一、门问题
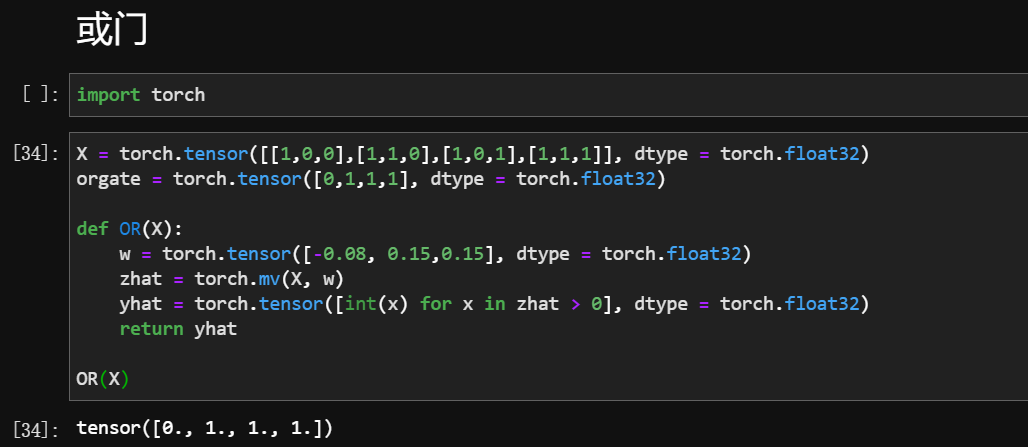
1 与门、或门(单层神经网络)

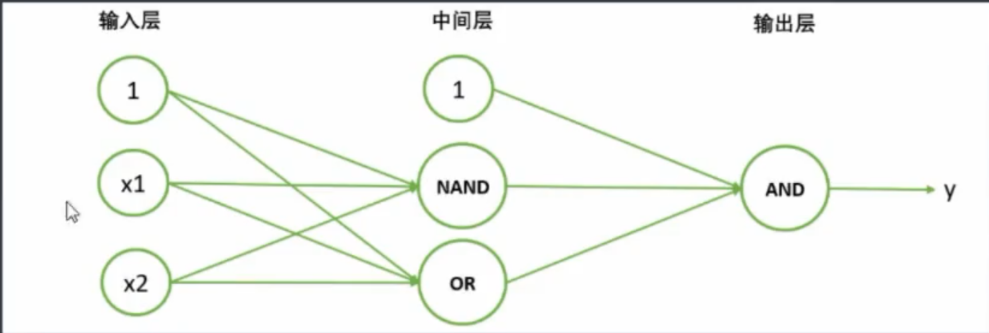
2 异或门(多层神经网络的基本形态)

torch.cat()用来合并几个向量
- 如果直接使用,三个一维张量只能横向合并成一个 一维张量。
- 应该使用 .view() 将它升维


二、黑箱:深度神经网络的不可解释性
神经网络结构:
- 多层神经网络比单层神经网络多出了“ 中间层 ”,中间层常常被称为 “ 隐藏层 ”
- 中间层功能:
- 加和
