDXL风格文生图流程
.png)
4.3 ControlNet
LineArt 文生图
其余CN模型同理
.png)
LineArt 图生图
其余CN模型同理
.png)
4.4 快速出图
V1.5 :LCM
SDXL:SDXL-turbo
LCM
SDXL-turbo
4.5 SVD
影响运动强弱的参数
SVD_图像到视频条件
增强:数值越大运动越强适合风景广角运动(模拟无人机飞行效果)
简易版
.png)

4.6 ComfyUI-AnimateDiff
能够影响画面运动的参数:
① 运动幅度:
AnimateDiff 加载器
缩放系数:(运动强度),数值越高运动越大
LoRA模型强度:(运动强度),数值越高运动越大,但是影响的不大
LoRACLIP强度:(运动强度),数值越高运动越大,但是影响的不大视频时长:时长长度过短也会导致运动幅度不够
② 视频长度:
AnimateDiff 上下文设置
上下文长度: 一个视频总帧数
批次大小:(全部帧数)
疑问
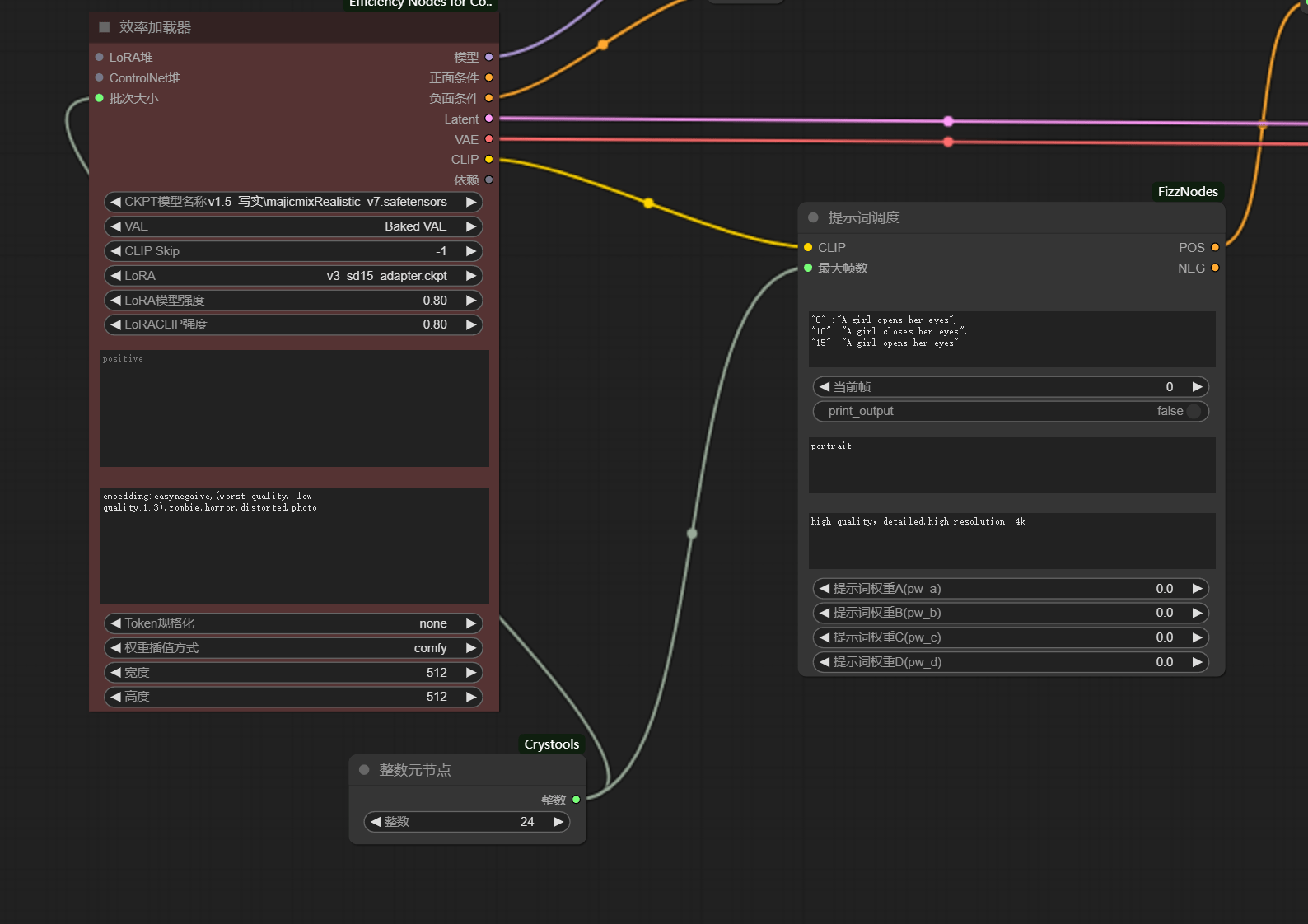
这里的元节点数直接影响了生成帧数
t2v
AD文生视频 + 提示词微调
控制动态:
- 动态扩散加载器
运动缩放- LoRA强度
- 视频时长
.png)

