
一、误差平方和SSE
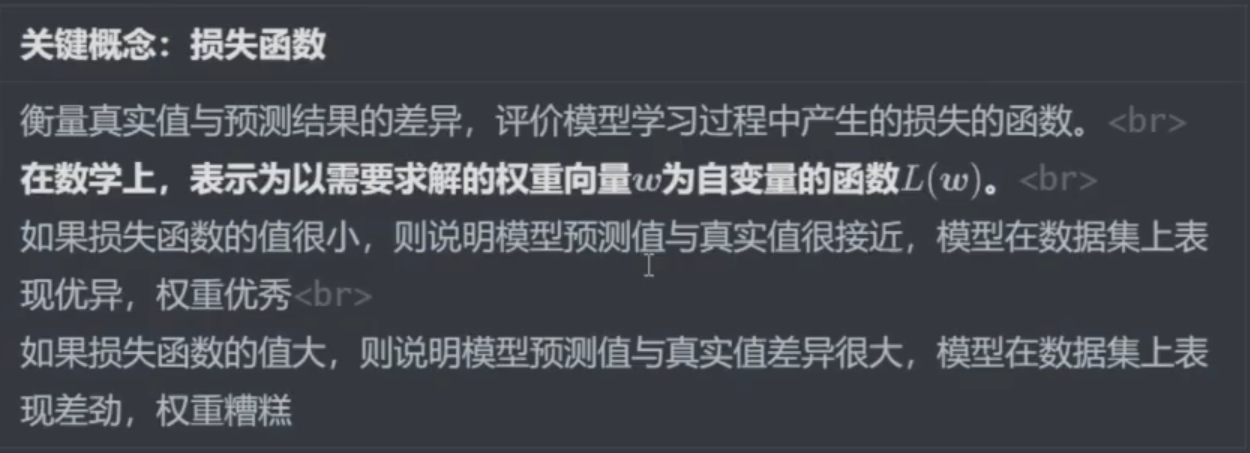

SSE(和方差、误差平方和)

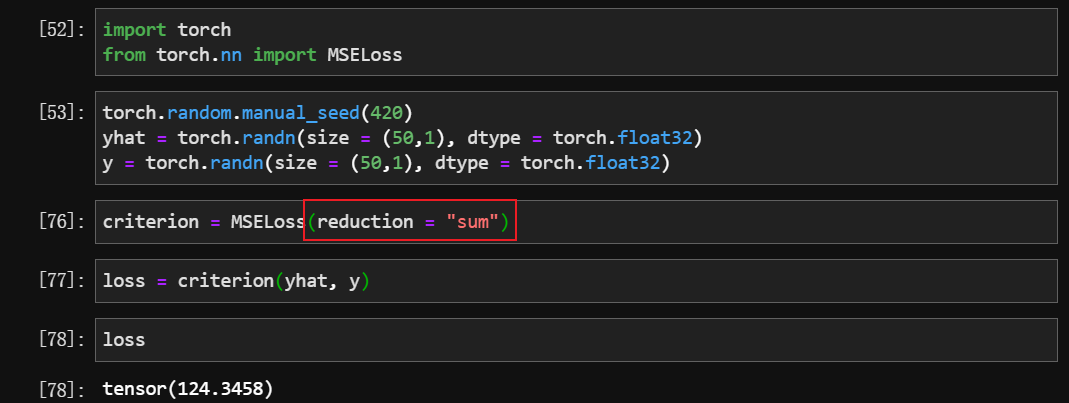
MSE(均方误差)

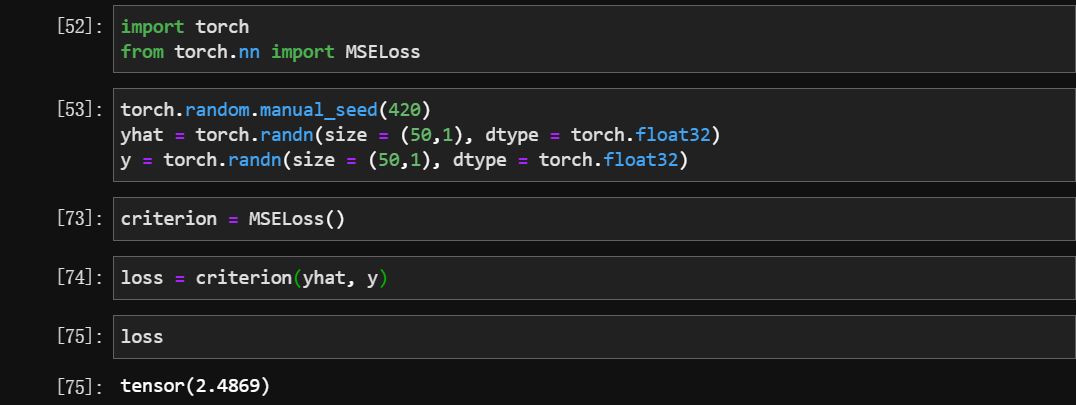