- sigmoid 、sign函数…… 【
h(z)】- 输出层 AND 功能:
- 加和
- 阶跃函数 变成 0 和 1……【
g(z)】- 加和是共有的,加和后使用的那个映射到 0~1 的函数称为 “激活函数”,中间层激活函数符号表示为
h(z),输出层激活函数符号表示g(z)
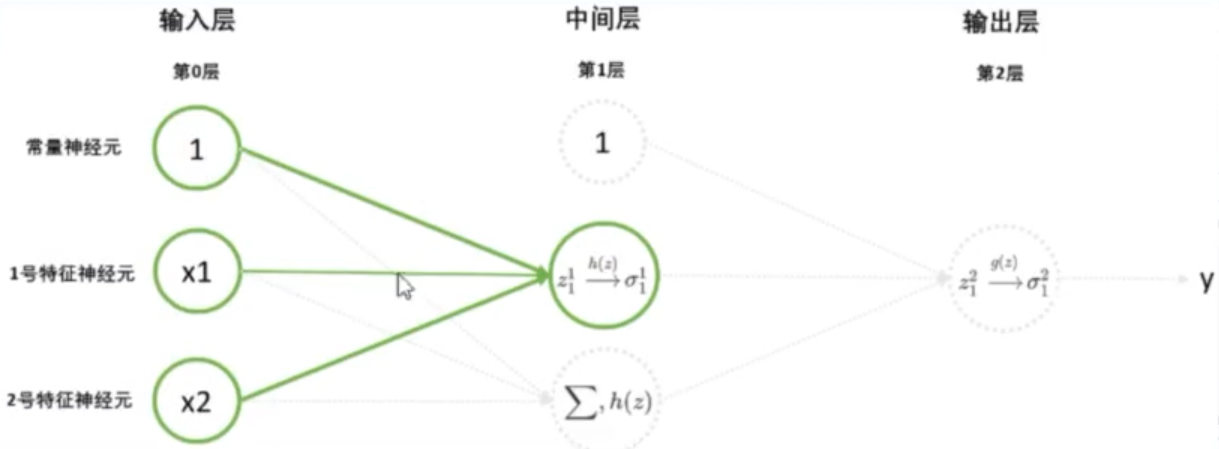
- 课本通用写法:
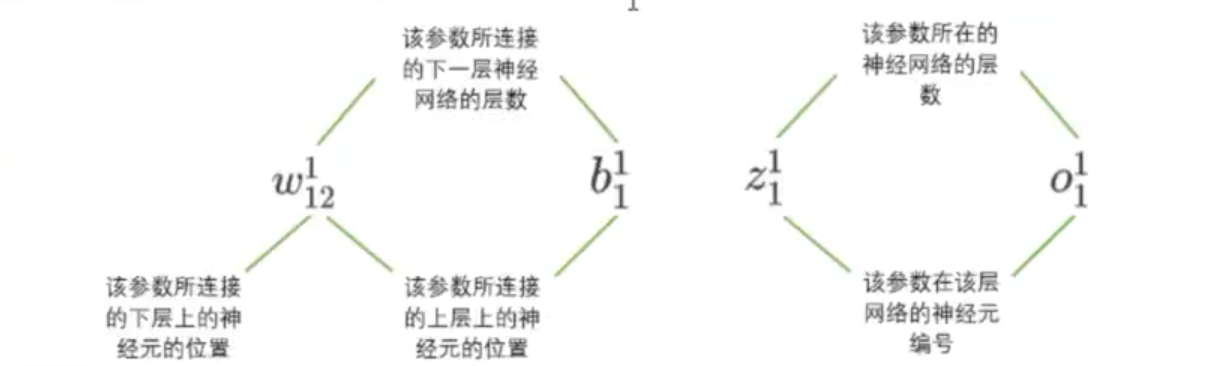
下层神经元:左边神经元
上层神经元:右边神经元
- 菜菜改进写法:
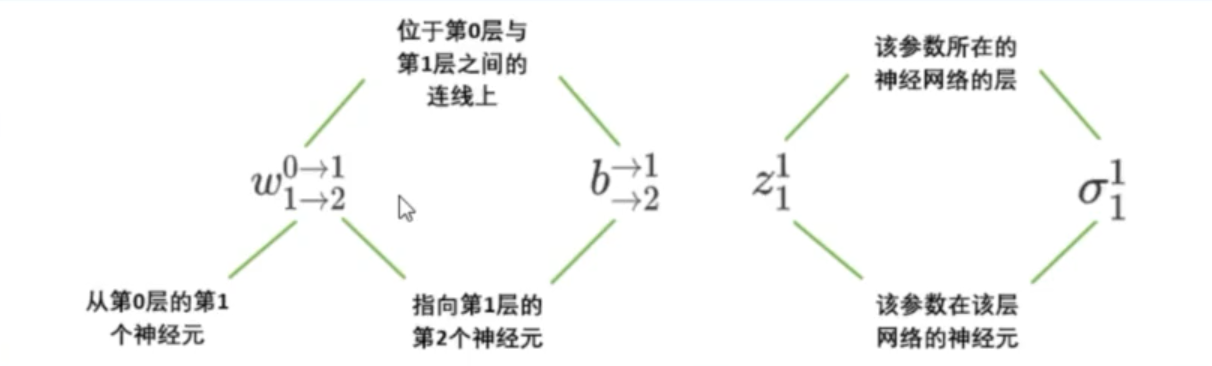
w:在神经元的连线之间,特征神经元间,左边神经元到右边神经元,上标是:第几层指向第几层;下标是:与上标对应的层的对应索引的神经元。
b:在神经元的连线之间, 常量神经元间,左边神经元到右边神经元,b 由于每一层都会有一个新的神经元,所以对他来说这个神经元是唯一的,所以没有起点,起点都是上层的常量神经元;上标是:指向第几层;下标是:指向该层的第几个神经元。
z:位于神经元的上面,加和的结果,上标表示层的编号,下标表示神经元的编号
σ:位于神经元的上面,加和之后的激活函数的结果,上标表示层的编号,下标表示神经元的编号