AD文生视频 + 提示词微调 + CN控制优化 + 补帧
控制动态:
- 动态扩散加载器
运动缩放- LoRA强度
- 视频时长
.png)
i2v
AD图生视频 +单图 + 高级CN控制
控制动态:
- 动态扩散加载器
运动缩放- LoRA强度
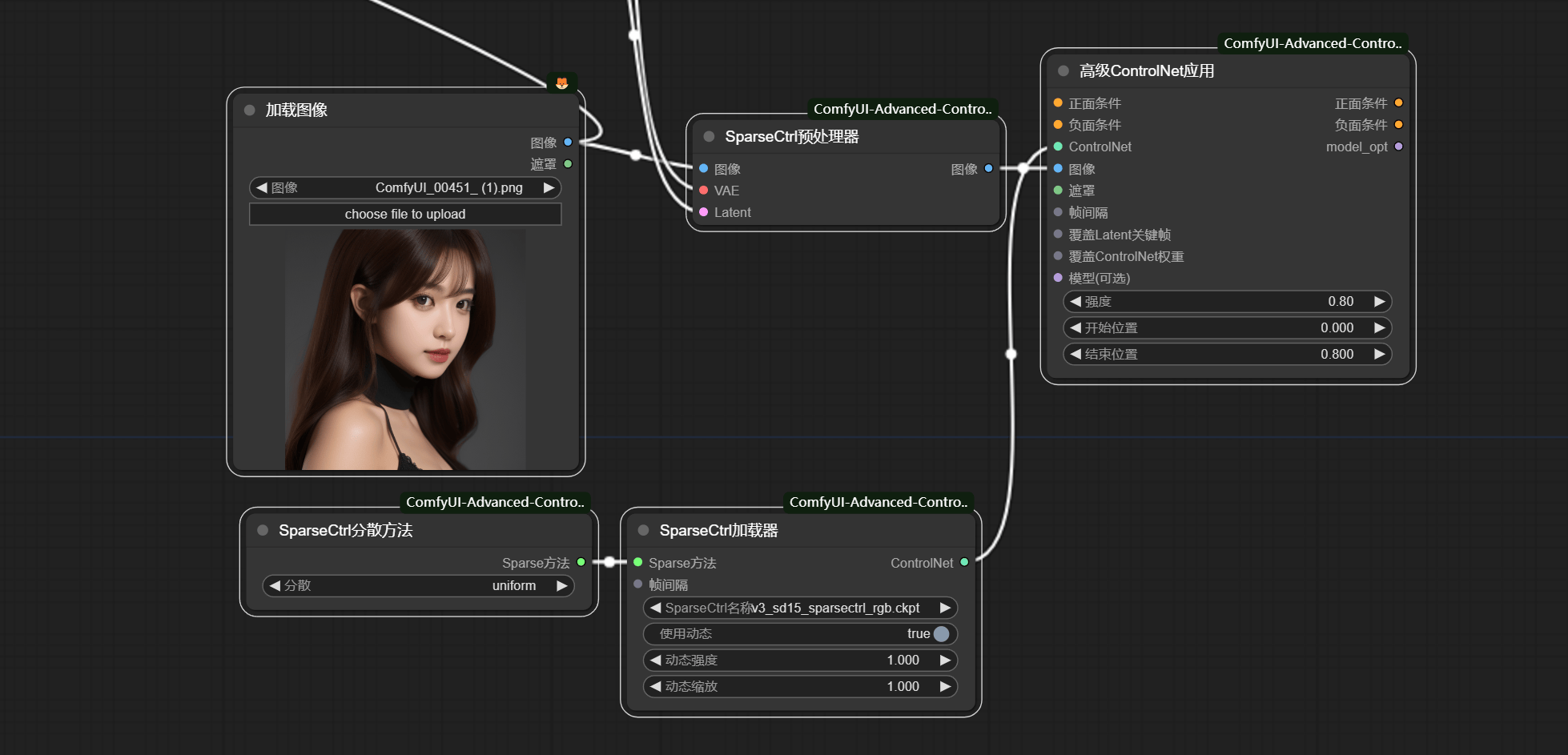
- SparseCtrl 加载器
动态强度动态缩放- 高级ControlNet
强度- 视频时长
.png)