MSELoss()的参数:reduction = “sum” —-> 和方差 SSE
reduction = “mean” —–> 均方差 MSE
reduction = “none” —–> 返回矩阵
二、二分类交叉熵损失的原理与实现
原理
二分类的准确率不作为损失函数


- 自变量是
w那么式子中为什么没有w呢?式子中的
σ代表的是sigma,sigma是激活函数,比如sigmoid 函数ReLU 函数等等,在这些或函数中是包含z,而z中包含w。

- 交叉熵损失函数为什么长这个样子?


手动实现
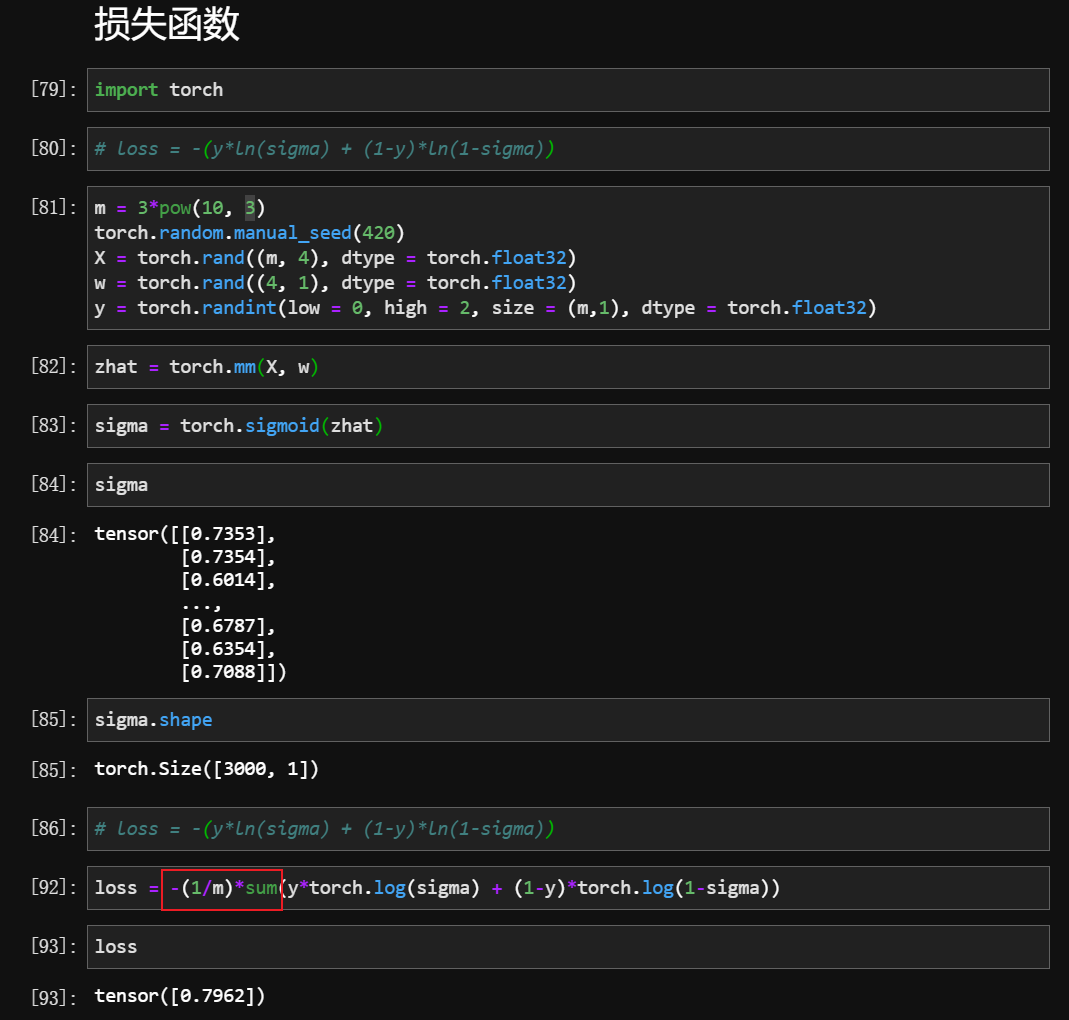
当 X 的数据量增加到 300w 的时候,sum 和 torch.sum 的差别就显现出来了