- 例1:
示例1: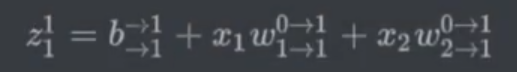
示例1图解: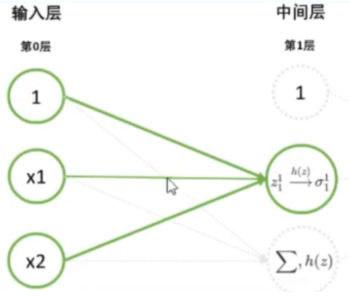

- 例2:
示例2:表示一下全过程
解答2:
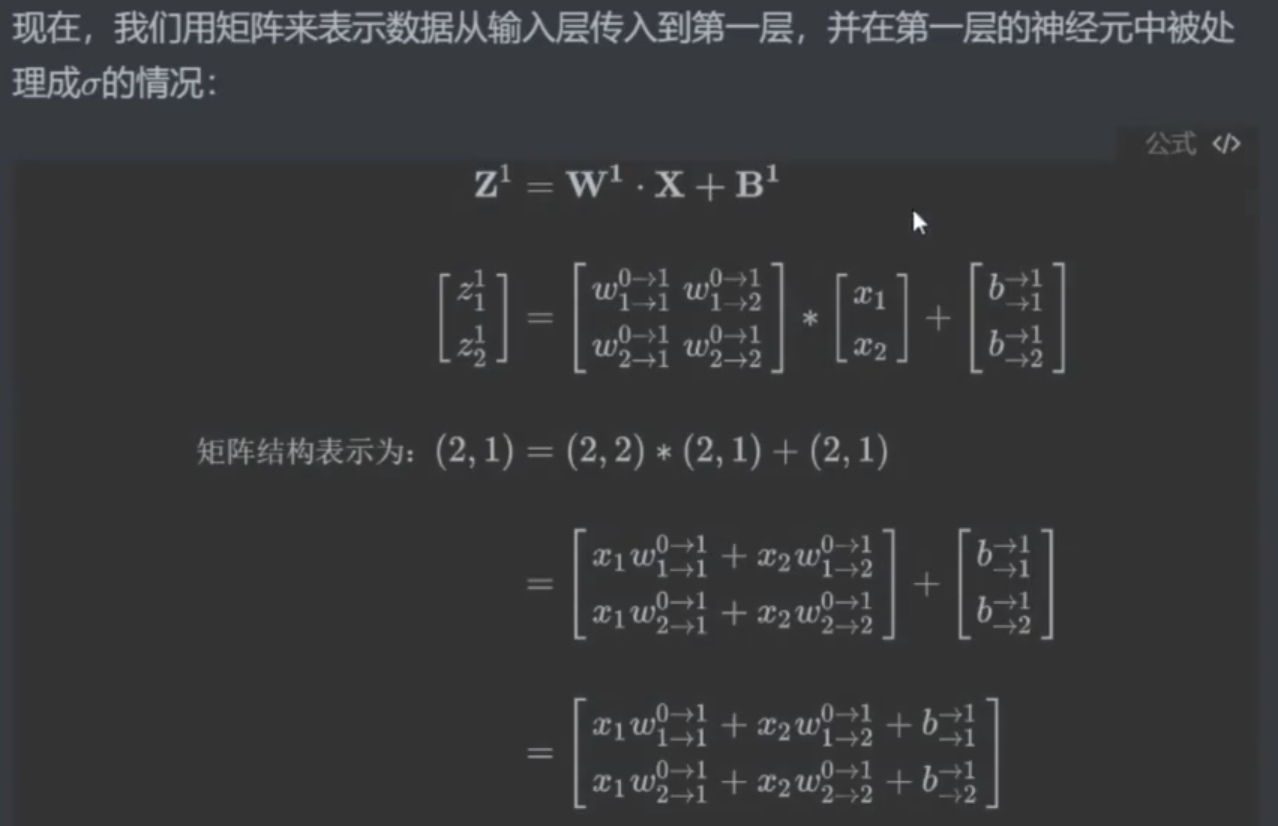
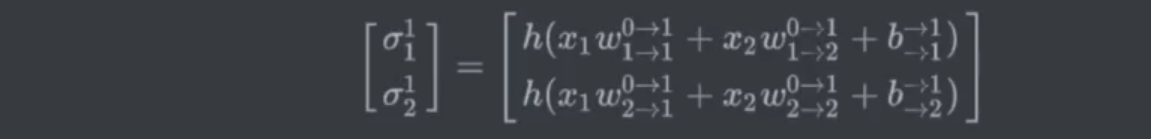

多层神经网络和单层神经网络区别:
- 单层:X * w + b,权重 w:2个,
