

一、GAN学习与demo实现
GAN全名叫Generative Adversarial Networks,即生成对抗网络,是一种典型的无监督学习方法。在GAN出现之前,一般是用AE(AutoEncoder)的方法来做图像生成的,但是得到的图像比较模糊,效果始终都不理想。直到2014年,Goodfellow大神在NIPS2014会议上首次提出了GAN,使得GAN第一次进入了人们的眼帘并大放异彩,到目前为止GAN的变种已经超过400种,并且CVPR2018收录的论文中有三分之一的主题和GAN有关,可见GAN仍然是当今一大热门研究方向。
1.1 GAN原理简述
GAN的原理表现为对抗哲学,举个例子:警察和小偷的故事,二者满足两个对抗条件:
1.小偷不停的更新偷盗技术以避免被抓。
2.警察不停的发现新的方法与工具来抓小偷。
小偷想要不被抓就要去学习国外的先进偷盗技术,而警察想要抓到小偷就要尽可能的去掌握小偷的偷盗习性。两者在博弈的过程中不断的总结经验、吸取教训,从而都得到稳步的提升,这就是对抗哲学的精髓所在。要注意这个过程一定是一个交替的过程,也就是说两者是交替提升的。想象一下,如果一开始警察就很强大,把所有小偷全部抓光了,那么在没有了小偷之后警察也不会再去学习新的知识了,侦查能力就得不到提升。反之亦然,如果小偷刚开始就很强大,警察根本抓不到小偷,那么小偷也没有动力学习新的偷盗技术了,小偷的偷盗能力也得不到提升,这就好比在训练神经网络时出现了梯度消失一样。所以一定是一个动态博弈的过程,这也是GAN最显著的特性之一。
在讲完了警察与小偷的故事之后,我们引入今天的主人公——GAN。
然而训练生成器才是GAN的精华,这里发生了前所未有的训练模式,虽然生成器生成的数据我们都知道它是假的, 但是在这里我们故意用真标签去诱导判别器给出变成真数据的梯度下降方向,所以判别器才会教生成器去生成更真的数据。 这就是GAN的奥秘了。
1.2 实践
1 | import torch |
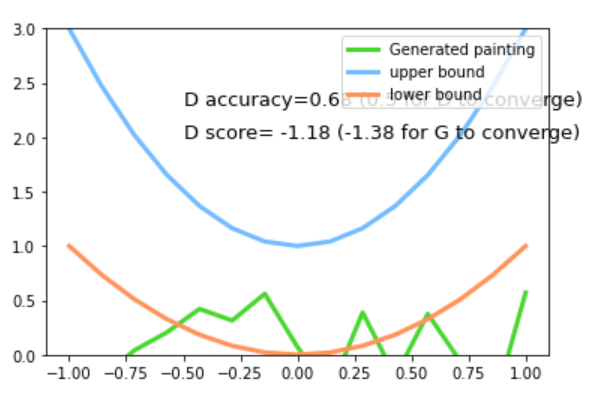
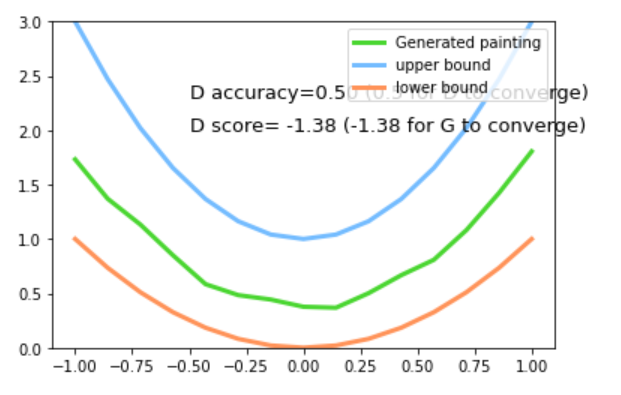
1.3 代码理解
上面代码只是跟着视频瞎敲了一遍,还没有完全弄明白

- 生成器初始化:
nn.Linear()里的数怎么定的?