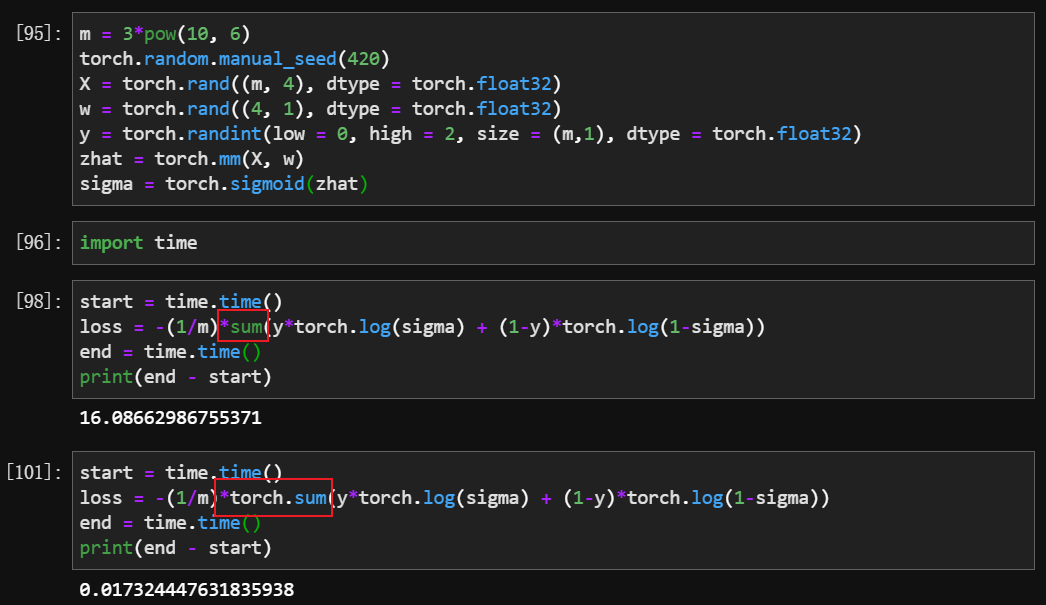
除了普通的
+-*/,其余只要是涉及到 行之间、列之间、矩阵之间的计算,一律用torch.xx
导包实现
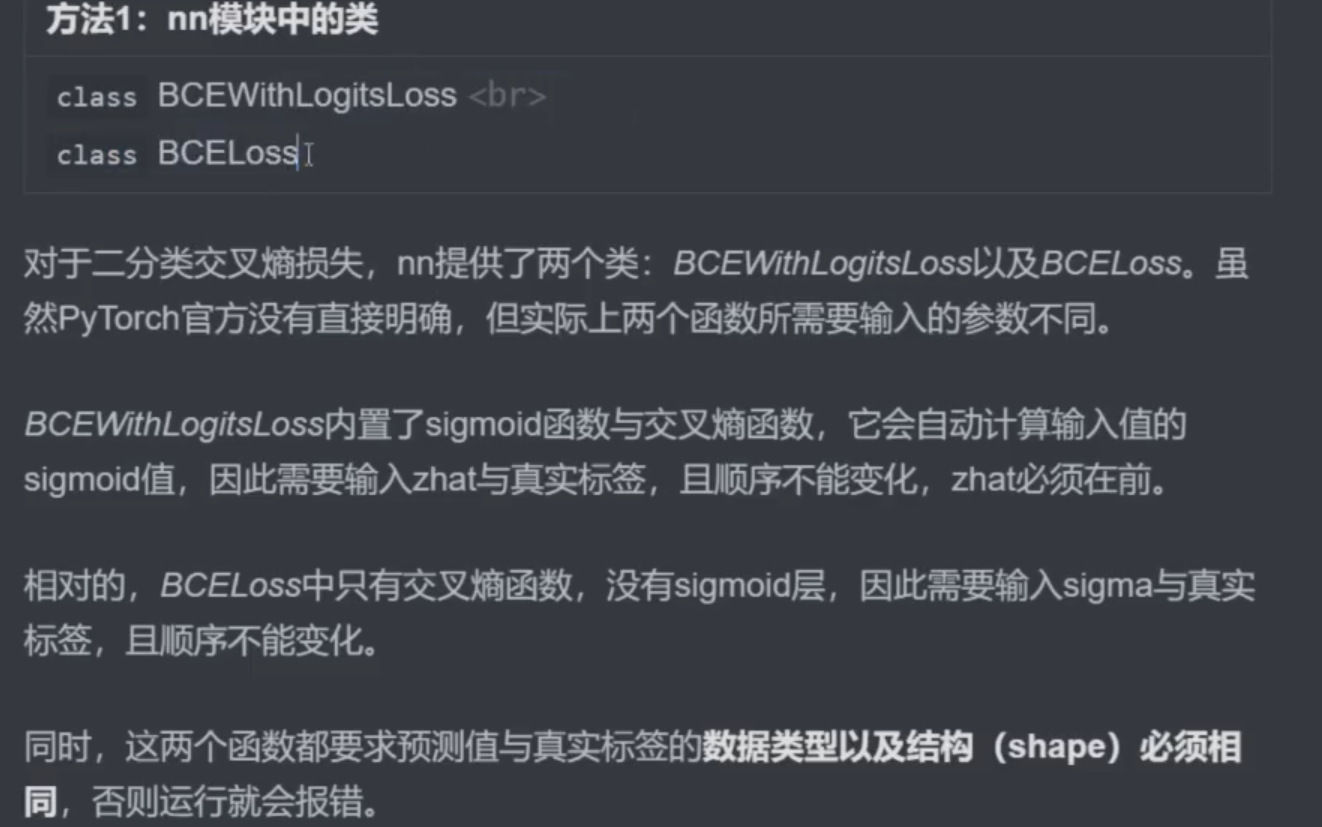
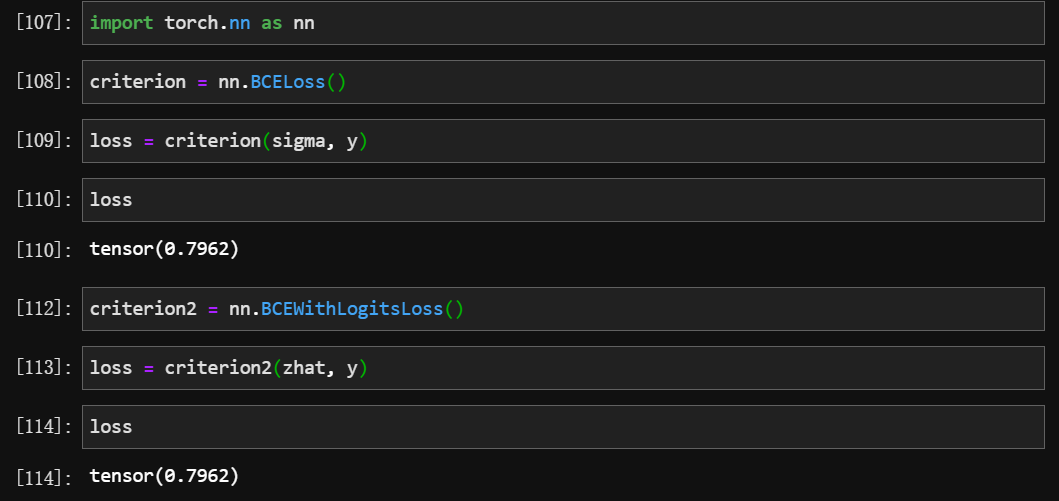
两个函数结果一样,为什么都存在?