- 多层:W * X + b,双层时,权重 w :2 * 2 = 4 个,希望 z 是列向量,因为要和神经元从上到下的顺序相匹配,和 特征张量 X 相同
- 特征张量 X、权重 W、常量 b,都需要 转置 [列 * 行]
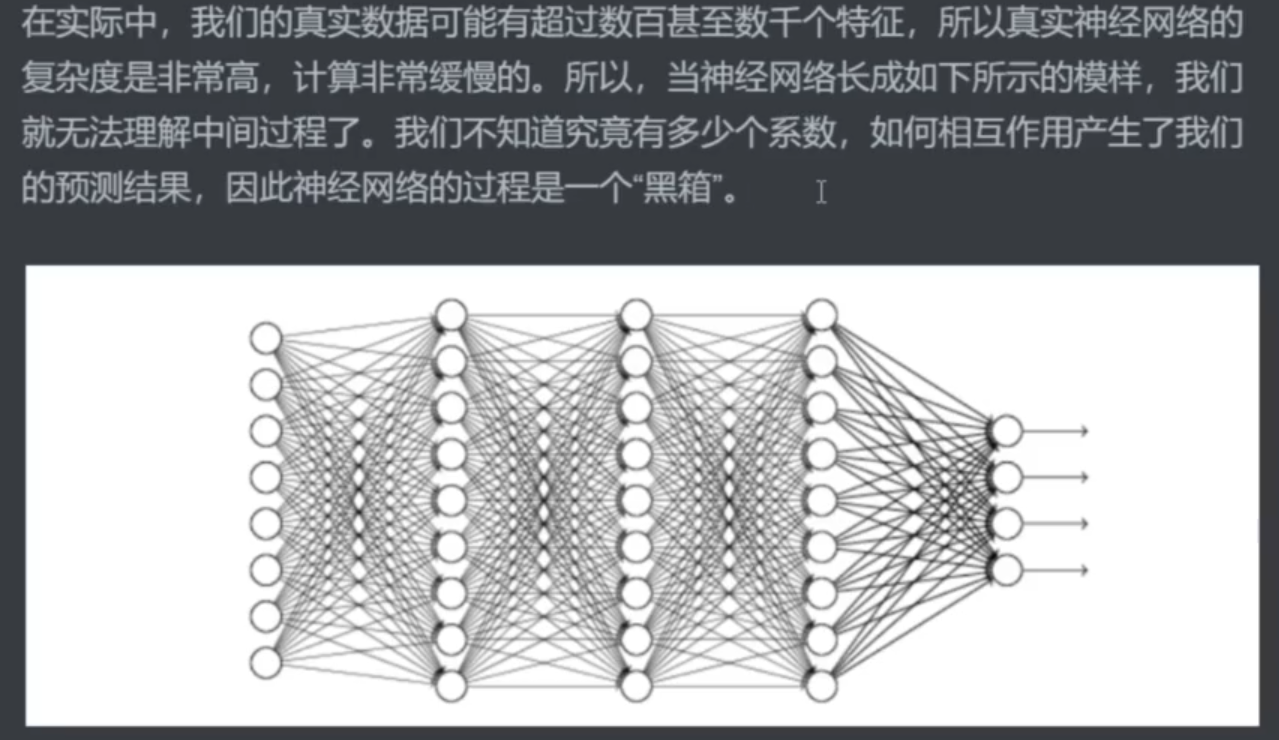
三、探索深度神经网络
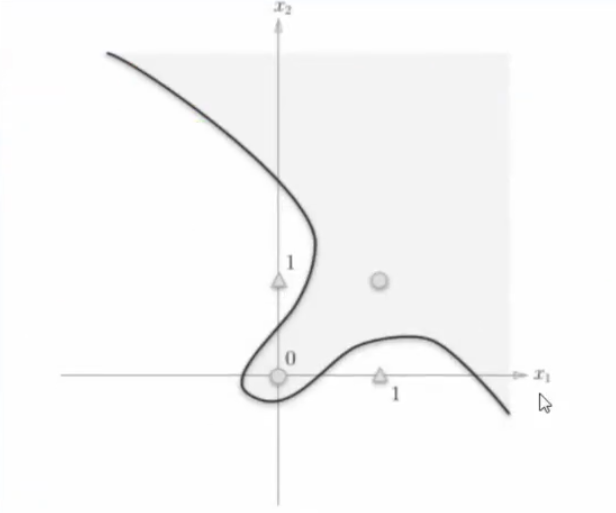
结论:让神经网络可以处理 非线性问题的根源是:激活函数σ
探究原因:
若 激活函数 是一个恒等函数时,最终双层神经网络的结果如图

因此,


四、激活函数
同样是激活函数,为什么中间层叫
