
【PART 1 :DATA:2020-10-16 12:00:03】
聚类分析属于无监督学习方法,其目标是学习没有分类标记的训练样本,以揭示数据的内在性质和规律。具体来说,聚类分析要将数据集划分为若干个互不相交的子集,每个子集中的元素在某种度量之下都与本子集内的元素具有更高的相似度。用这种方法划分的子集就是“聚类”(或称为“簇”),每个聚类都代表了一个潜在的类别。
分类和聚类的区别也正在与此:分类是先确定类别再划分数据;聚类则是先划分数据再确定类别。
聚类分析本身并不是具体的算法,而是要解决的一般任务,从名称上就可以看出这项任务的两个核心问题:一是如何判定哪些样本属于同一“类”,二是怎么让同一类的样本“聚”在一起。
分类——闵可夫斯基距离
聚(聚类算法)——k均值算法、EM算法, 密度聚类(最流行的基于密度的聚类方法是利用噪声的基于密度的空间聚类)、层次聚类、原型聚类 。
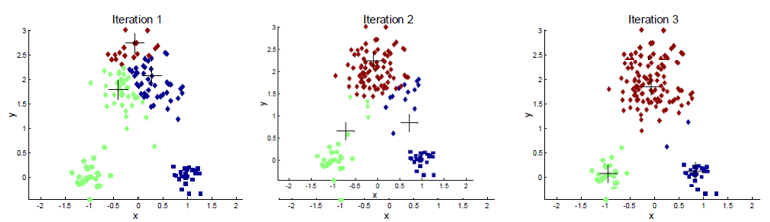
一、k 均值算法(k means):
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是,预将数据分为K组,则随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。 聚类中心以及分配给它们的对象就代表一个聚类。

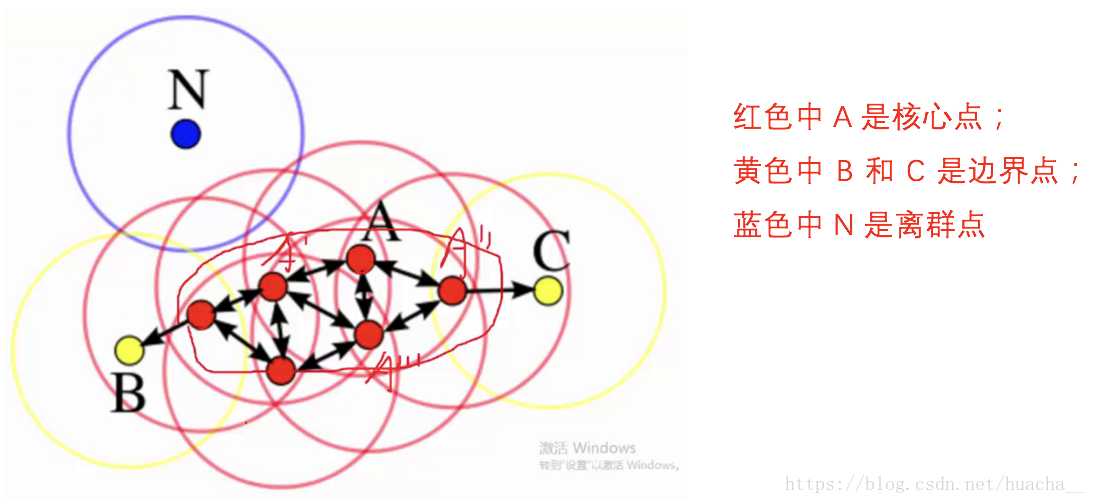
二、密度聚类(DBSCAN):