猜测:经验之谈,含义是上一层神经元个数和这一层神经元个数。
- 反馈?判别器怎么告诉真假?
猜测:通过反向传播更新参数。
二、问题汇总
问题2.1:不调用GPU,只用CPU算
1 | 测试:如果好用会返回 True |
问题2.2:.pkl文件是什么
1)python中有一种存储方式,可以存储为.pkl文件。
2)该存储方式,可以将python项目过程中用到的一些暂时变量、或者需要提取、暂存的字符串、列表、字典等数据保存起来。
3)保存方式就是保存到创建的.pkl文件里面。
4)然后需要使用的时候再 open,load。
问题2.3:只显示 <Figure size 640x480 with 1 Axes> 而没有生成图片
解决方法:可以在前面添加plt.figure()创建画布。
或者
导入库之后添加以下代码即可
1 | %matplotlib inline |
是在使用 jupyter notebook 或者 jupyter qtconsole的时候,才会经常用到 %matplotlib,也就是说那一份代码可能就是别人使用 jupyter notebook 或者 jupyter qtconsole进行编辑的。
而 %matplotlib具体作用是当你调用 matplotlib.pyplot 的绘图函数 plot() 进行绘图的时候,或者生成一个figure画布的时候,可以直接在你的python console里面生成图像。
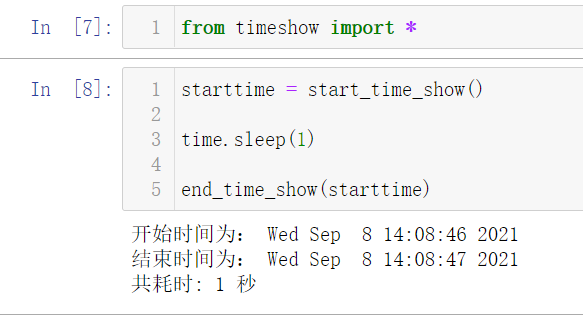
问题2.4:计算程序耗时
1 | import datetime |

封装版:
timeshow.py
1 | import datetime |
使用
1 | from timeshow import * |
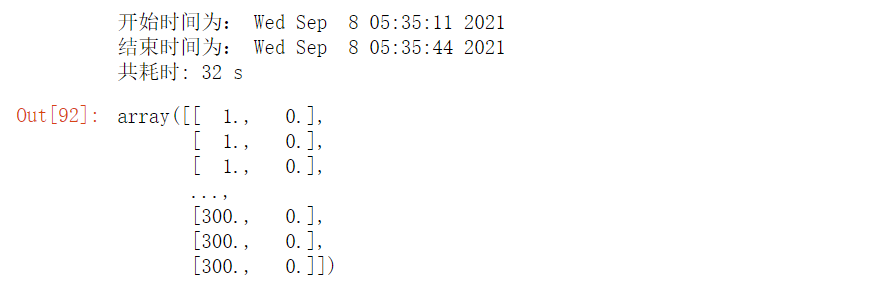
问题2.5:读取excecl速度太慢
实测读取 1000 个Sheet 的 data.xls文件,每个Sheet需要32秒,太慢了

方法一:openpyxl(听说读取速度很快)
注意:不支持xls文件,支持xlsx