h(z),输出层叫g(z)?
- 因为
g(z)与神经网络的效果没有任何关系,它只决定输出什么类型的标签:① 回归问题——恒等函数;② 二分类问题——sigmoid 函数;③ 多分类问题:SoftMax 函数。h(z)直接决定神经网络的效果。- 大部分时候,我们认为同层上的激活函数是一致的。.

五、从0实现深度神经网络的正向传播
正向传播:神经网络从左到右的过程【也叫做向前传播,或者前向传播】

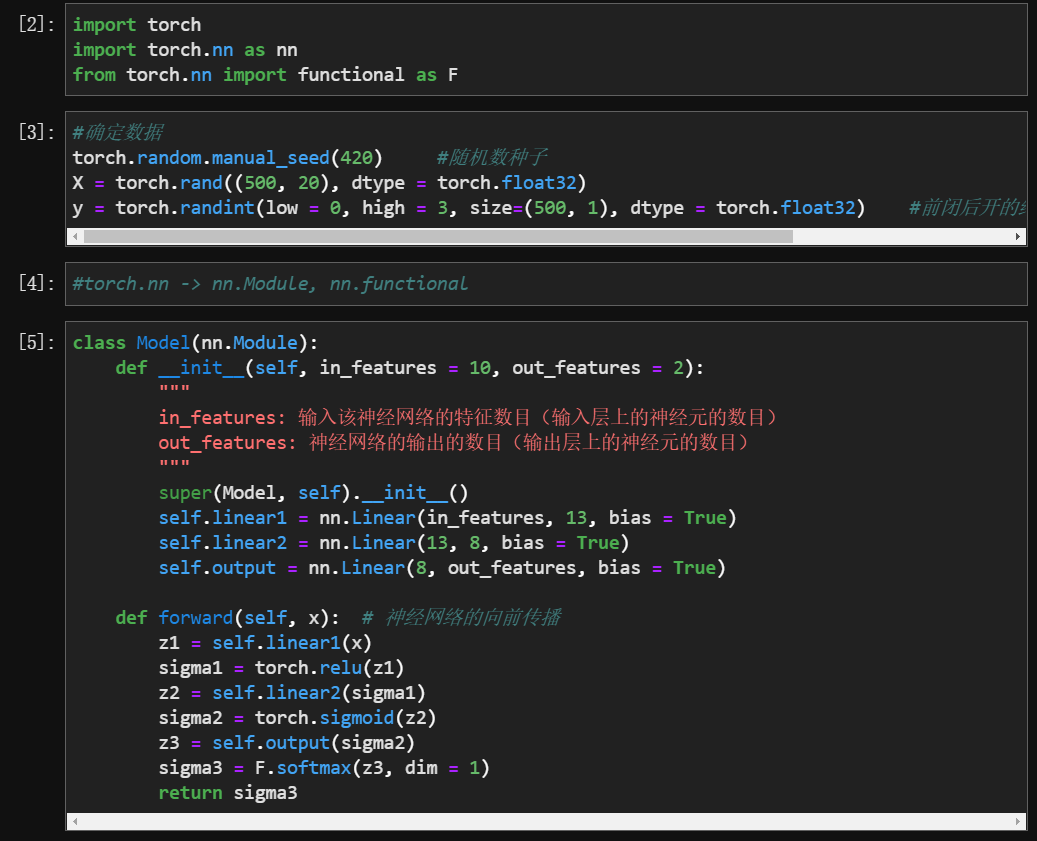
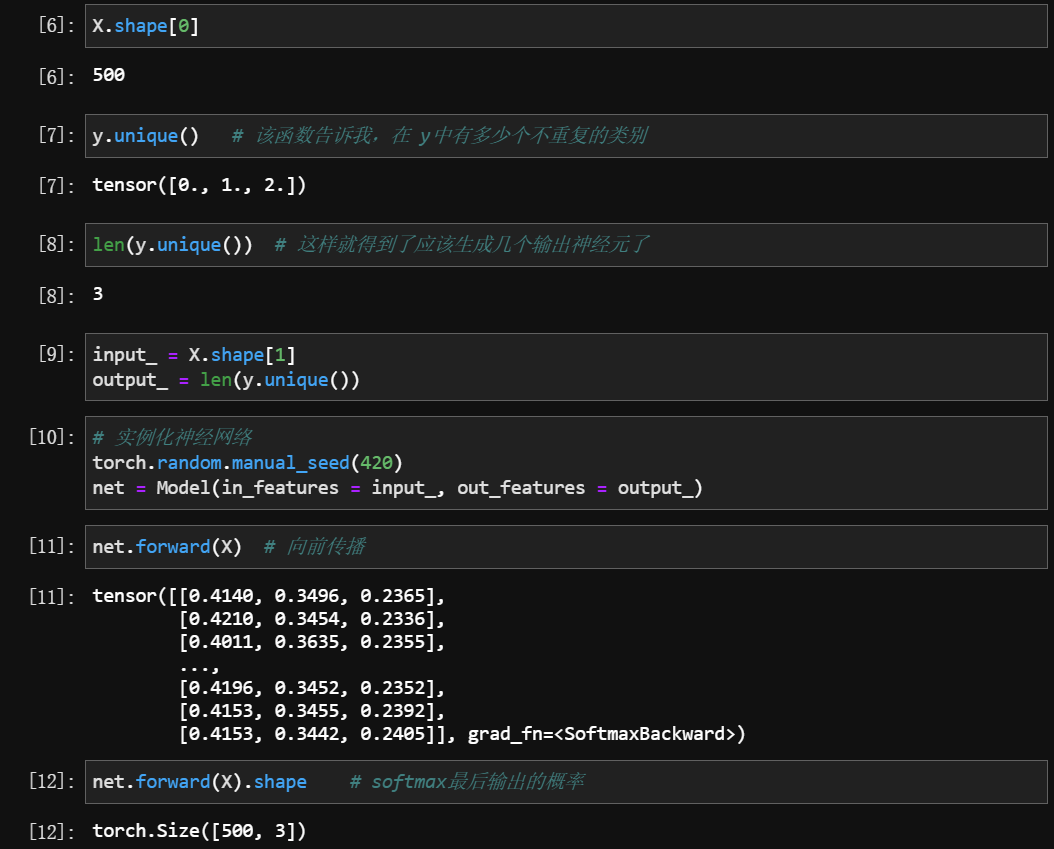