AD图生视频 +双图 + 高级CN控制
.png)


v2v
加载器——>2个CN——>K采样——>输出
.png)



4.7 DynamiCrafter
基础一图流
.png)
要用专用的 1024 模型


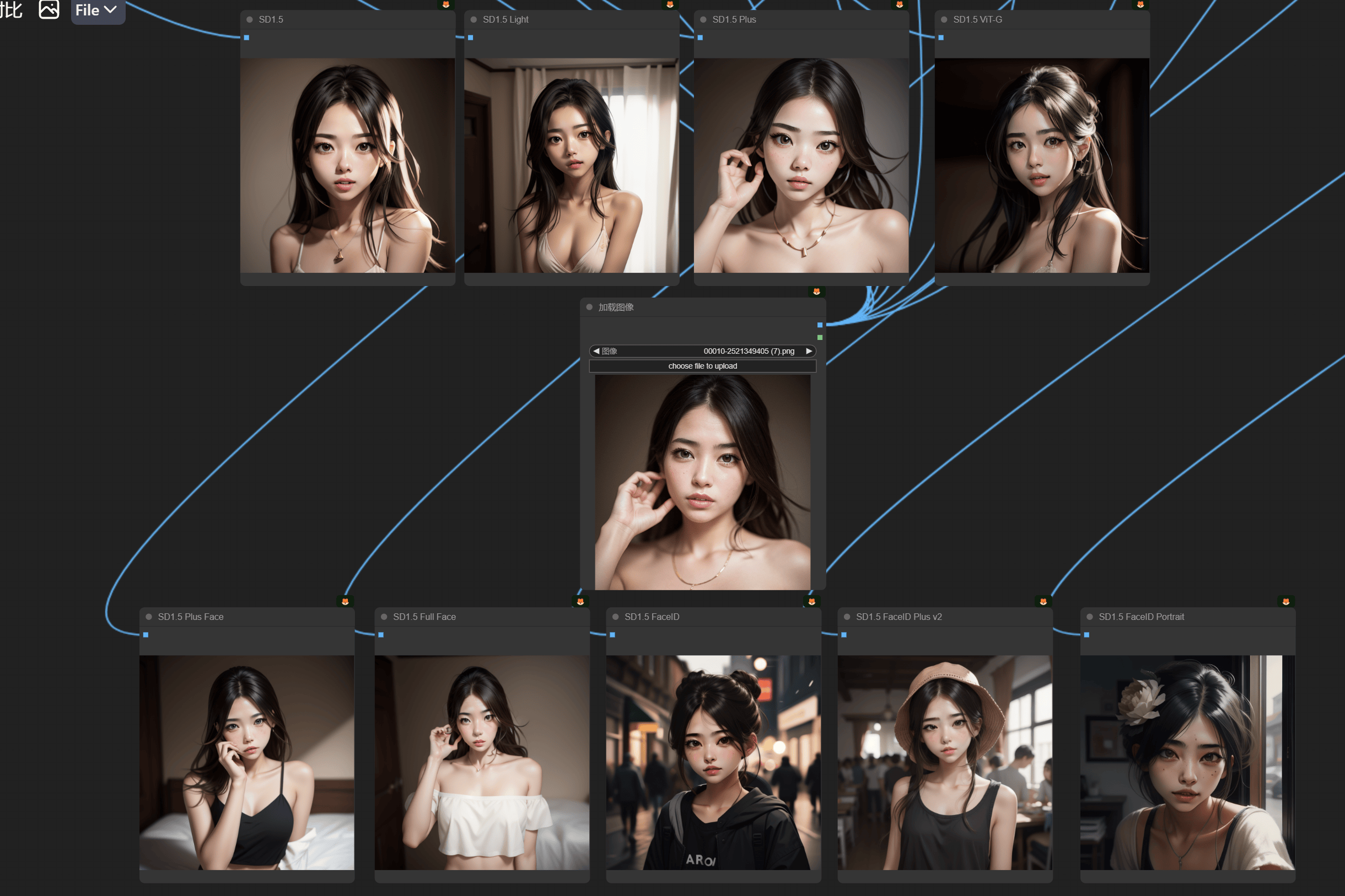
4.8 IPAdapter 各模型对比
4.9 风格转绘
关键在于【迭代思维】
① 不同IPA模型的选择(sd1.5 或者 light);
②
IPA强度和CLIP强度的协调,然后二次递进或递减来调整风格;③ 大模型的风格是否契合;
④ 参考图也可以 1个 切分成 2个(没那么重要)。
.png)
调整提示:
IPA模型:参考
3.10 IPAdapter,不同模型有不同的画面特点;应用IPAdapteer
权重:参考画面(风格)的强度;K采样器
CFG:越大CLIP提示词对图片的影响越大。
Style trsansfer(SDXL) ,也并不一定是sdxl才能用,兼容sd1.5模型
composition(SDXL) 只模仿构图
控制“风格度”:
先
模型放大编码解码重采样(重绘幅度0.4左右)(适当调整二次采样的CLIP)
- 递进(加风格):原始模型输出 + IPA【具体:增加IPA强度(调大
缩减CFG值)】- 递减(去风格):主模型重绘能力去调回本来样子