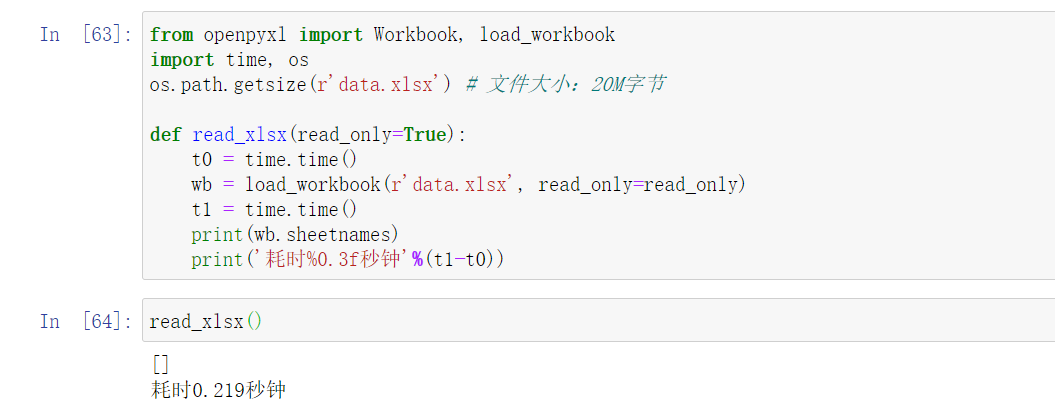
读取不到我需要的文件
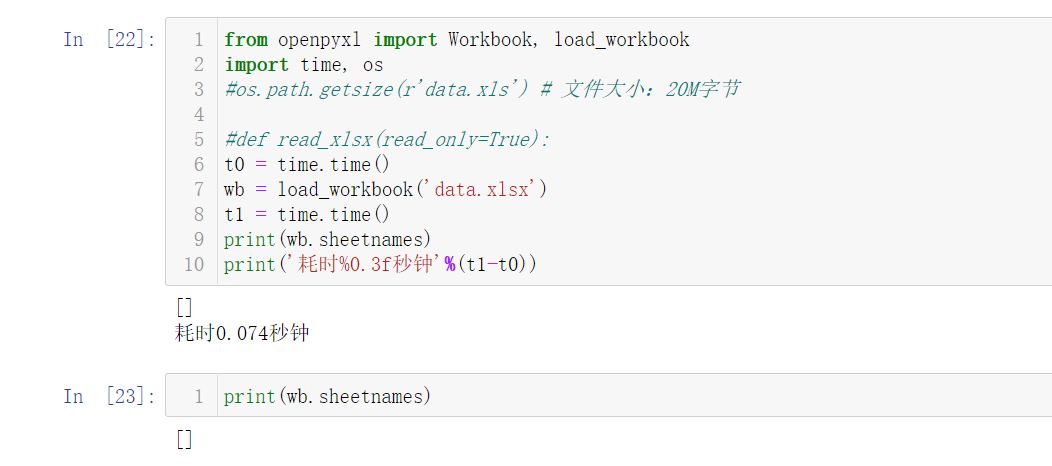
但是,随便创建了个文件,就可以读取
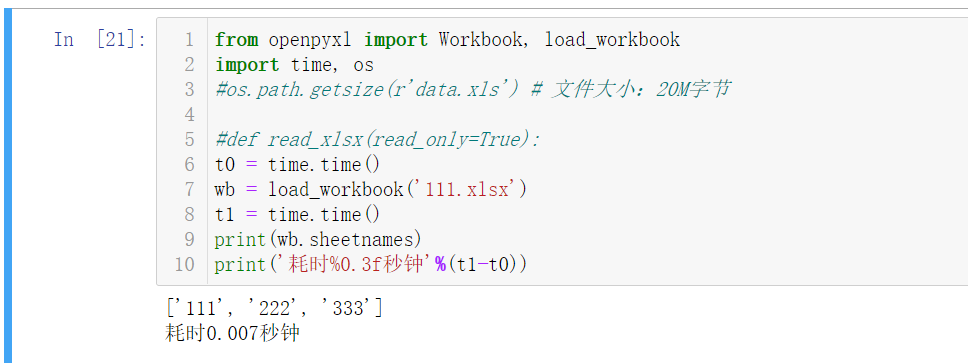
不知道为啥
换一种方法
方法二:xlrd
读取方法:
1 | import xlrd |
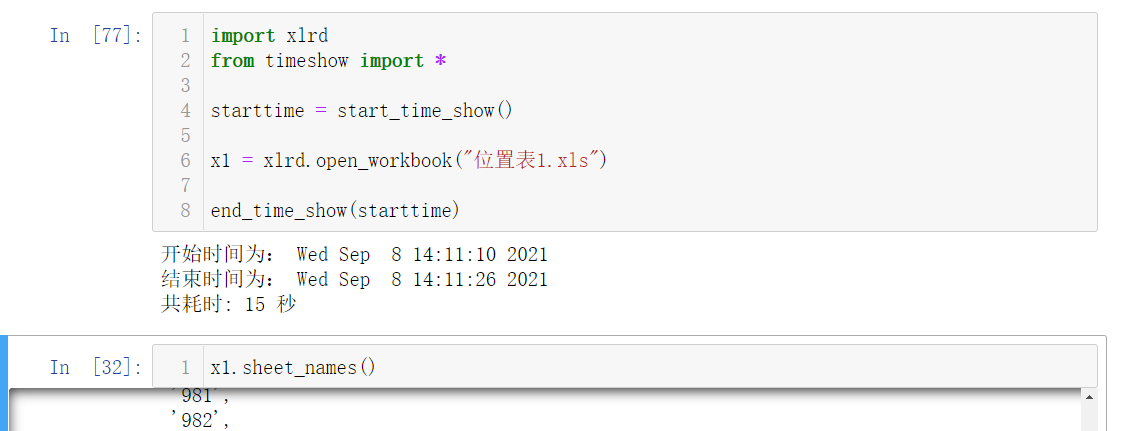
获取sheet
1 | # 获取所有 Sheet 的名字 |
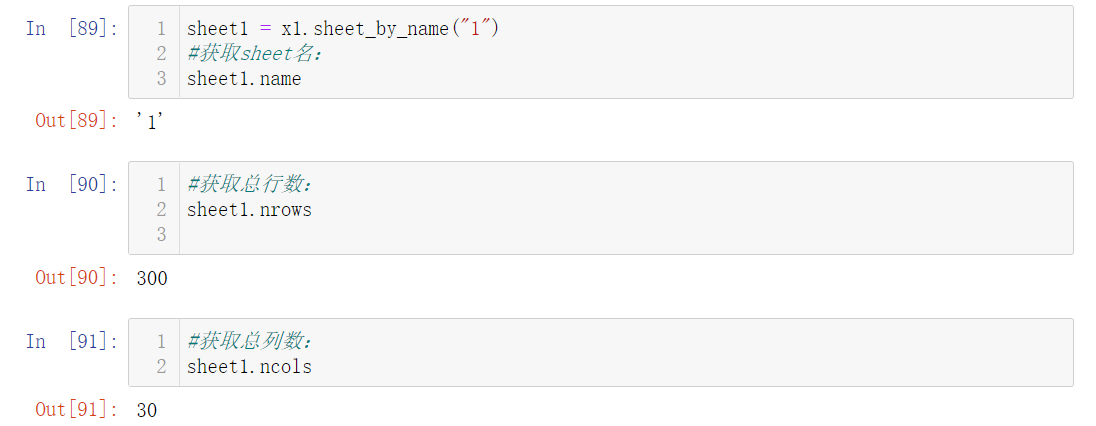
获取sheet的数据
1 | sheet1 = x1.sheet_by_name("1") |
问题2.6:Sheet太多,如何快速跳转


问题2.7:numpy显示完整数据
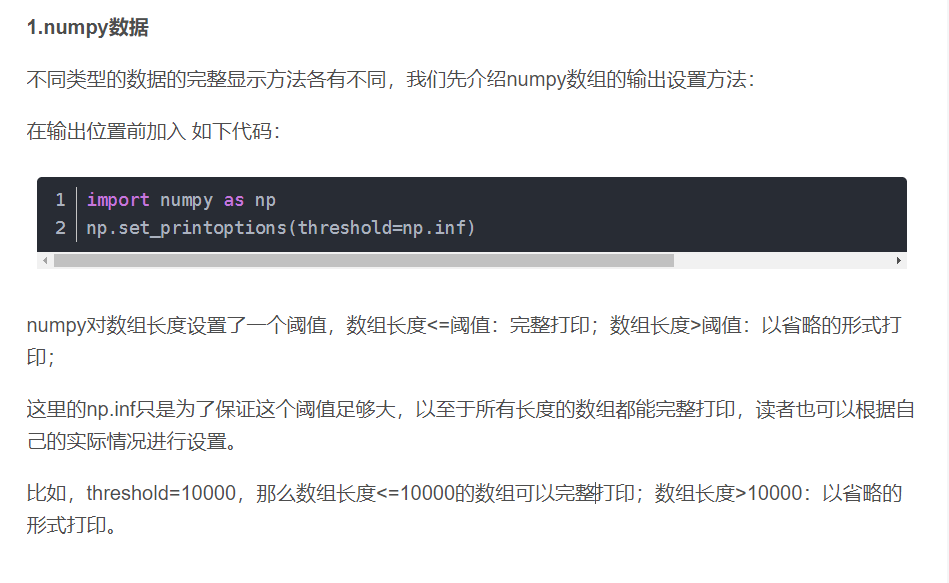
1 | import numpy as np |