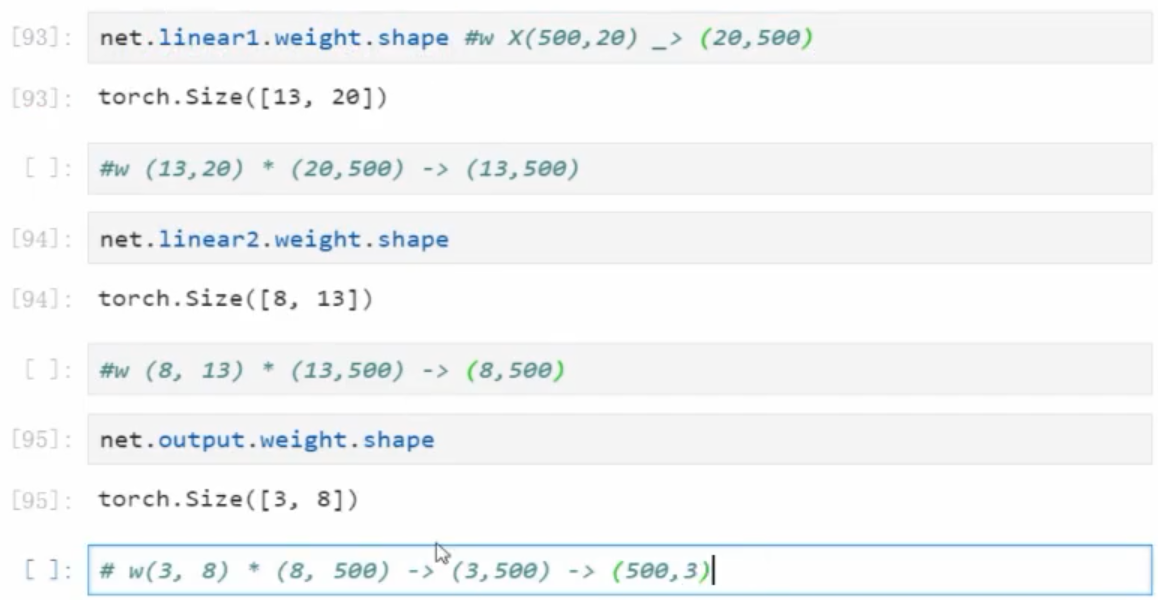
解析神经网络是怎样一步步从 (500, 20) -> (500, 3) 的? 过程中的 w 是怎样的?
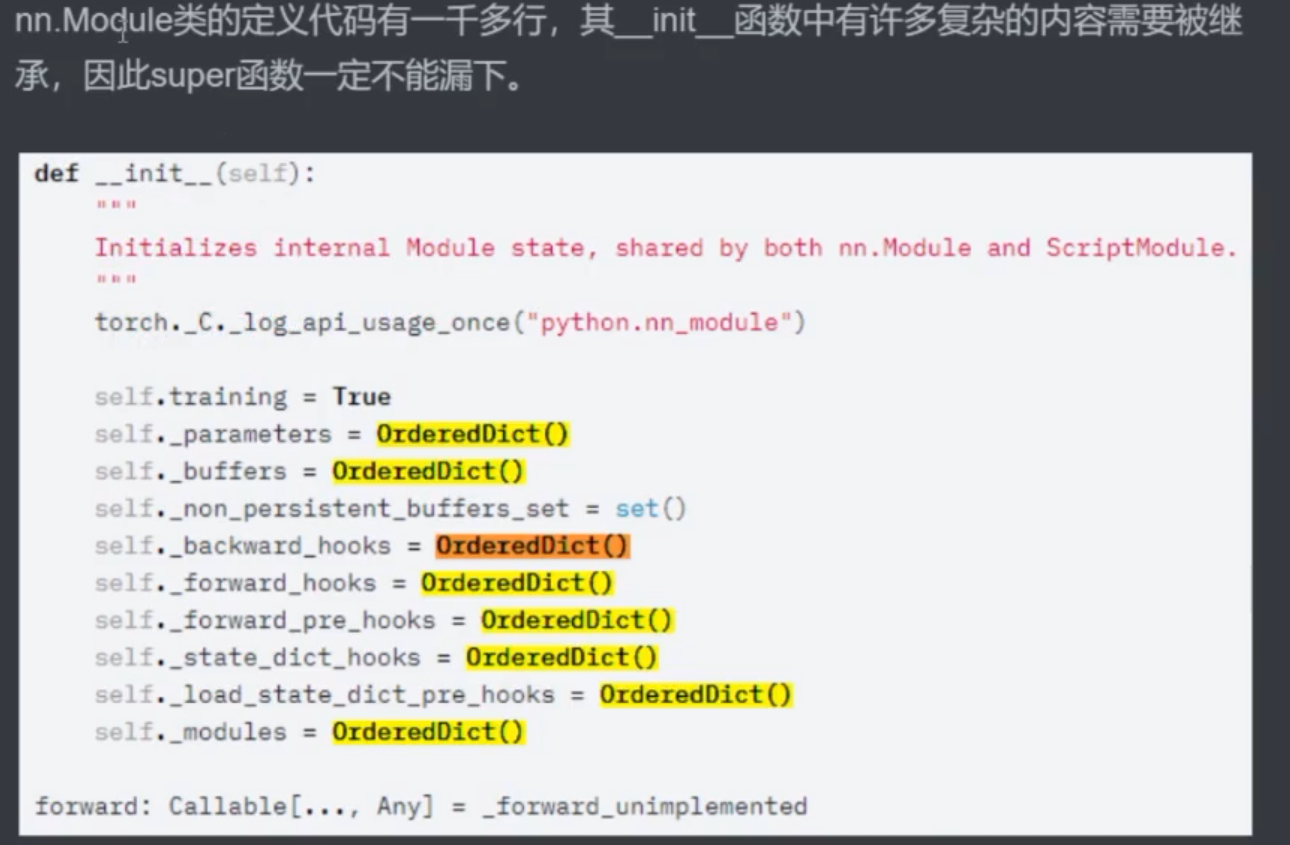
super函数

super(Foochild, self).__init__()解释:找到Foochild的父类,替换掉self的__init__()对象
那么,
super函数什么时候用?就是在继承了父类,并且想要调用 父类中
.__init__()下的函数时需要用到因此,对于任何的神经网络类来说,**只要想要调用