sigma存在精度问题,所以nn.BCEWithLogitsLoss()更精准
三、多分类交叉熵损失的原理与实现


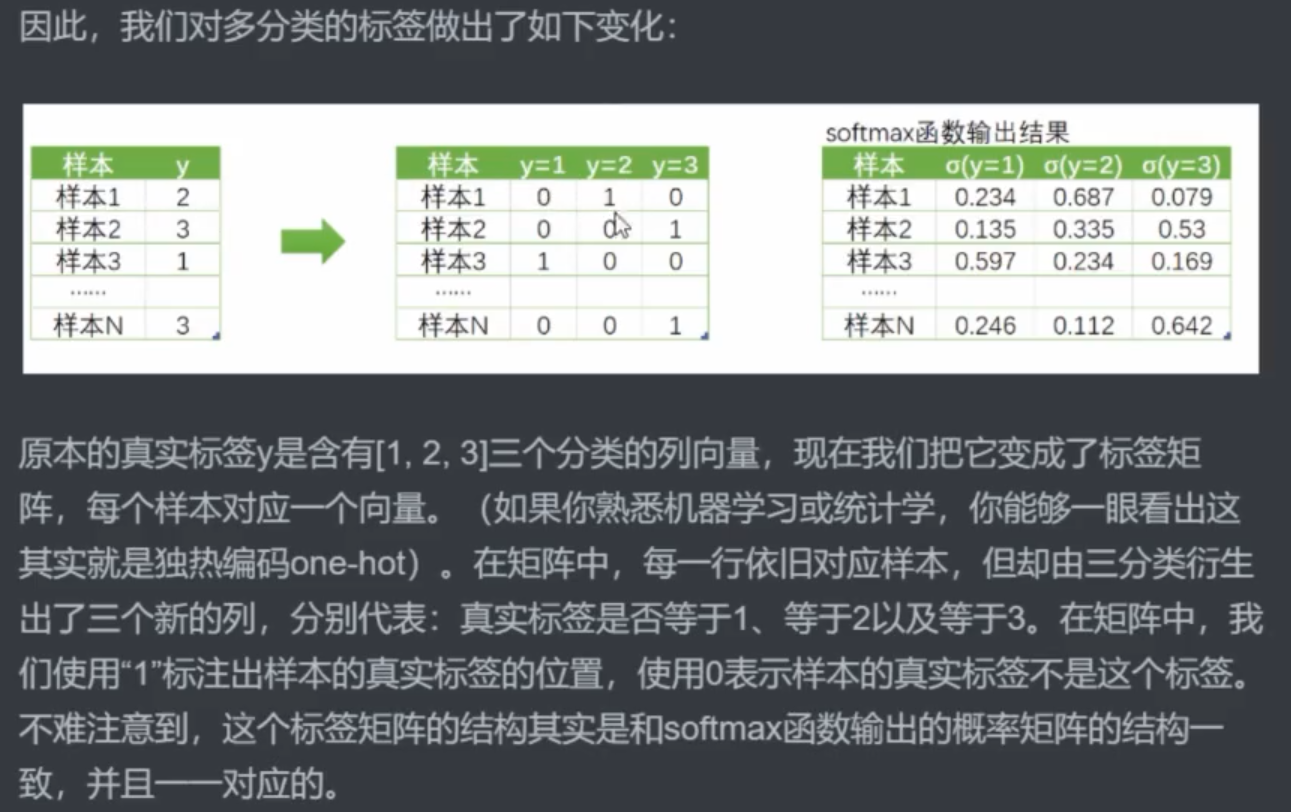

指数不是“真实标签”,而是真实标签的
独热指数



实现方法1
