
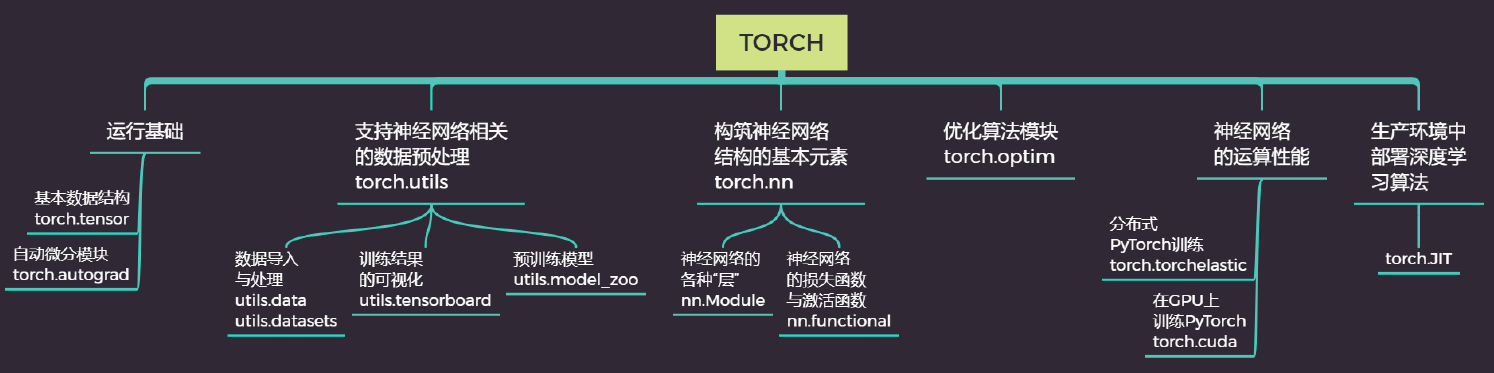
一、torch 结构

二、单层神经网络
1 手动实现
y :永远表示标签(labels)
z:表示预测值

这就是一个 单层神经网络,为什么是单层? 因为业内共识 “ 输入层” 不算在内。
- 简单小例子

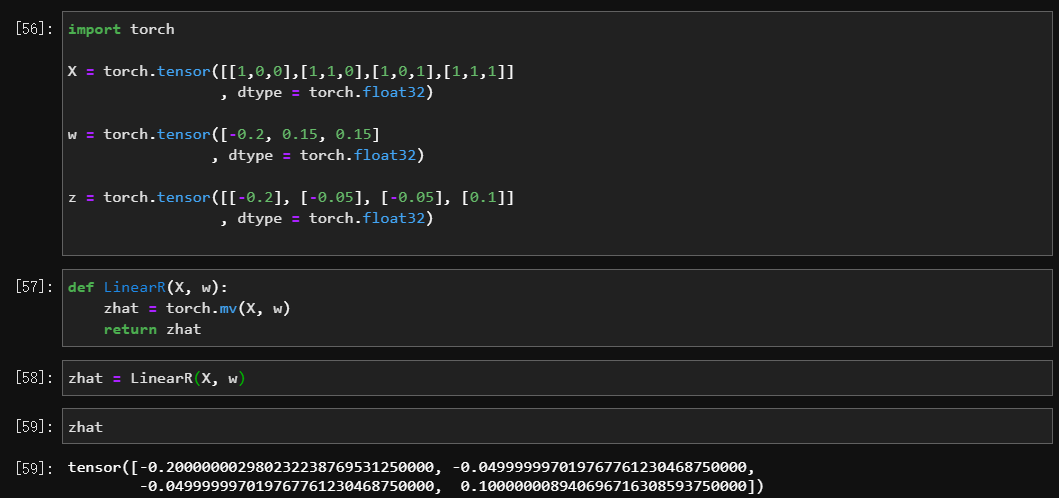
坑:
- 出现精度差异的原因:①float32精度差异,由于只保留32位,所以精度会有一些问题②
torch.mv这个函数在进行计算的时候,内部计算时会出现一些很微小的精度问题torch.tensor默认精度是自动匹配的,所以在做运算的时候有可能会报错,因此要养成良好习惯:都写成 float32torch.tensot([[x,x,x]], dtype = float32);- 同样是精度,一个 9 位数乘 10 再 乘 0.1 就会变得不同,对于这种情况可以用
dtype = float64来解决;- 明明相同的两个数 因为 e10-5 这样的精度问题比大小不同,可以用
torch.allclose(x, y)无视掉这种非常小的区别;torch.set_printoptions(precision = 30)可以更改全局小数点后位数。
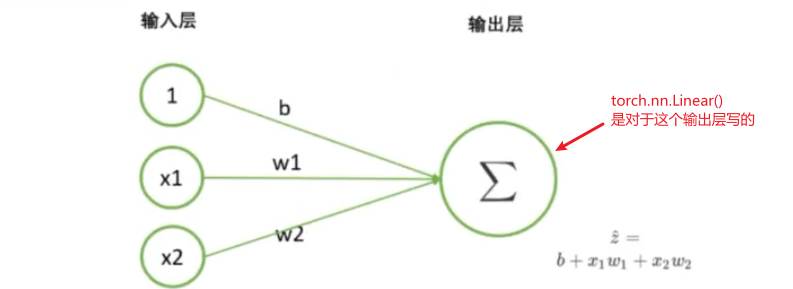
2 用 torch.nn.Linear 实现单层回归神经网络的正向传播
torch.nn.Linear是torch.nn.Module下的一个子类,表示 “ 线性层 ”。
同样的数据
1 | import torch |
nn.Linear 参数 :
- in_features:上一层的神经元的个数(上一层的神经元中,给这一层传输的神经元的个数)
- out_features:这一层的神经元的个数(接收传输数据的神经元个数)
- bias : 设置
bias是否要生成(bias 即线性回归的 截距/偏差)torch.nn.Linear在本例中是对于输出层来写的。参数的:上一层神经元,下一层神经元;也说的是输出层的上一层与下一层。