问题2.8:nn.Linear(x, y) ,x和y怎么确定?
经验
问题2.9:数据量不匹配?
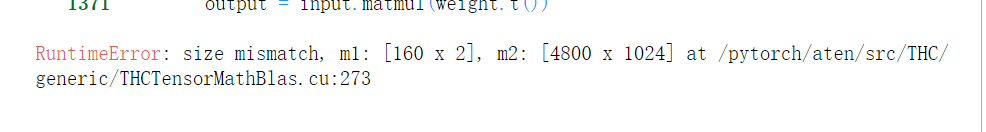
问题2.10:smote 算法
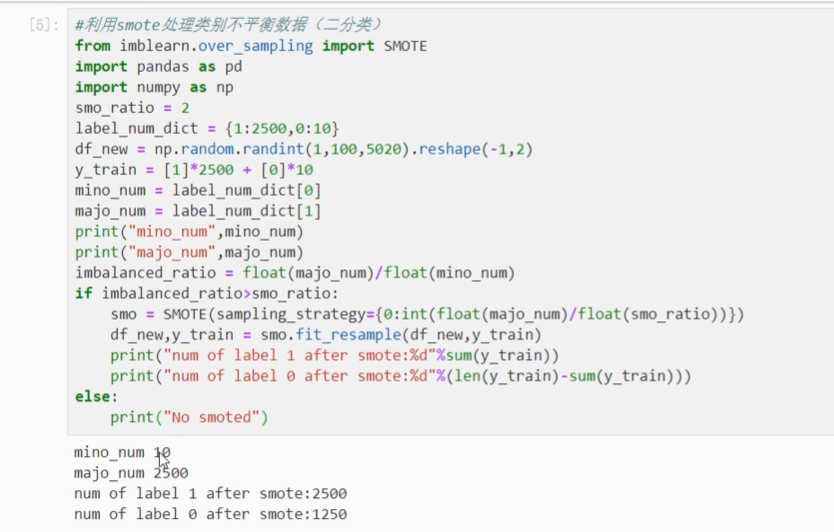
SMOTE理解:主要是针对正负样本不均问题的解决方案,比如正样本2500个,负样本10个,这样可能会使最后结果太偏向正样本,这时就可以用SMOTE算法来扩充负样本个数,扩充的过程就是在任意两个样本之间取中点为新样本。

1 | smo = SMOTE(sampling_strategy={0:int(float(majo_num)/float(smo_ratio))}) |
理解:为了解决正负样本不匹配的问题,生成一些假的 ”少量样本类“ 的量
1 | from imblearn.over_sampling import SMOTE |
花费时间长原因:
没有理清思路,如果“ 找出输入输出(本质),然后替换 “ 会更加高效。