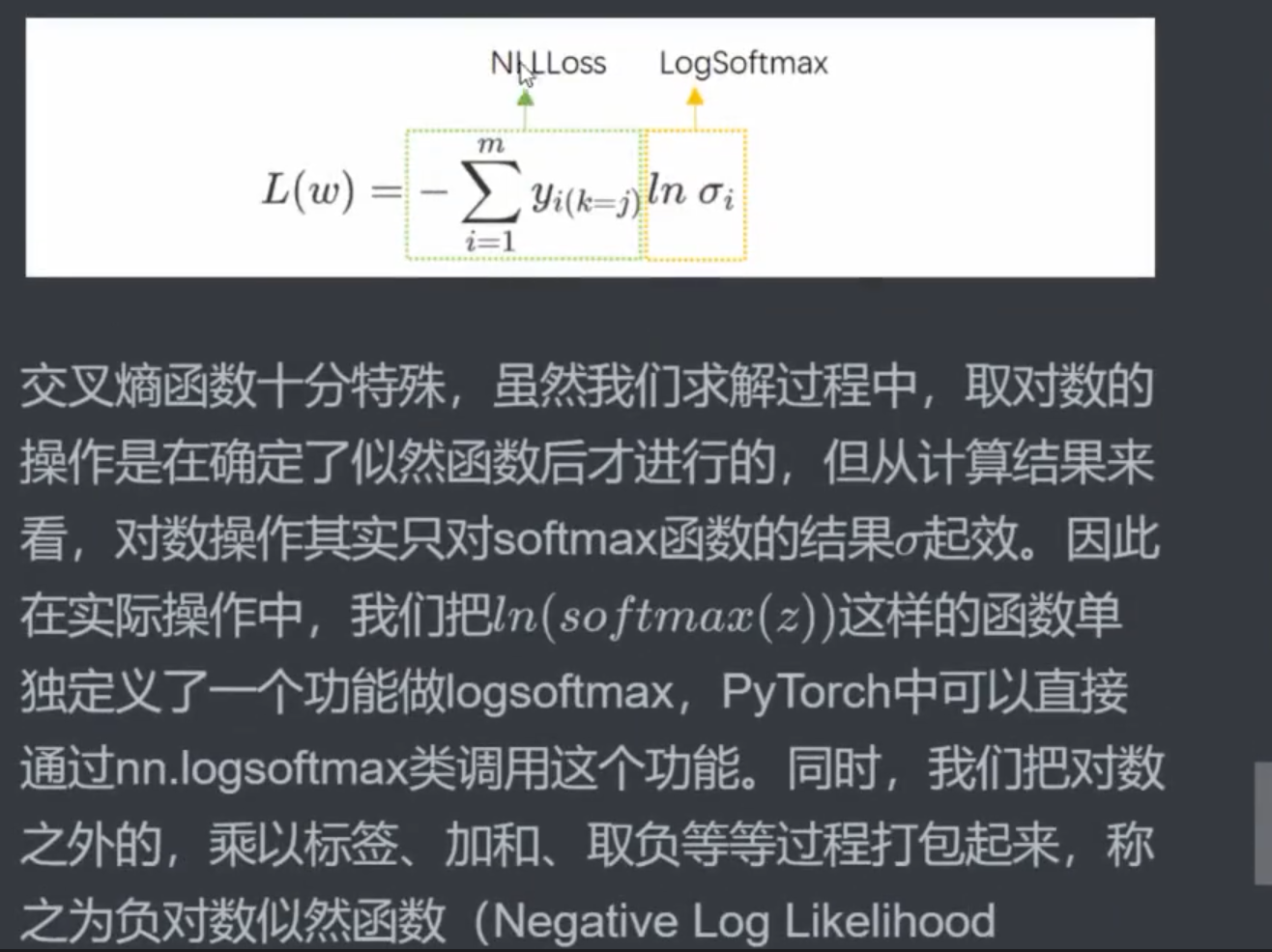
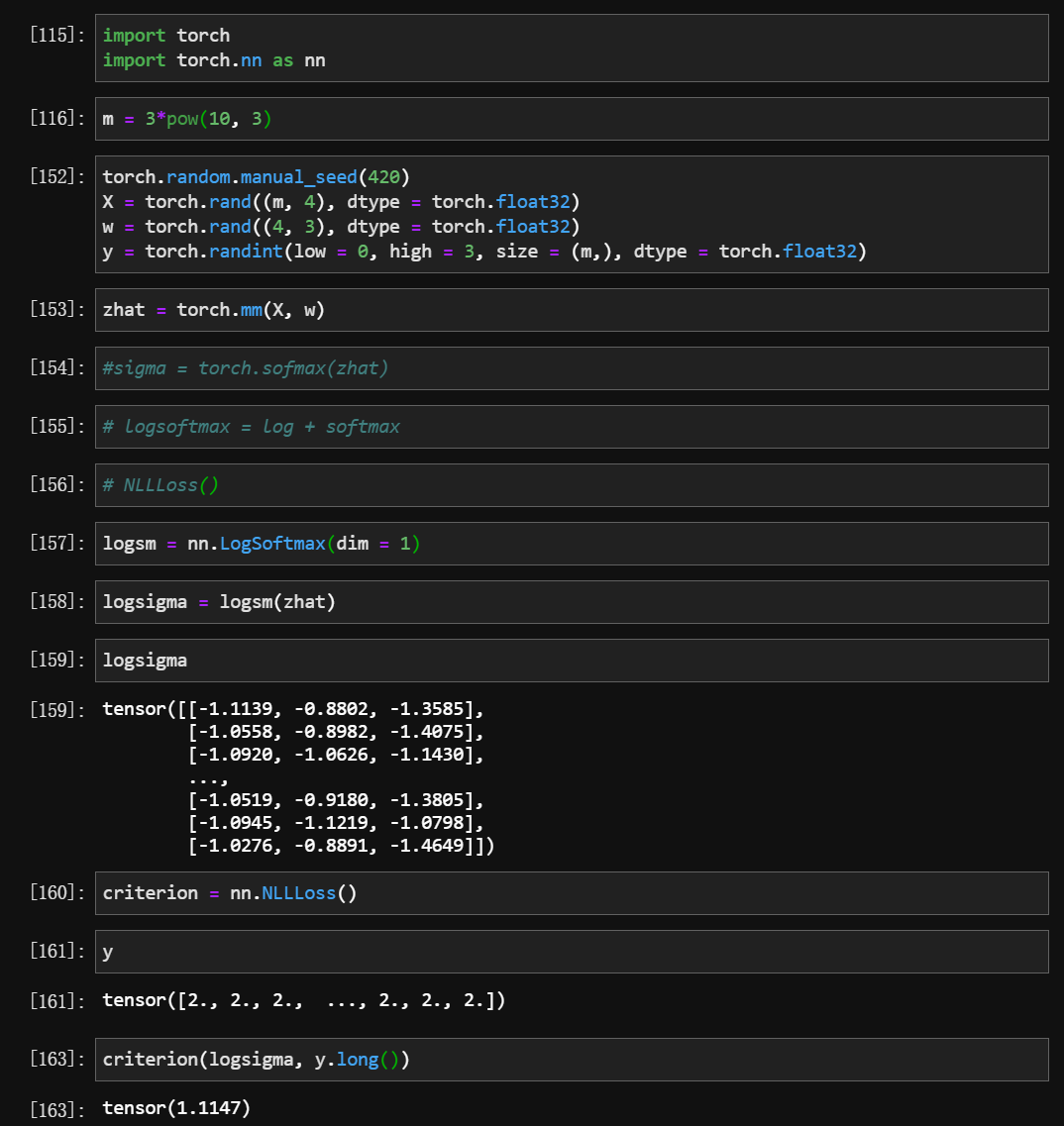
实现方法2