随机数种子:
“锁住”随机值————虽然是随机的,但是每次数值不再变化
查看随机生成的 w / b:
output.bias
output.weight
三、二分类神经网络
1 理论








sigmoid 函数的特点:
拥有把连续 转化为 离散 的力量!
- 加餐:



2 实践
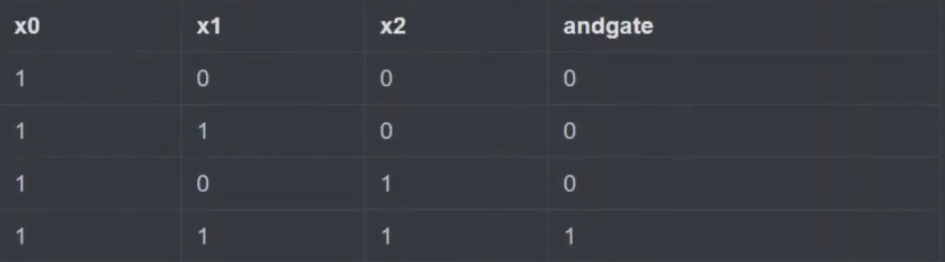

- 注解:
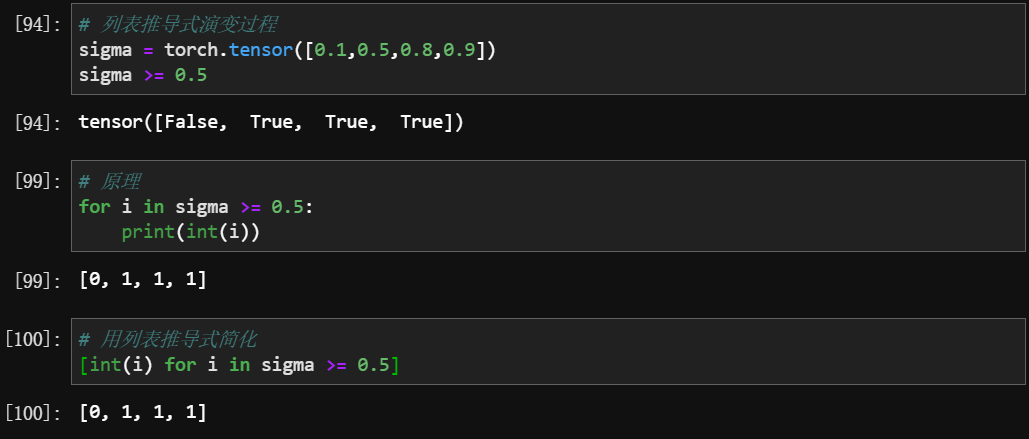


3 拓展 二分类函数
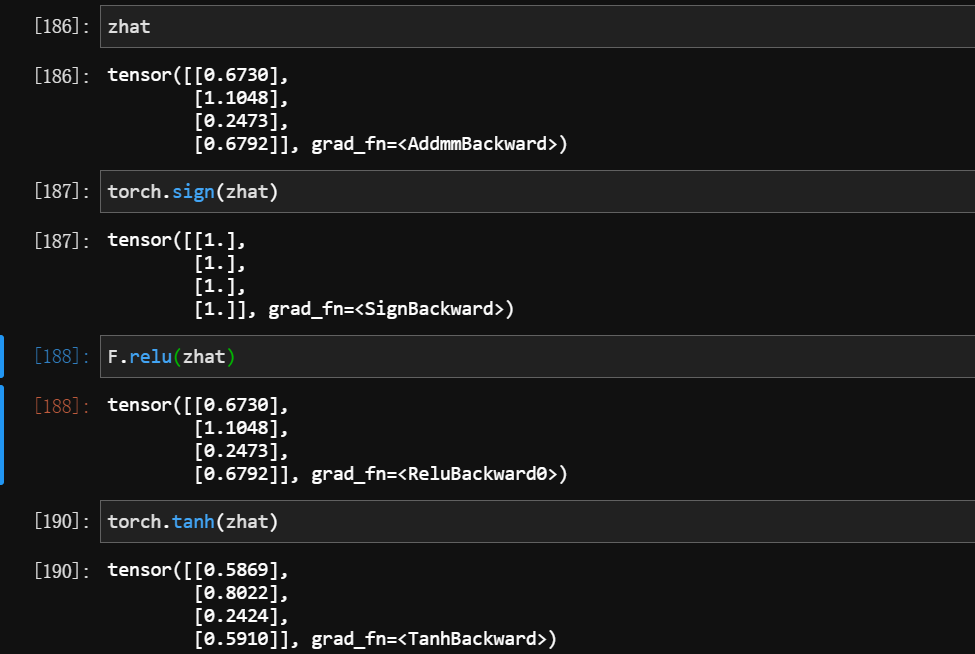
3.1 sign



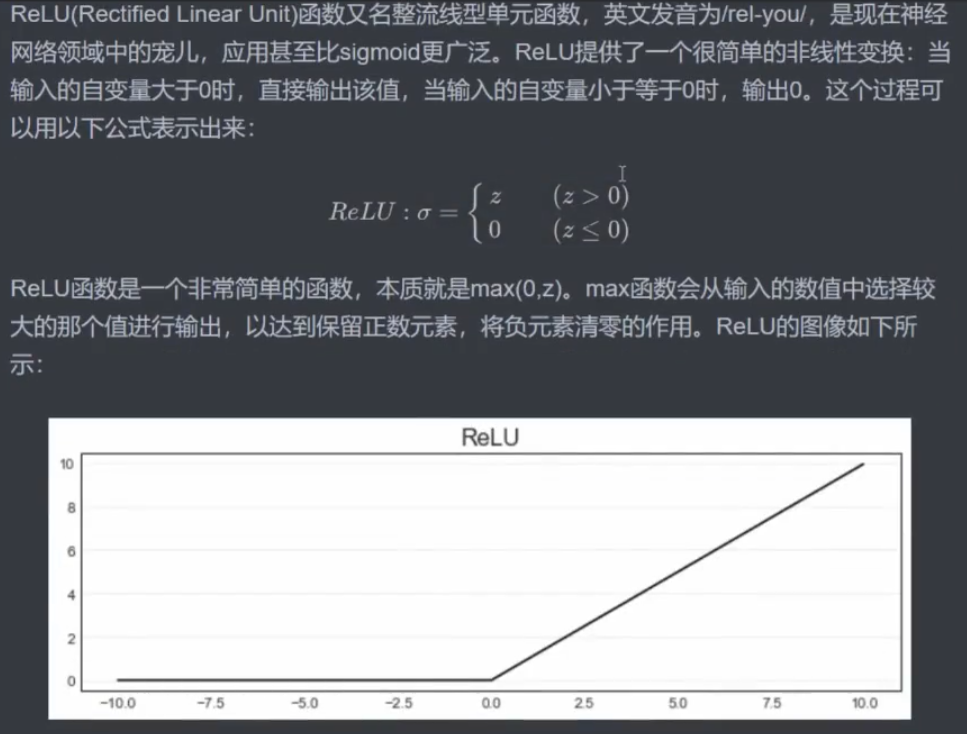
3.2 ReLU

3.3 tanh
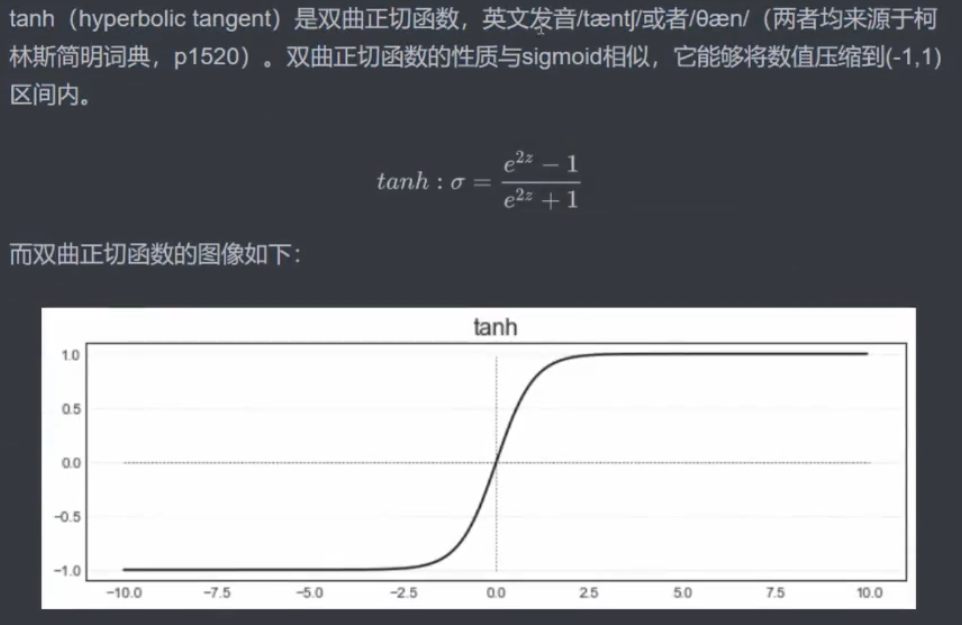