(形象来说,我们可以认为这是系统在众多样本点中随机选中一个,围绕这个被选中的样本点画一个圆,规定这个圆的半径以及圆内最少包含的样本点,如果在指定半径内有足够多的样本点在内,那么这个圆圈的圆心就转移到这个内部样本点,继续去圈附近其它的样本点,类似传销一样,继续去发展下线。等到这个滚来滚去的圈发现所圈住的样本点数量少于预先指定的值,就停止了。那么我们称最开始那个点为核心点,如A,停下来的那个点为边界点,如B、C,没得滚的那个点为离群点,如N)
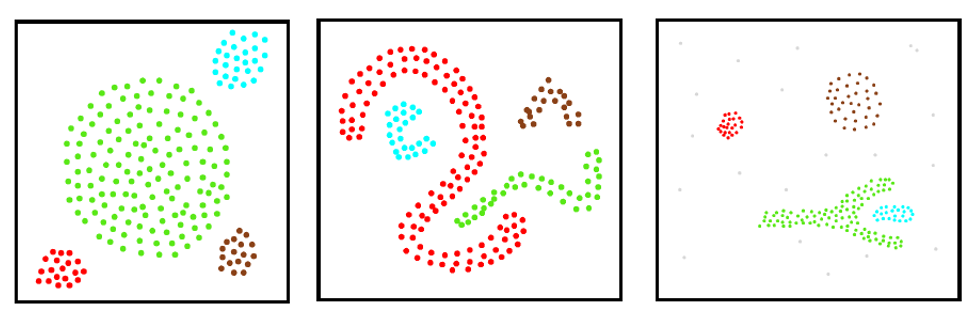
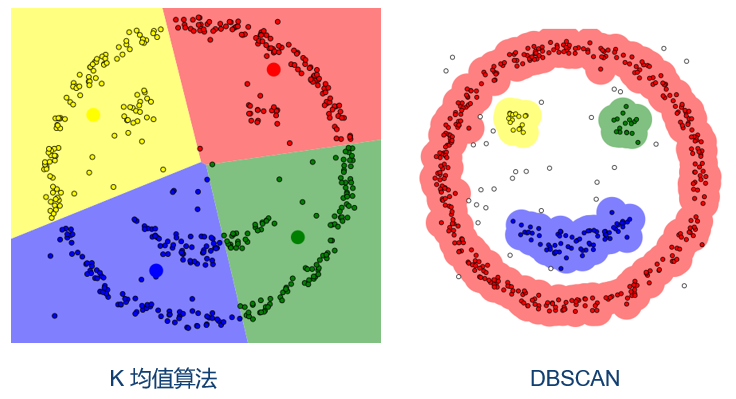
三、k-means vs DBSCAN
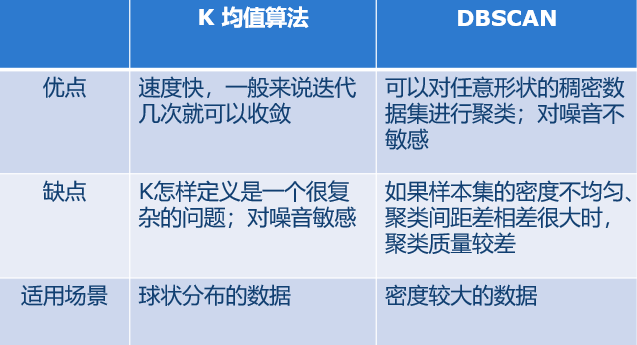
四、代码
k-means 代码:
【data.txt】
1 | 2.0 4.2 |
【kmeans.py】
1 | import random |
DBSCAN 代码:
1 | import numpy as np |
【PART 2:DATA:2020-10-16 12:00:03】
一、层次聚类
层次聚类试图在不同层次对数据集进行划分,从而形成树型的聚类结构。
问:层次聚类解决什么问题?
答:把明德 7 层这么多同学聚类,按什么标准聚?(按照专业 / 按照实验室 / 按照宿舍)聚成几个簇?就像是学号,第一位代表 研究生/本科,二三位代表年级,四五六代表专业,最后两位代表个人序号。
问:层次聚类怎么做?步骤?