4.10 InstantID
特点:
更”像“
仅支持 SDXL 模型
对clip提示词支持更好
推荐CFG:3-5
更多参考图,组批次
纯 InstantID
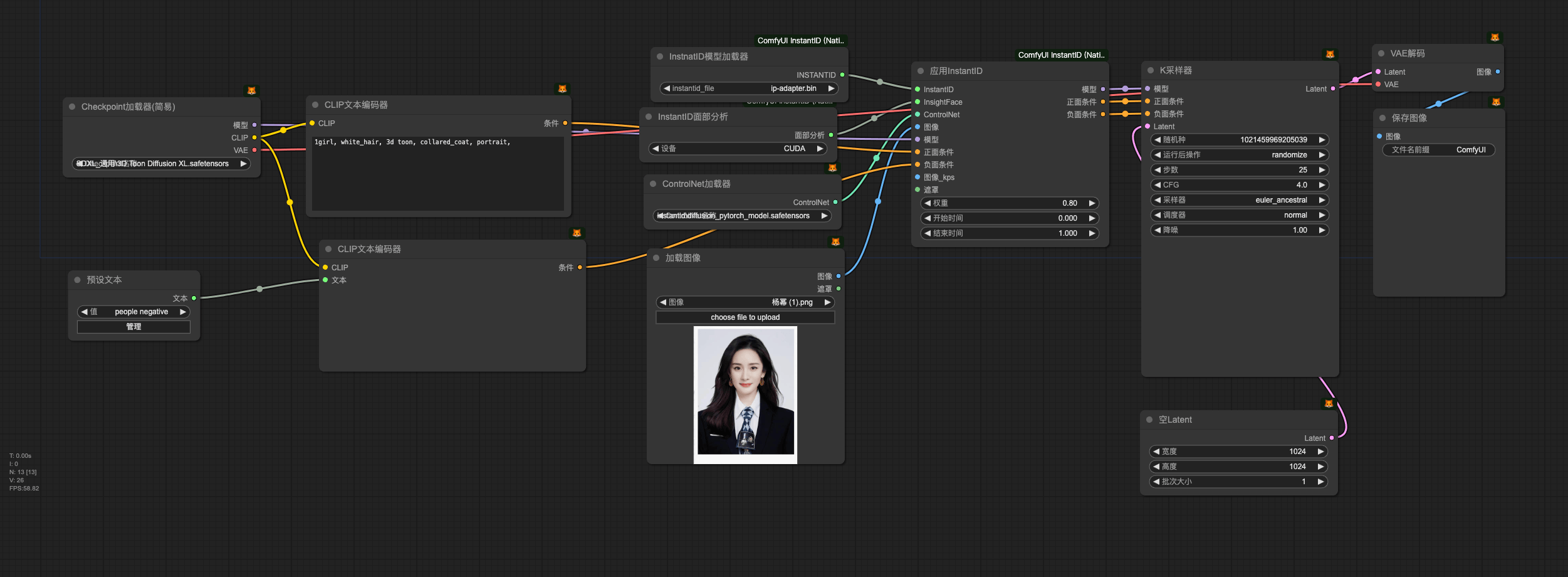