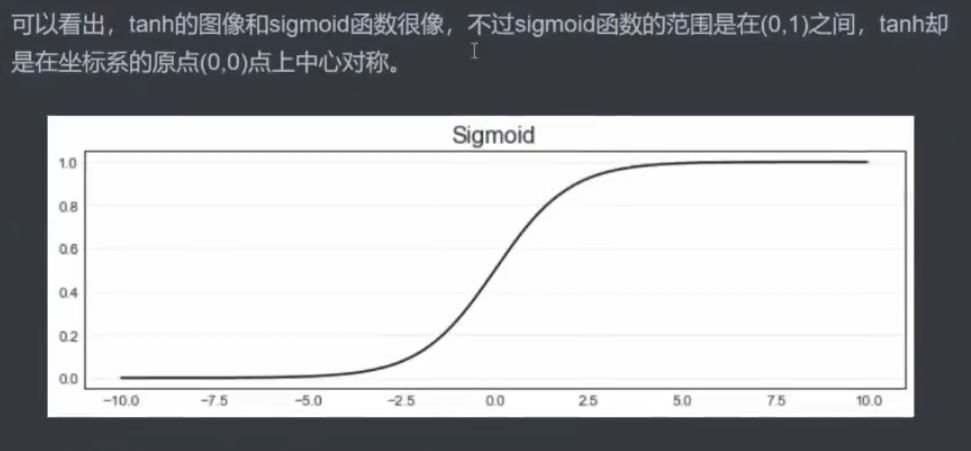
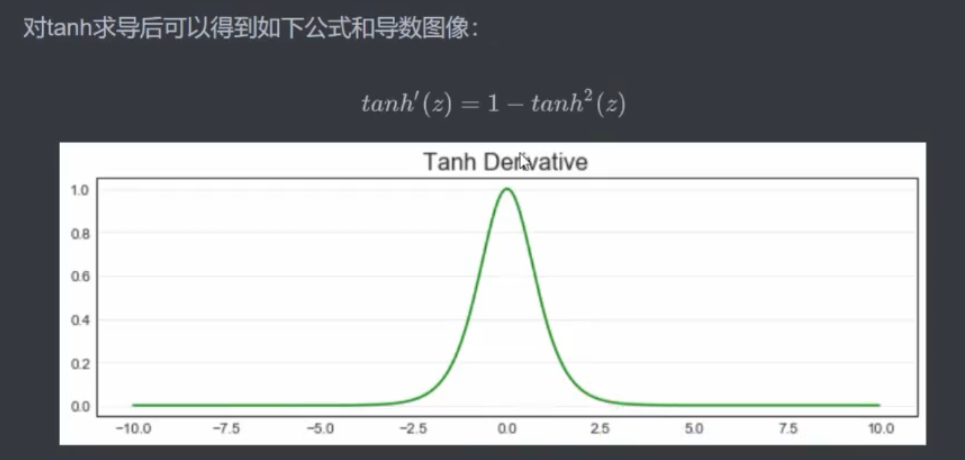
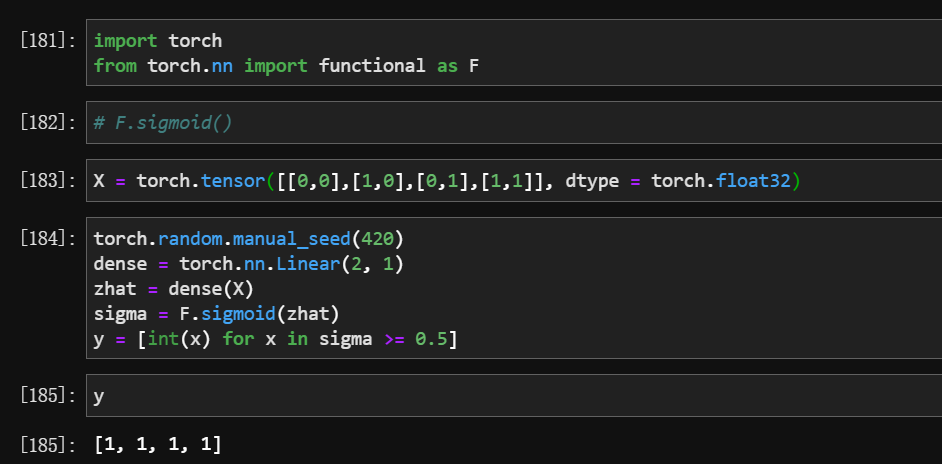
4 torch.function 实现单层未分类神经网络的正向传播
四、 多分类神经网络:Sotfmax 回归
1 基础理论