答:


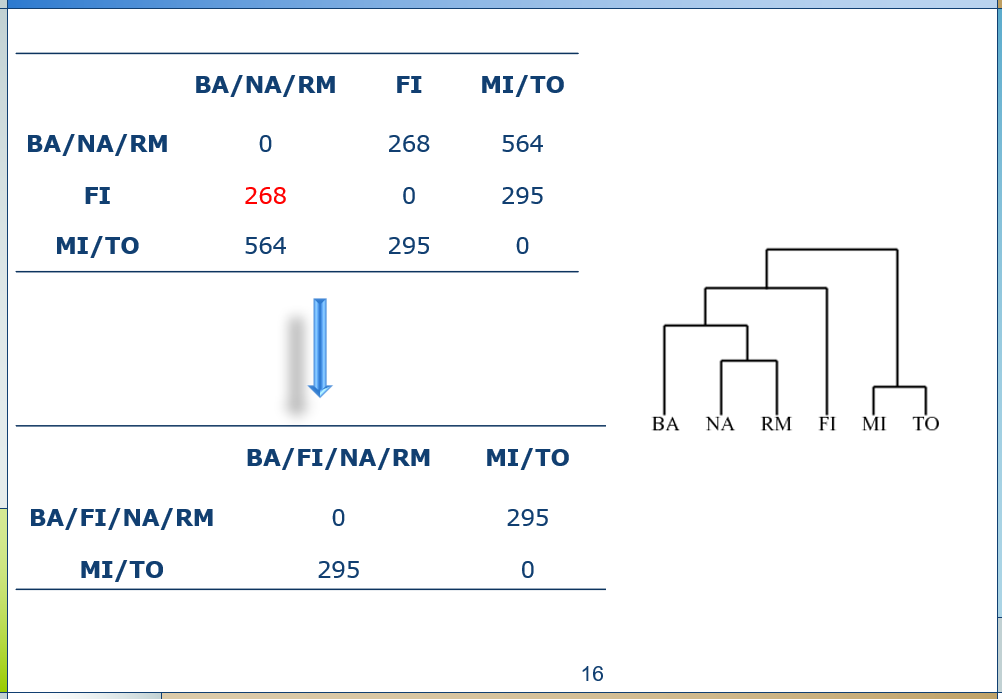
问:怎样判断相邻簇的距离(A簇有5个元素,B簇有3个元素,AB的距离?)
答:

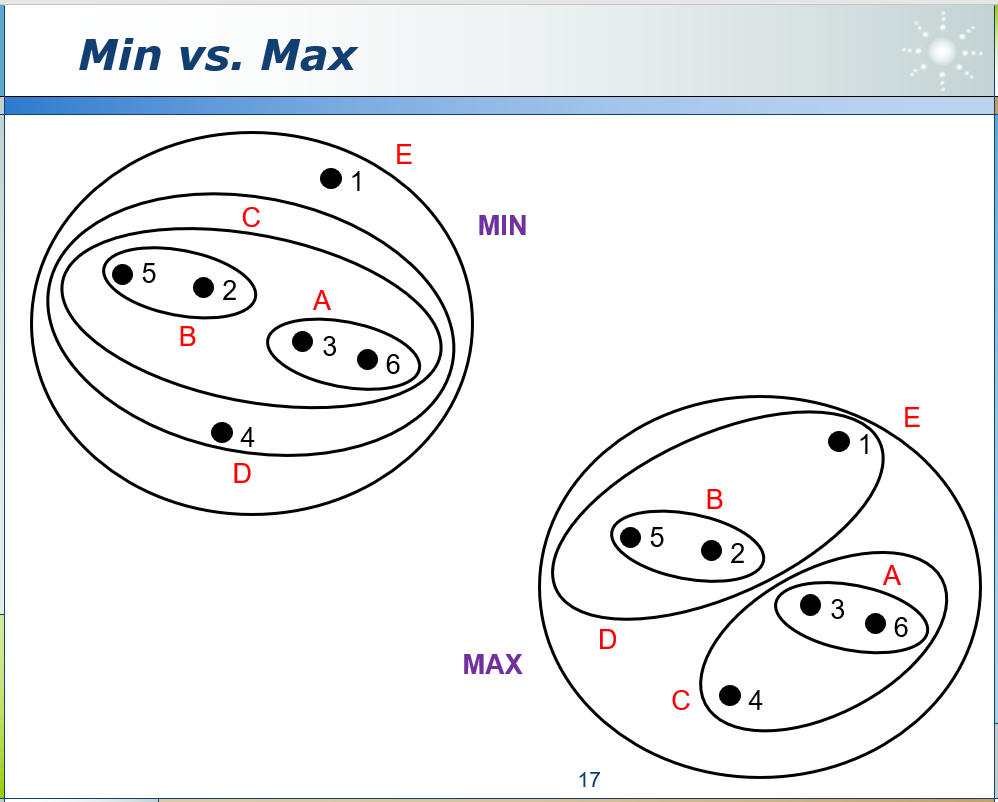
二、EM(最大期望值算法)
EM 聚类,英文是 Expectation Maximization,所以EM算法也叫做最大期望算法。
这个算法应该是咱们介绍这几个算法里最难理解的,我也是反复查资料才大概搞明白一点它的原理,但是我不认为我能讲清楚。所以我今天的介绍就通过两个例子,给大家讲讲EM算法的用途和建立一点感性的认识。
l 感性认识
首先咱们先建立一个感性的认识:我们先看一个简单的场景:假设你炒了一份菜,想要把它平均分到两个碟子里,该怎么分?