InstantID + IPA 二次识别
- 注意权重
- 直接用 PLUS 版本的 IPA 可能会导致环境被影响
- 解决办法:给人脸画遮罩mask,直接把mask连接到IPA
- PLUS版本需要裁切人脸,
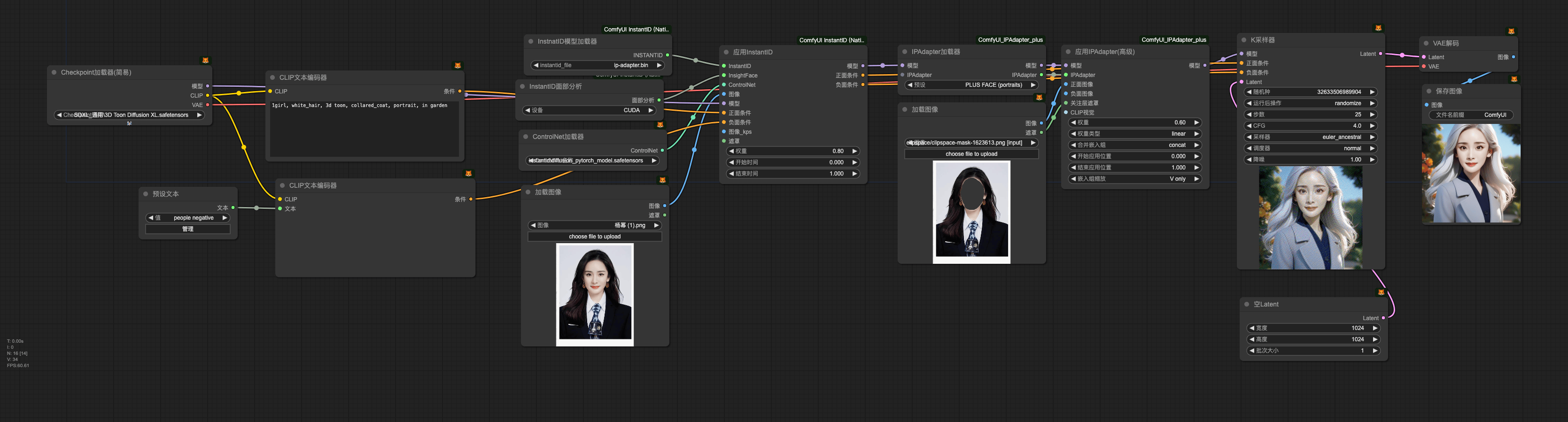
InstantID + IPA + 风格模仿
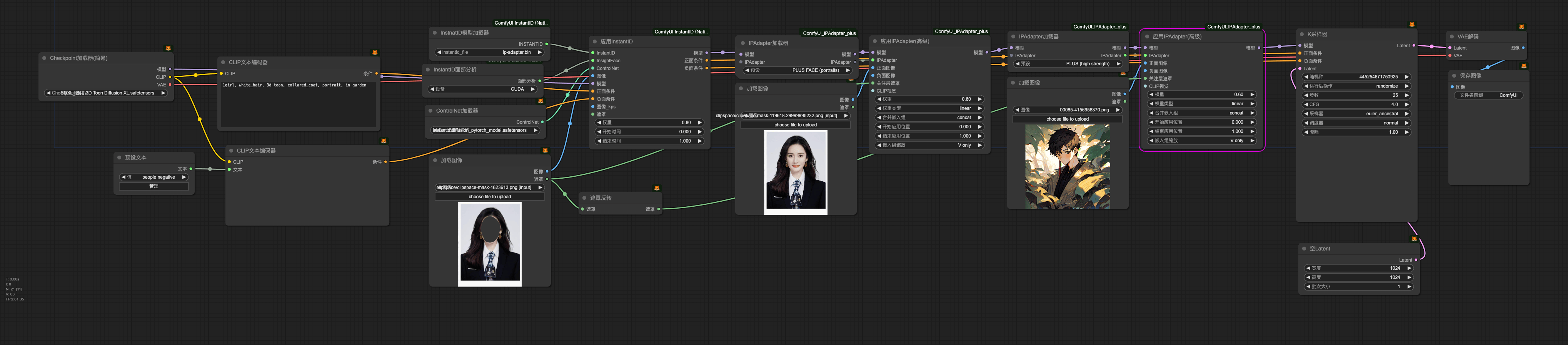
调整遮罩强度
目的: 为了避免身体卡通,面部写实的情况。
遮罩强度为0时,面部完全由 两个组件 影响
强度0.5时,风格融合更好一点,稍微削InstantID 和 IPA对弱面部影响,稍微提升风格对面部影响