nn.Linear或者其他的nn下的类时, ** 都需要完整的继承nn.Module才可以完整的继承方法:
① 在自定义类时:
class Model(nn.Module)需要继承父类nn.Module② 在自定义类的
__init__()方法下,需要super(Model,self).__init__()
nn.Linear 中的属性和方法
属性的继承

方法的继承
.cuda()

.cup()

.apply()

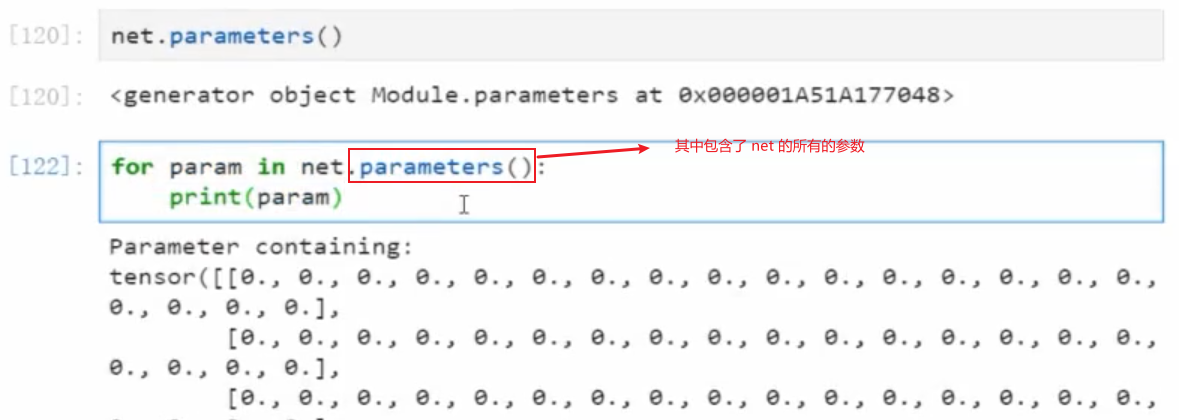
.parameters()