很少有人用称对菜进行称重,再计算一半的分量进行平分。大部分人的方法是先分一部分到碟子 A 中,然后再把剩余的分到碟子 B 中,再来观察碟子 A 和 B 里的菜是否一样多,哪个多就匀一些到少的那个碟子里,然后再观察碟子 A 和 B 里的是否一样多……整个过程一直重复下去,直到份量不发生变化为止。
你能从这个例子中看到三个主要的步骤:初始化参数、观察预期、重新估计。首先是先给每个碟子初始化一些菜量,然后再观察预期,这两个步骤实际上就是期望步骤(Expectation)。如果结果存在偏差就需要重新估计参数,这个就是最大化步骤(Maximization)。这两个步骤加起来也就是 EM 算法的过程。
EM算法和其他算法的区别是:K-means,DBSCAN得到的结果都是某个点属于哪个簇;但是EM不是这样的,它是基于模型的聚类,它是要建模,比如用高斯模型,这样做有什么用呢?有了模型以后咱们可以生成新的样本,新的样本和原来的样本是一致的。
三、代码
数据
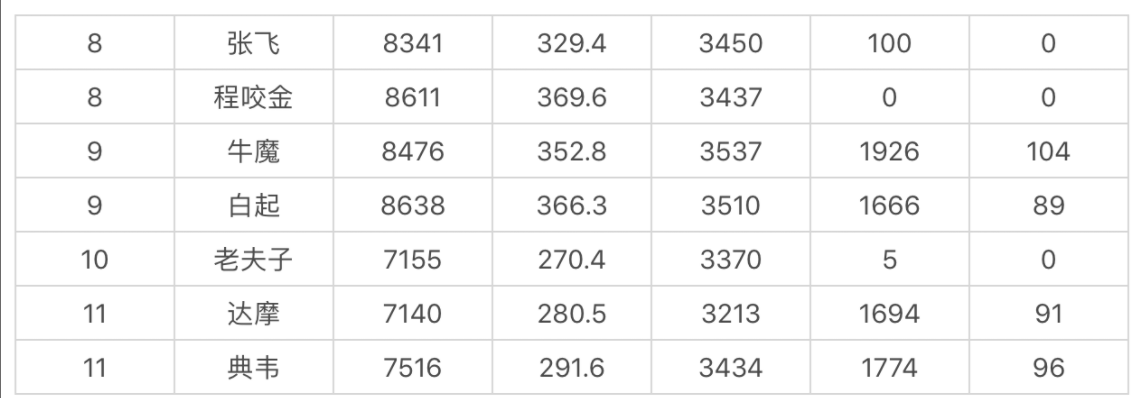