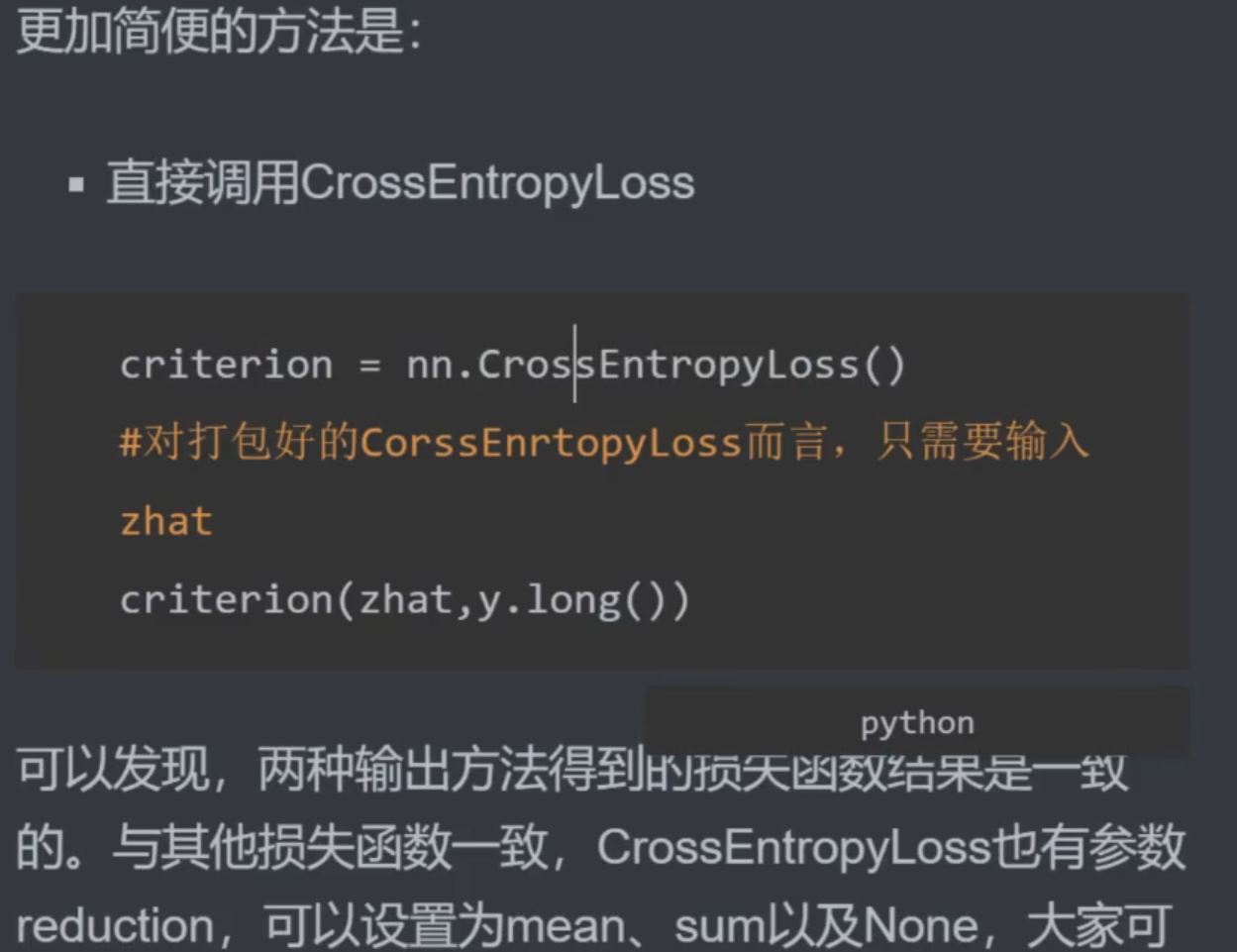

- pytorch 为什么有这么多种办法?


四、总结