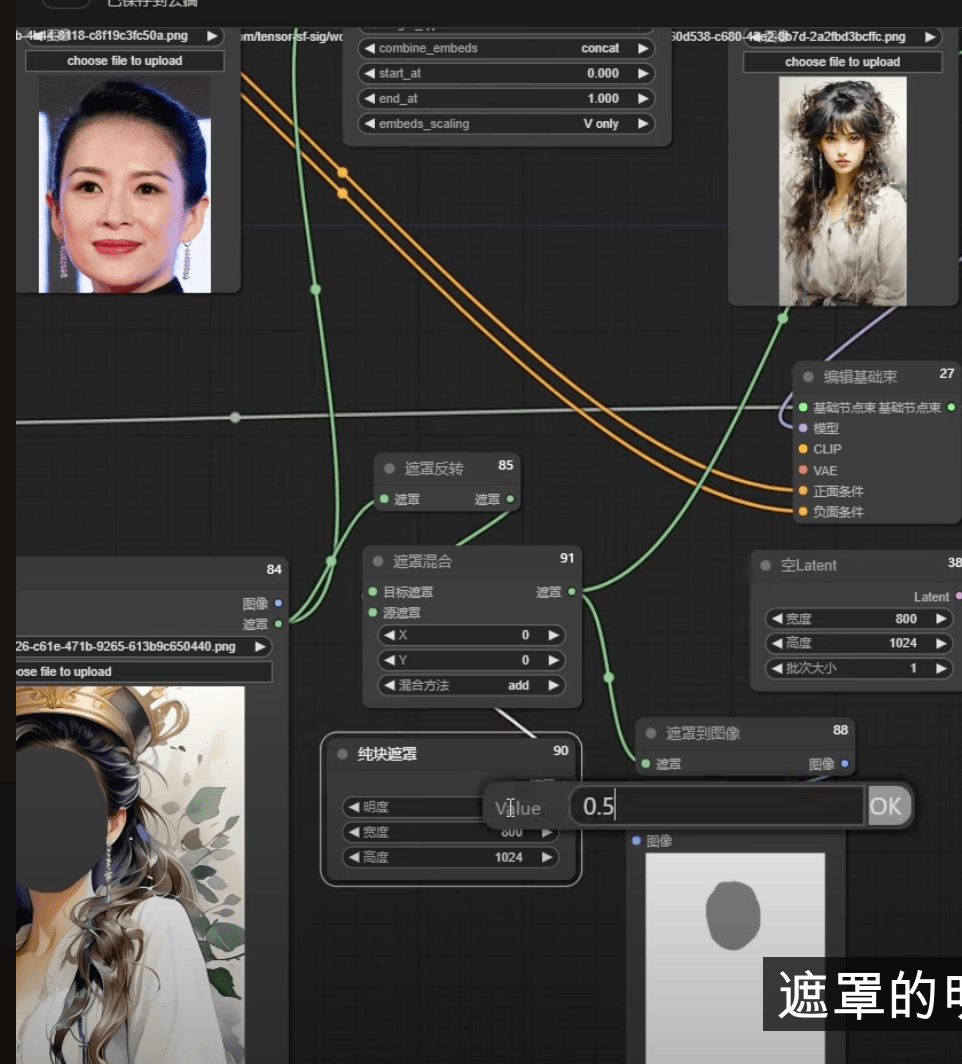
4.11 CLIP控制构图
ipact 和 inspire
Gligen
五、高级理解
ComfyUI高级理解(1) 图像合成、Clip分离精确控制Prompts,总有你不知道的小技巧! #comfyui #aigc - YouTube
- 不要频繁编解码,编解码是有损失的,pixel到letent空间是 除以8的关系,在大佬的工作流里,一半只会有一次解码,后面还会跟一个图像修复
5.1 CLIP
CLIP具体过程如下图
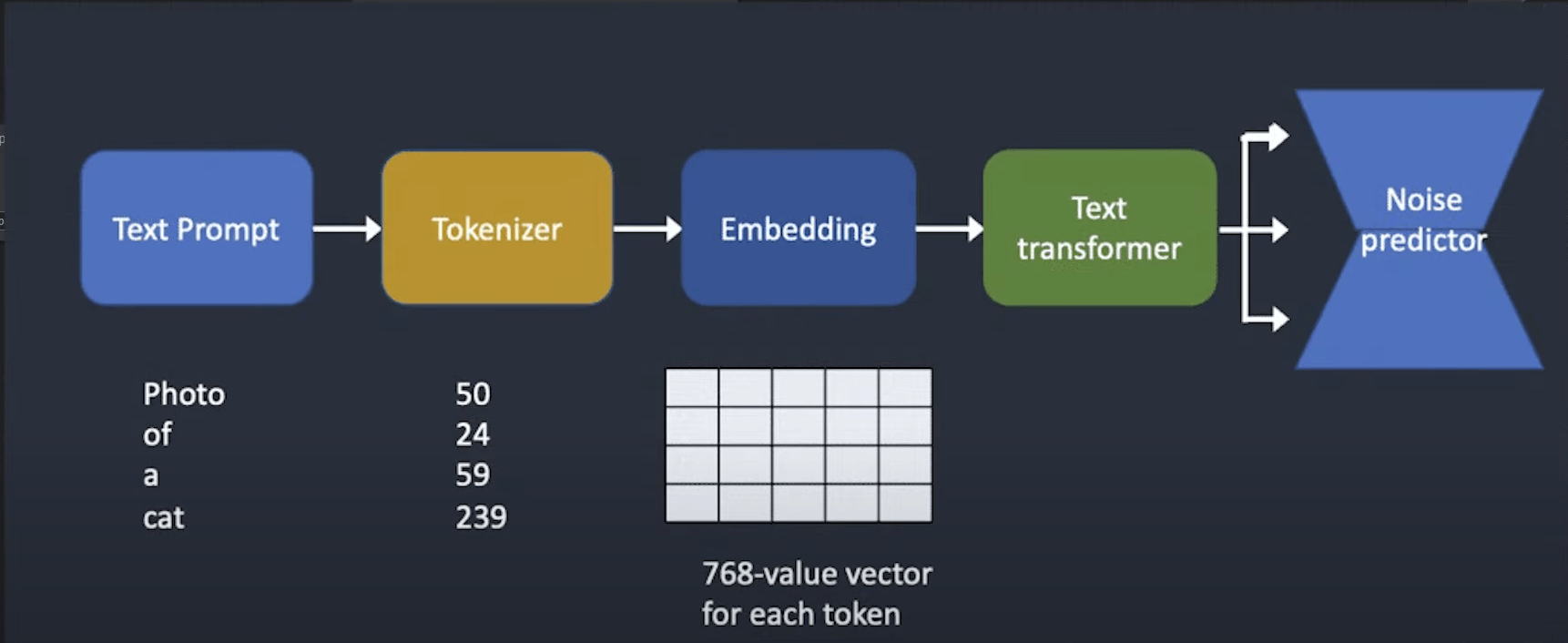