这里我们收集了 69 名英雄的 20 个特征属性,这些属性分别是最大生命、生命成长、初始生命、最大法力、法力成长、初始法力、最高物攻、物攻成长、初始物攻、最大物防、物防成长、初始物防、最大每 5 秒回血、每 5 秒回血成长、初始每 5 秒回血、最大每 5 秒回蓝、每 5 秒回蓝成长、初始每 5 秒回蓝、最大攻速和攻击范围等。
具体的数据集你可以在 GitHub 上下载:https://github.com/cystanford/EM_data。
具体代码
1 |
|
结果
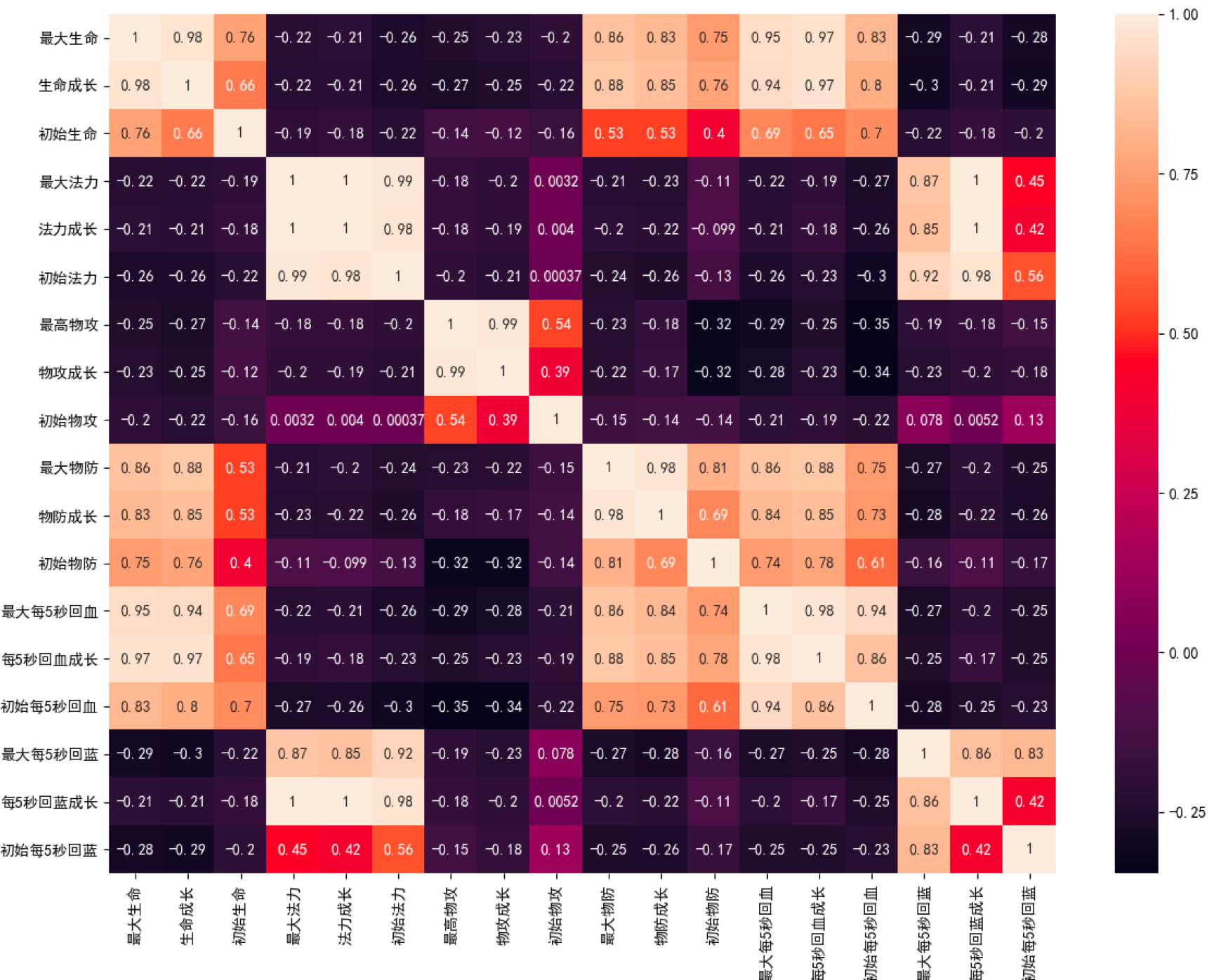
分析:
我们采用了 GMM 高斯混合模型,并将结果输出到 CSV 文件中。这里我将输出的结果截取了一段(设置聚类个数为 30):
.csv 文件乱码解决办法:
- 创建一个新的Excel文件;切换至“数据”菜单,选择数据来源为“自文本”选择 CSV 文件;
- 出现文本导入向导,选择“分隔符号”,文件原始格式选择“65001:Unicode(UTF-8)”下一步;
- 勾选“逗号”,去掉“ Tab 键”,下一步;
- 完成,在“导入数据”对话框里,直接点确定。导入之后,所有汉字显示正常,乱码问题解决。
