

一、中期复习
神经网络三板斧: 正向传播,优化网络,反向传播
简述神经网络的过程:
如果对一个 n 大小输入的向量,将其变换为m大小的向量,需要一个 m*n 大小的矩阵来描述这种线性变换,权重是一个经过一定随机初始化(比如权重的每个分量值都初始化为标准正态分布),权重在神经网络的训练过程中会向着让模型更好地符合数据分布的方向变化,这个过程称之为模型优化(Optimization)。权重除外,我们一般还会给线性变换之后的输出统一加一个可训练的参数,这个参数是标量,即为一个实数,我们称这个参数为偏置(Bias)。
线性层:
nn.Linear(in_features, out_features, bias=True)全连接层:下一层神经网络的每个值都与前一层神经网络的每个值相关联,我们称这种神经网络连接方式为全连接层。
多层感知机(MLP)和神经网络的关系:MLP这个术语属于历史遗留的产物,现在我们一般就说神经网络,以及深度神经网络,前者代表带一个隐藏层的两层神经网络,也是EasyPR目前使用的识别网络,后者指深度学习的网络。值得注意的是,虽然叫“多层”,MLP一般都指的是两层(带一个隐藏层的)神经网络。
张量的逐点计算: 对输入张量的每一个分量进行相同的运算,比如都乘以一个数麻醉后输出一个与输入张量形状相同的心张量
正向传播:
forward,激活函数(输入层和隐藏层之间):所谓激活函数,就是对一类非线性函数的统称,通过对线性变换中输出结果的每个分量都应用激活函数,可以输出非线性的结果。神经元对线性组合输出的结果做一个非线性的变换,正是因为有了非线性变换,才能使得整个神经网络的结果是非线性的。
nn.ReLU():实质是max(0,z)。如果输入大于0,输出它本身;如果输入小于等于0,输出0。**特点:①速度快 ②导数在x趋向无穷大时恒为1 **nn.Sigmoid(): 将结果映射到(0,1)之间。当输入为0时,结果为0.5,一般用于二分类。nn.Tanh():将结果映射到(-1,1)之间。当输入为0时,结果为0。实际上它可以看做Sigmoid函数的2倍减一。