CLIP三种融合方式
作用1:提词隔离(
比如撑着伞的女孩打着红色的伞,但是可能衣服也被“染”红了)
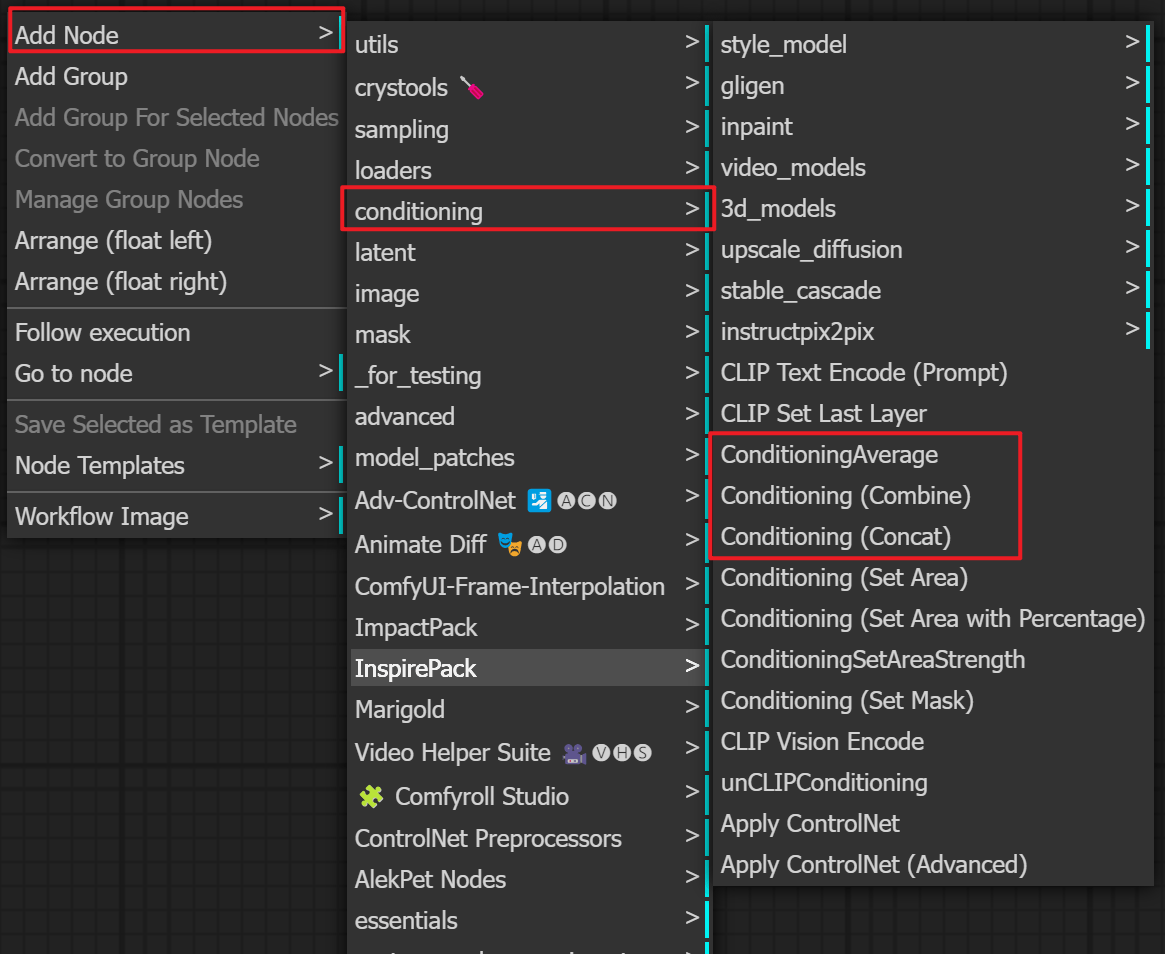