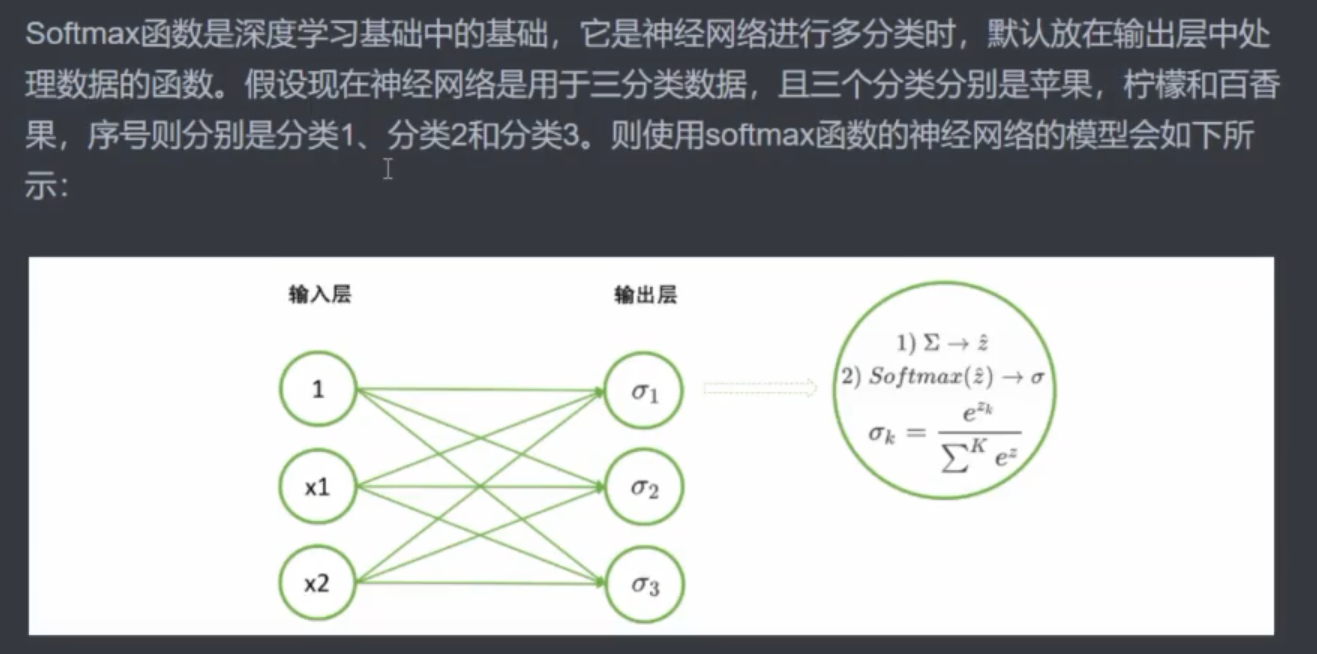



2 pytorch 中的 Sotfmax 函数
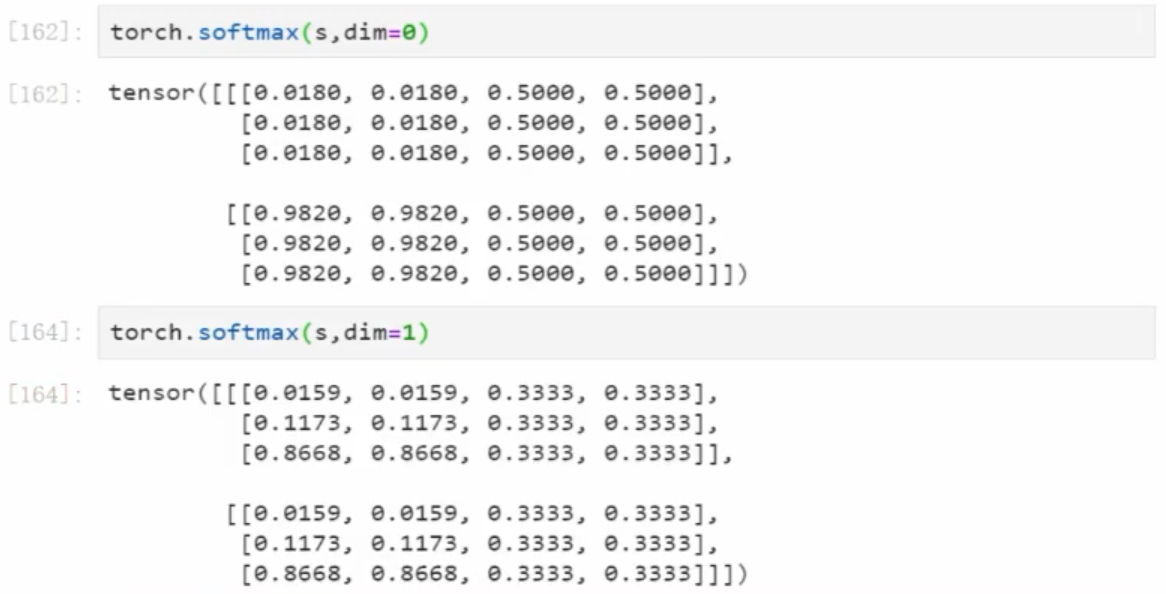
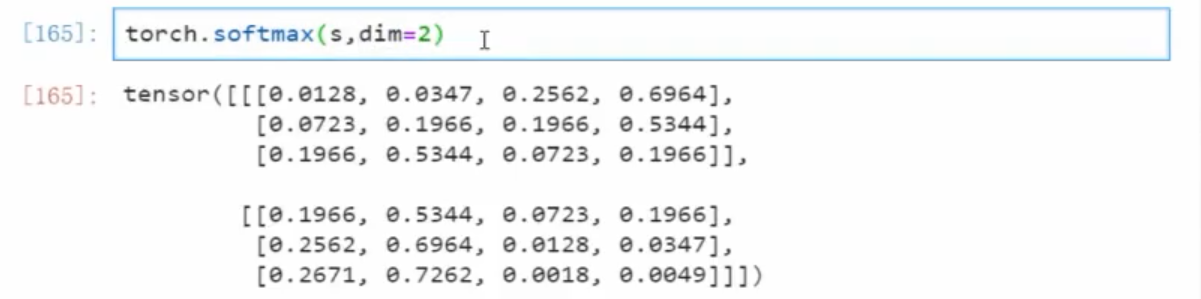
对 dim = ? 就是把 ? 代表的单位数据作为一个类别
对于 torch.shape = [2 , 3 , 4]
- dim = 0 每一块作为一个类别,【2个数加起来等于1】
- dim = 1 每一行作为一个类别,【3个数加起来等于1】
- dim = 2 每一个数作为一个类别,【4个数加起来等于1】