激活函数(隐藏层和输出层之间):
- 回归问题:做预测,由于对预测值没有限制,直接使用全连接线性输出作为最终的预测,因此不需要激活函数。
- 二分类问题:一般用
Sigmoid 函数,使输出在 0~1 之间,表示概率。 - 多分类问题:
Softmax 函数:首先对线性变换的结果所有分量取指数函数,然后对每个分量分别除以所有分量的和,这样可以保证Softmax函数的输出求和为1,即所有分量的概率的和为1。由于线性变换的某一个分量可能非常大,计算指数函数时候会超出浮点数的表示范围,为了能够计算这种情况下的Softmax函数输出,一般在计算Softmax函数之前会对所有的分量统一减去这些分量中最大的值,这样可以保持Softmax函数值不变,而且可以避免在计算指数函数的时候因中间结果过大超出表示范围的问题。
优化:
torch.optim.Adam()反向传播:
loss.backwardbatch:
epoch:
二、疑问解答
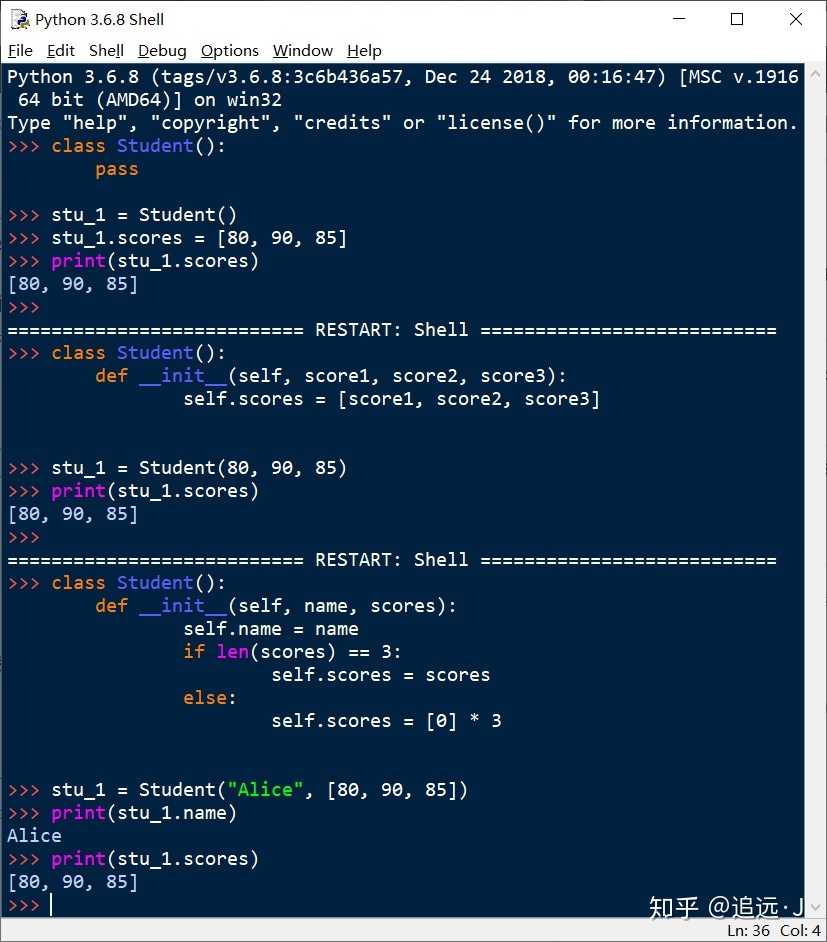
2.1 def __init__(self) 的含义:
Student类,创建一个实例,实例的属性可以在类中self.xxx 来定义。
2.2 线性层中的 in_features 和 out_features 的意义?数值怎么确定?
2.3 w 怎么来的?
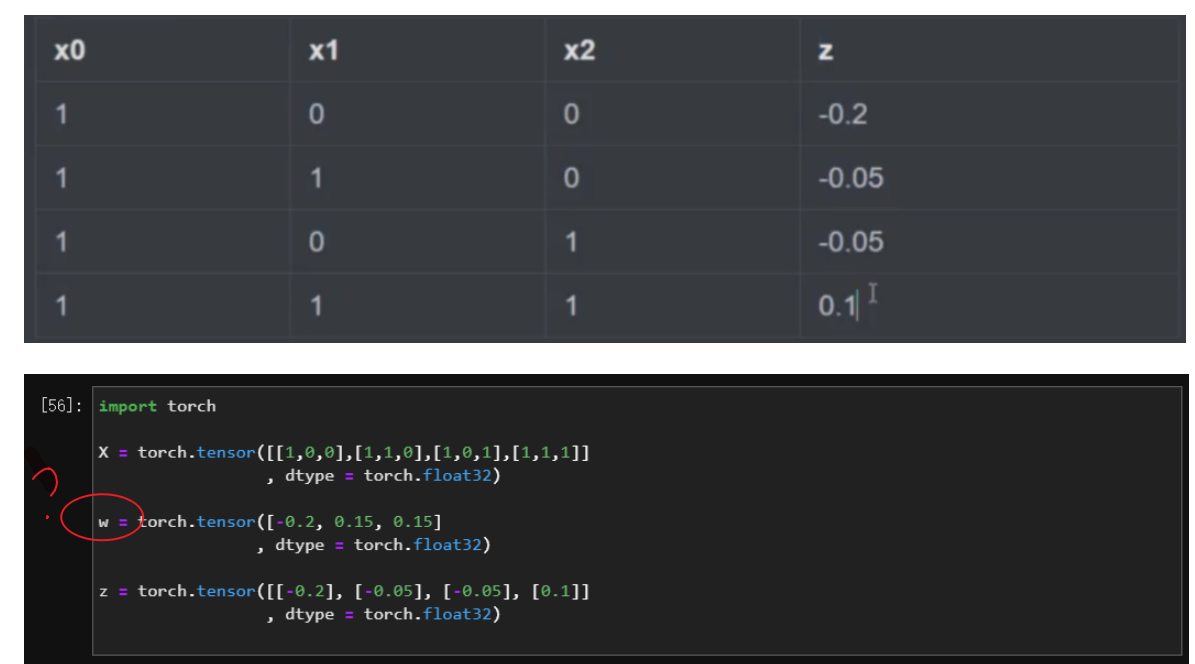
答:菜菜老师原话:“这里我们随便写一个w,当然我这里的w是我试好的”
- 为什么
w是大小为3的向量?
答:首先要知道,向量是列向量,输入神经元个数为3,输出神经元个数为1,因此需要1*3的矩阵。