ConditioningAverage 条件平均
可以制作物种融合
插件卡片里的“系数” 是 上方条件的强度

Conditioning(Combine) 条件合并
适合平均采样
解决”染色”效果不好

Conditioning (Concat) 条件联结
可以比较完美的解决“染色”问题

CLIP SKIP
skip 跳过的越多,对提示词忽略的成分越多
1 | # 下图正面CLIP |

5.2 采样器
确定性采样器:step对整体构图影响不大,step高只是增加了细节;
非确定性采样器:step对整体构图影响特别大,大到感觉换了个seed一样。


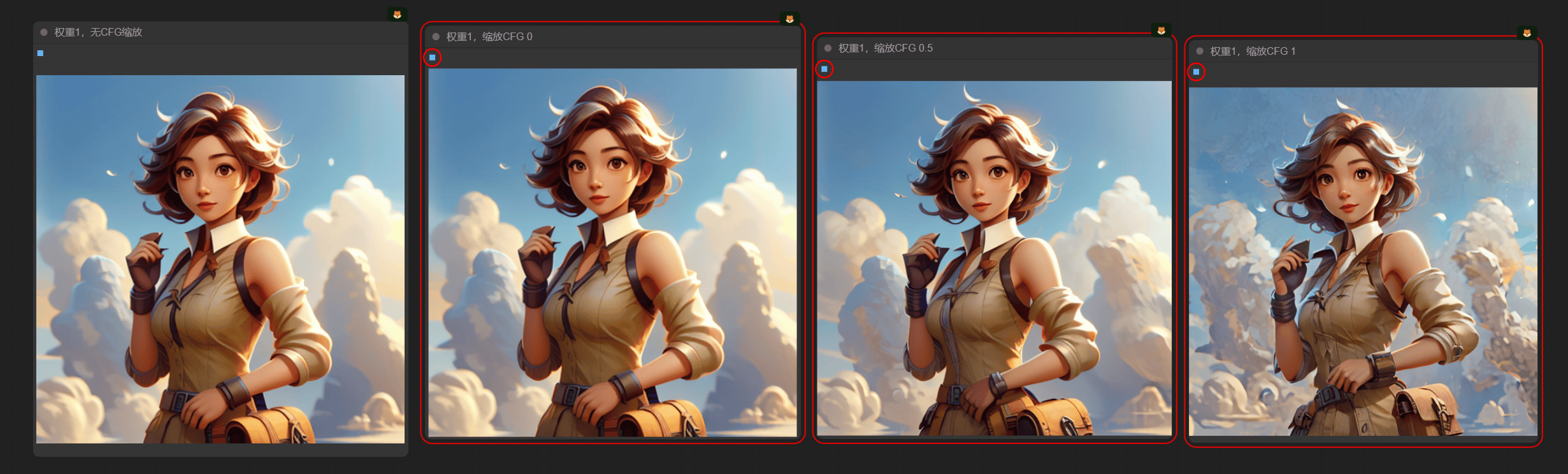
5.3 缩放CFG (Rescale CFG)
缩放CFG ≠ CFG *缩放值